Downloaded 264 times






![© 2016 Pivotal Software, Inc. All rights reserved.
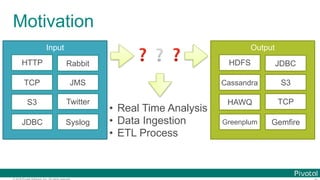
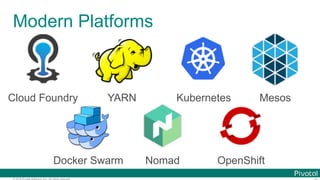
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-11-320.jpg)
![© 2016 Pivotal Software, Inc. All rights reserved.
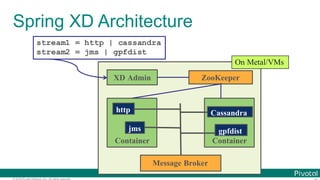
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-12-320.jpg)
![© 2016 Pivotal Software, Inc. All rights reserved.
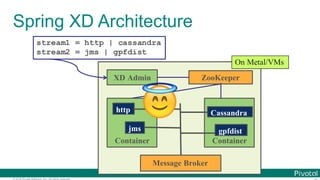
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head
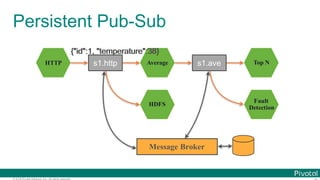
Microservice for each data processing](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-13-320.jpg)
![© 2016 Pivotal Software, Inc. All rights reserved.
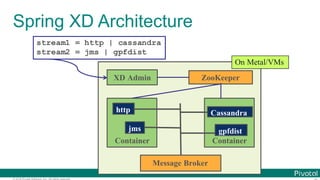
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head
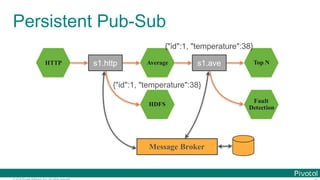
Microservice for each data processing](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-14-320.jpg)
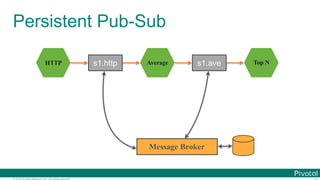
![© 2016 Pivotal Software, Inc. All rights reserved.
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head
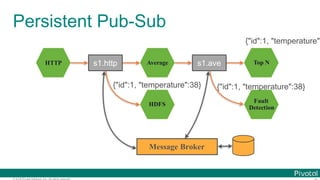
Microservice for each data processing
bound with
Message Brokers](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-15-320.jpg)
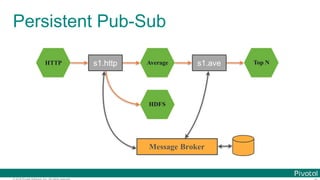
![© 2016 Pivotal Software, Inc. All rights reserved.
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head
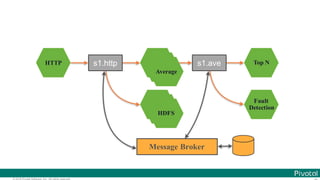
Microservice for each data processing
bound with
Message Brokers](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-16-320.jpg)
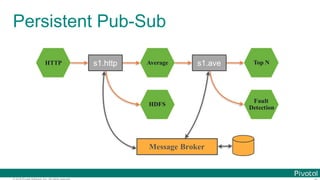
![© 2016 Pivotal Software, Inc. All rights reserved.
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head
Microservice for each data processing
bound with
Message Brokers
on the modern platform](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-17-320.jpg)
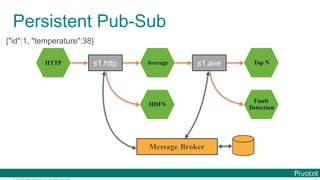
![© 2016 Pivotal Software, Inc. All rights reserved.
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head
Microservice for each data processing
bound with
Message Brokers
on the modern platform](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-18-320.jpg)
![© 2016 Pivotal Software, Inc. All rights reserved.
Data Microservices
$ cat book.txt | tr ' ' '¥ ' | tr '[:upper:]' '[:lower:]' |
tr -d '[:punct:]' |
grep -v '[^a-z]‘ |
sort | uniq -c | sort -rn | head
Microservice for each data processing
bound with
Message Brokers
on the modern platform](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-19-320.jpg)








