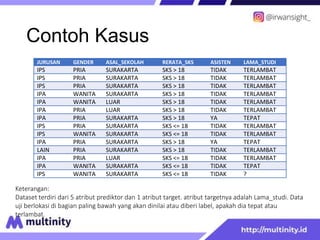
The document discusses the Naive Bayes classifier. It begins with an introduction to probability and defines the formula for Naive Bayes classification. It then provides an example dataset to demonstrate how to calculate the probabilities of each attribute value belonging to each class. The example shows calculating the probabilities for attributes like major, gender, school origin, GPA, and assistant status to predict whether a student's study duration will be on time or late.