This document discusses outlier handling techniques in data science. It begins by defining outliers as values that are much smaller or larger than most other values in a dataset. It then provides examples of how outliers can affect calculations of mean, median, and mode using a sample dataset. The document goes on to describe common outlier handling methods like median replacement, upper value capping, and lower value capping. It includes Python code snippets demonstrating how to implement these techniques. It closes by noting that outlier treatment should be driven by business needs and available data.

![j
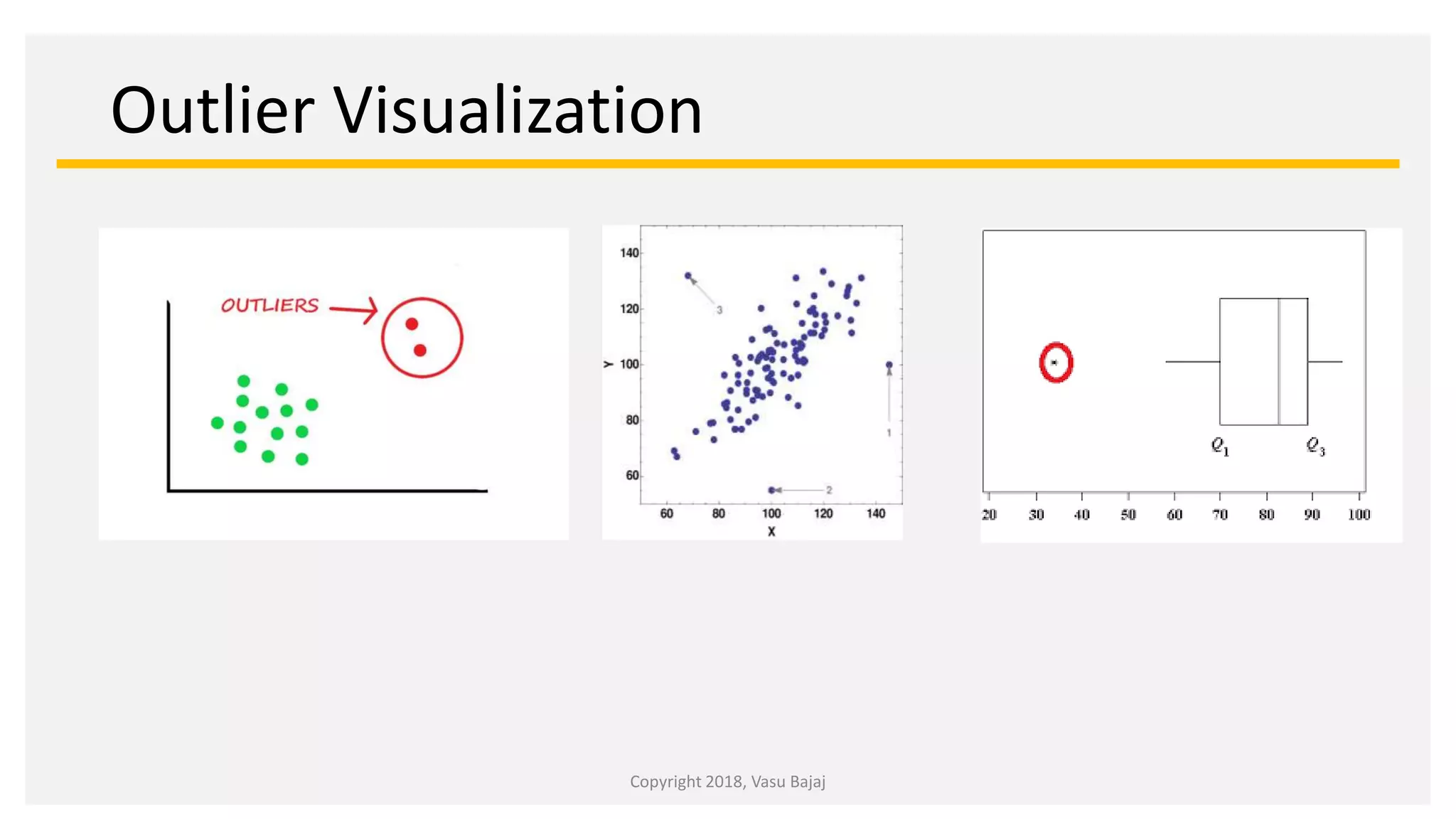
Outliers
Copyright 2018, Vasu Bajaj
Values which are either smaller or greater that the majority of samples in a population.
Lets talk about the central tendency measurement [ Mean, Median, Mode ].
Lets assume a sample A = [1,1,2,3,4,5,6,7]
Mode(A): (Most frequent sample) 1
Mean(A): (Avergae) Sum(A)/n-1 = 30/8 = 3.7
Median(A): (Sort A and then take (n/2+1)th term if odd and (n/2) +(n/2+1)th term
if even and divide by 2)(3+4/2) = 3.5
Lets add an outlier [100] to the sample A
Hence, new sample becomes A = [1,1,2,3,4,5,6,7,100]
Mode(A): 1
Mean(A): 130/9 ~14
Median(A): 4
What are outliers and why do they matter?](https://image.slidesharecdn.com/datascience-outlierhandling-210216092158/75/Data-science-Handling-Outliers-2-2048.jpg)

![j
Outlier Handling - Median Replacement
Copyright 2018, Vasu Bajaj
Imputation is nothing but deleting the outlier records
Normally, records mean +/- 1.5*IQ are considered as outliers
But, please note the interval 1.5*IQ is entirely use case and business
Case driven
#Python Code Snipppet
lower_limit = df['col'].mean() - 1.5* df['col'].mean(sd)
upper_limit = df['col'].mean() + 1.5* df['col'].mean(sd)
#Median Replacement
df['col'] = np.where(df.col > upper_limit, df['col'].median(),
(np.where(df.GRE < lower_limit, df['col'].median(), df.col)))](https://image.slidesharecdn.com/datascience-outlierhandling-210216092158/75/Data-science-Handling-Outliers-5-2048.jpg)
![j
Outlier Handling - Upper Capping
Copyright 2018, Vasu Bajaj
#Python Code Snipppet
lower_limit = df['col'].mean() - 1.5* df['col'].mean(sd)
upper_limit = df['col'].mean() + 1.5* df['col'].mean(sd)
#Upper Capping:
df['col'] = np.where(df.col > upper_limit, upper_limit,
(np.where(df.col < lower_limit, lower_limit, df.col)))
#Lower Capping:
df['col'] = np.where(df.col > upper_limit, upper_limit,
(np.where(df.col < lower_limit, lower_limit, df.col)))](https://image.slidesharecdn.com/datascience-outlierhandling-210216092158/75/Data-science-Handling-Outliers-6-2048.jpg)
![j
Outlier Handling - Lower Capping
Copyright 2018, Vasu Bajaj
#Python Code Snipppet
lower_limit = df['col'].mean() - 1.5* df['col'].mean(sd)
upper_limit = df['col'].mean() + 1.5* df['col'].mean(sd)
#Upper Capping:
df['col'] = np.where(df.col > upper_limit, upper_limit,
(np.where(df.col < lower_limit, lower_limit, df.col)))
#Lower Capping:
df['col'] = np.where(df.col > upper_limit, upper_limit,
(np.where(df.col < lower_limit, lower_limit, df.col)))](https://image.slidesharecdn.com/datascience-outlierhandling-210216092158/75/Data-science-Handling-Outliers-7-2048.jpg)












































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)