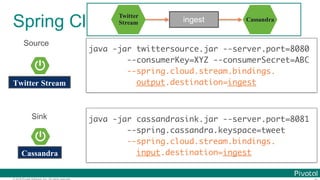

![© 2016 Pivotal Software, Inc. All rights reserved.
Programming Model (Sink)
@SpringBootApplication
@EnableBinding(Sink.class)
public class DemoSinkApp {
@StreamListener(Sink.INPUT)
void receive(Message<String> message) {
System.out.println("Received " + message);
}
public static void main(String[] args) {
SpringApplication.run(DemoSinkApp.class, args);
}
}](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-35-320.jpg)

![© 2016 Pivotal Software, Inc. All rights reserved.
Programming Model (Source)
@SpringBootApplication @RestController
@EnableBinding(Source.class)
public class DemoSourceApp {
@Autowired Source source;
@GetMapping void send(@RequestParam String text) {
source.output()
.send(MessageBuilder.withPayload(text).build());
}
public static void main(String[] args) {
SpringApplication.run(DemoSourceApp.class, args);
}
}](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-37-320.jpg)
![© 2016 Pivotal Software, Inc. All rights reserved.
Programming Model (Source)
@SpringBootApplication @RestController
@EnableBinding(Source.class)
public class DemoSourceApp {
@Bean
@InboundChannelAdapter(channel = Source.OUTPUT, poller =
@Poller(fixedDelay = "1000", maxMessagesPerPoll = "1"))
MessageSource<String> source() {
return () -> MessageBuilder.withPayload("Hi").build());
}
public static void main(String[] args) {
SpringApplication.run(DemoSourceApp.class, args);
}}](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-38-320.jpg)



![© 2016 Pivotal Software, Inc. All rights reserved.
Programming Model (Processor)
@SpringBootApplication
@EnableBinding(Processor.class)
public class DemoProcessorApp {
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
void receive(String text) {
return "[[" + text + "]]";
}
public static void main(String[] args) {
SpringApplication.run(DemoProcessorApp.class, args);
}
}](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-43-320.jpg)

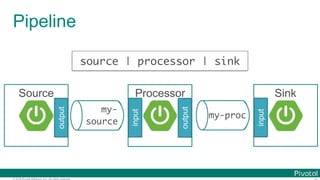
![© 2016 Pivotal Software, Inc. All rights reserved.
Reactive API Support
@SpringBootApplication
@EnableBinding(Processor.class)
public class DemoProcessorRxApp {
@StreamListener @Output(Processor.OUTPUT)
public Flux<String> receive(@Input(Processor.INPUT)
Flux<String> stream) {
return stream.map(text -> "[[" + text + "]]");
}
public static void main(String[] args) {
SpringApplication.run(DemoProcessorRxApp.class, args);
}
}](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-46-320.jpg)








