Download to read offline















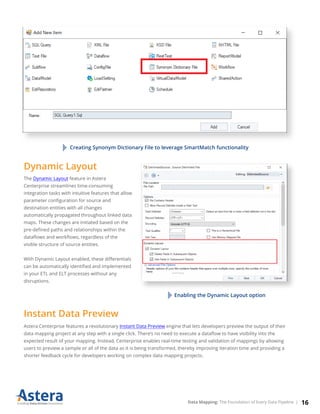


The document discusses the importance of data mapping as a critical process for integrating and transforming data within enterprises. It outlines various data mapping techniques, tools, and their relevance in data integration, migration, warehousing, and transformation tasks. Additionally, Astera Centerprise is highlighted as an effective solution for managing complex data mappings with features like a visual interface, built-in data quality checks, and automation capabilities.
































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


