Download as PDF, PPTX





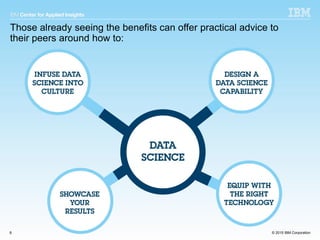










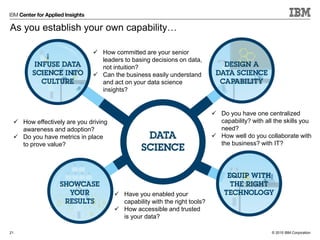





The document summarizes key lessons from data science leaders on how to build a successful data science capability within an organization. It provides quotes from various data science professionals on centralizing the core function while distributing support, paying data scientists based on business outcomes, showcasing results through metrics and ROI, and equipping teams with the right tools and accessible data. The document advocates collaborating closely with business and IT partners to infuse a data-driven culture and extract maximum value from data science efforts.



















































