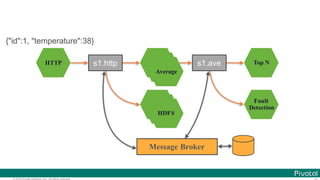
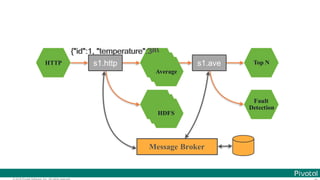
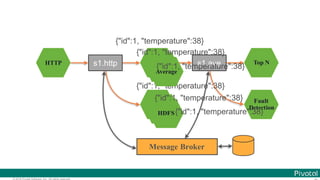
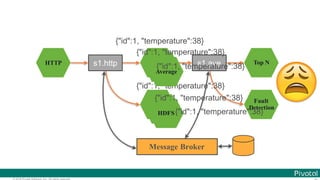
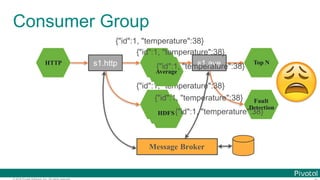
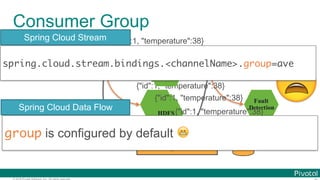
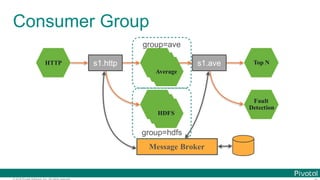
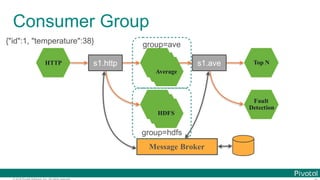
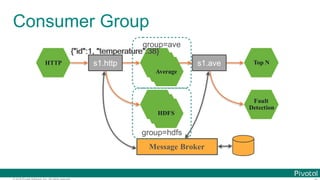
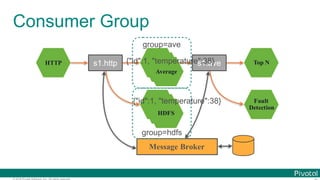
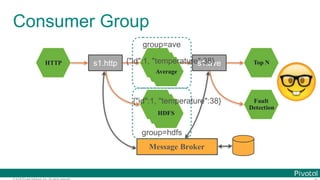
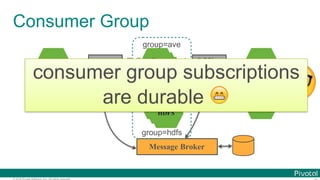
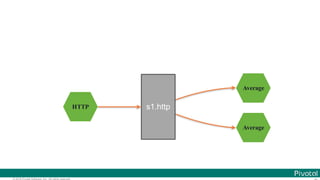
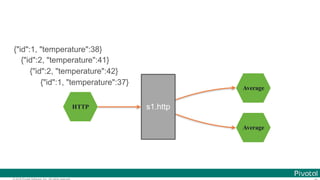
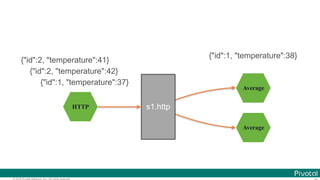
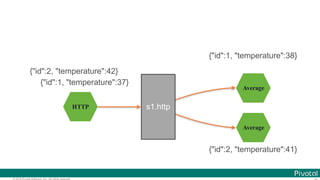
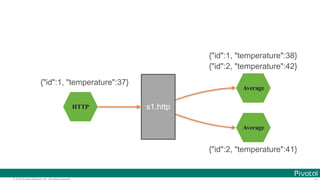
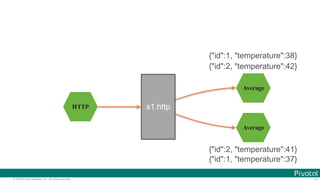
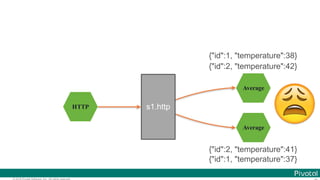
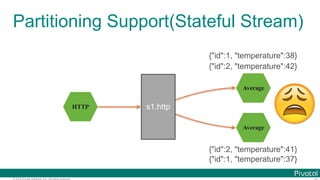
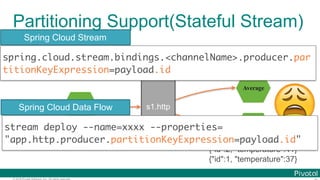
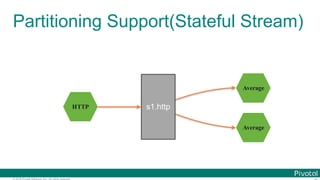
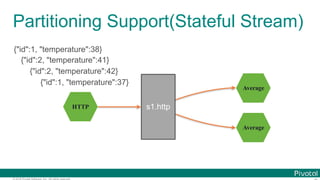
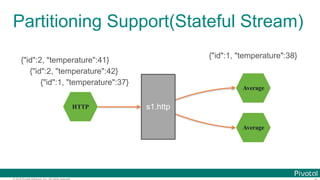
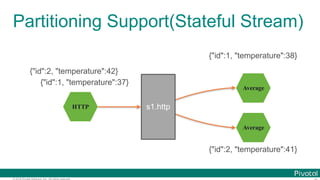
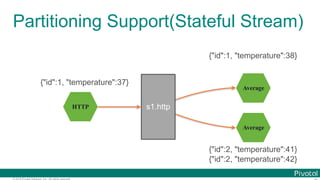
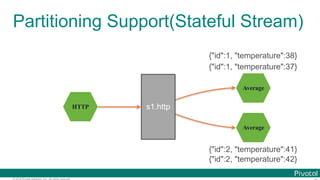
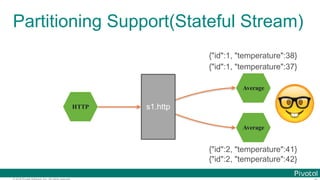



![© 2016 Pivotal Software, Inc. All rights reserved.
Programming Model (CLR)
@SpringBootApplication
@EnableTask
public class DemoTaskApp {
@Bean
CommandLineRunner clr() {
return args -> System.out.println("Task!");
}
public static void main(String[] args) {
SpringApplication.run(DemoTaskApp.class, args);
}
} spring.application.name=hello](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-99-320.jpg)

![© 2016 Pivotal Software, Inc. All rights reserved.
Programming Model (Spring Batch)
@SpringBootApplication @EnableBatchProcessing
@EnableTask
public class DemoBatchApp {
@Autowired JobBuilderFactory jobBuilderFactory;
@Autowired StepBuilderFactory stepBuilderFactory;
@Bean Step step1() { /* ... */ }
@Bean Step step2() { /* ... */ }
@Bean Job job() { return jobBuilderFactory.get("job")
.start(step1()).next(step2()).build()}
public static void main(String[] args) {
SpringApplication.run(DemoTaskApp.class, args);
}}
https://github.com/making/cf-spring-batch-demo
spring.application.name=hello-batch](https://image.slidesharecdn.com/2016-11-18springdaysscdf-161118091515/85/Data-Microservices-with-Spring-Cloud-Stream-Task-and-Data-Flow-jsug-springday-101-320.jpg)


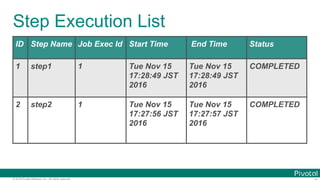
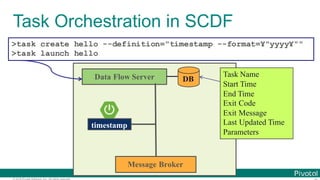
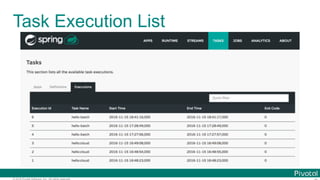
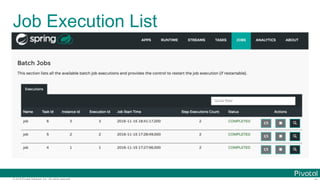
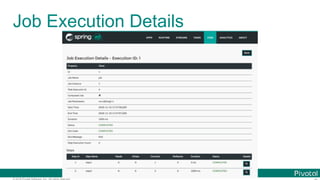
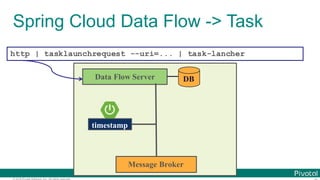

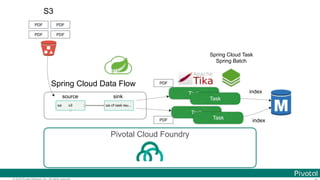

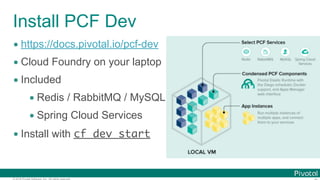




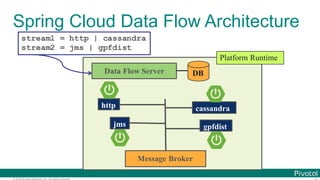
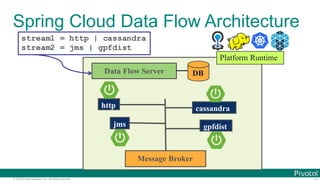
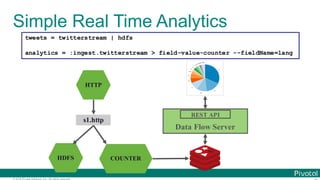
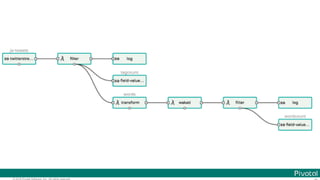
The document discusses Spring Cloud Data Flow, which provides a framework for building data pipelines using microservices. It describes how Spring Cloud Data Flow orchestrates long-lived streaming applications using Spring Cloud Stream and short-lived batch processing applications using Spring Cloud Task. It also discusses how these applications can be deployed on modern platforms using deployment-specific Spring Cloud Deployers.













![[cb22] Hayabusa Threat Hunting and Fast Forensics in Windows environments fo...](https://cdn.slidesharecdn.com/ss_thumbnails/d2t2s052022-10-28-dfirandthreathuntingwithwindowseventlogszachmathisversion3-230103072306-eb57bdc0-thumbnail.jpg?width=640&height=640&fit=bounds)




























































































