Download as PDF, PPTX



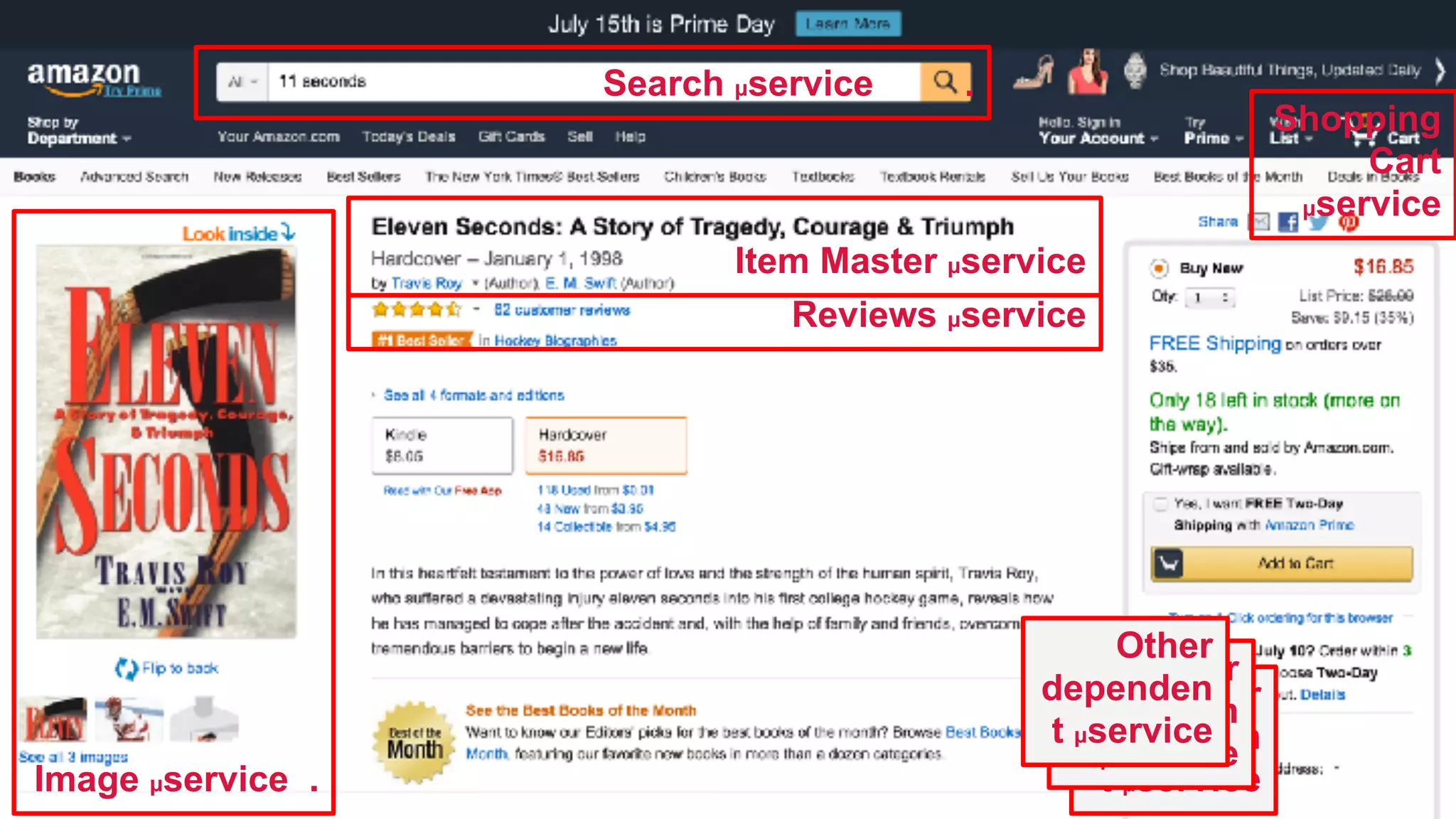




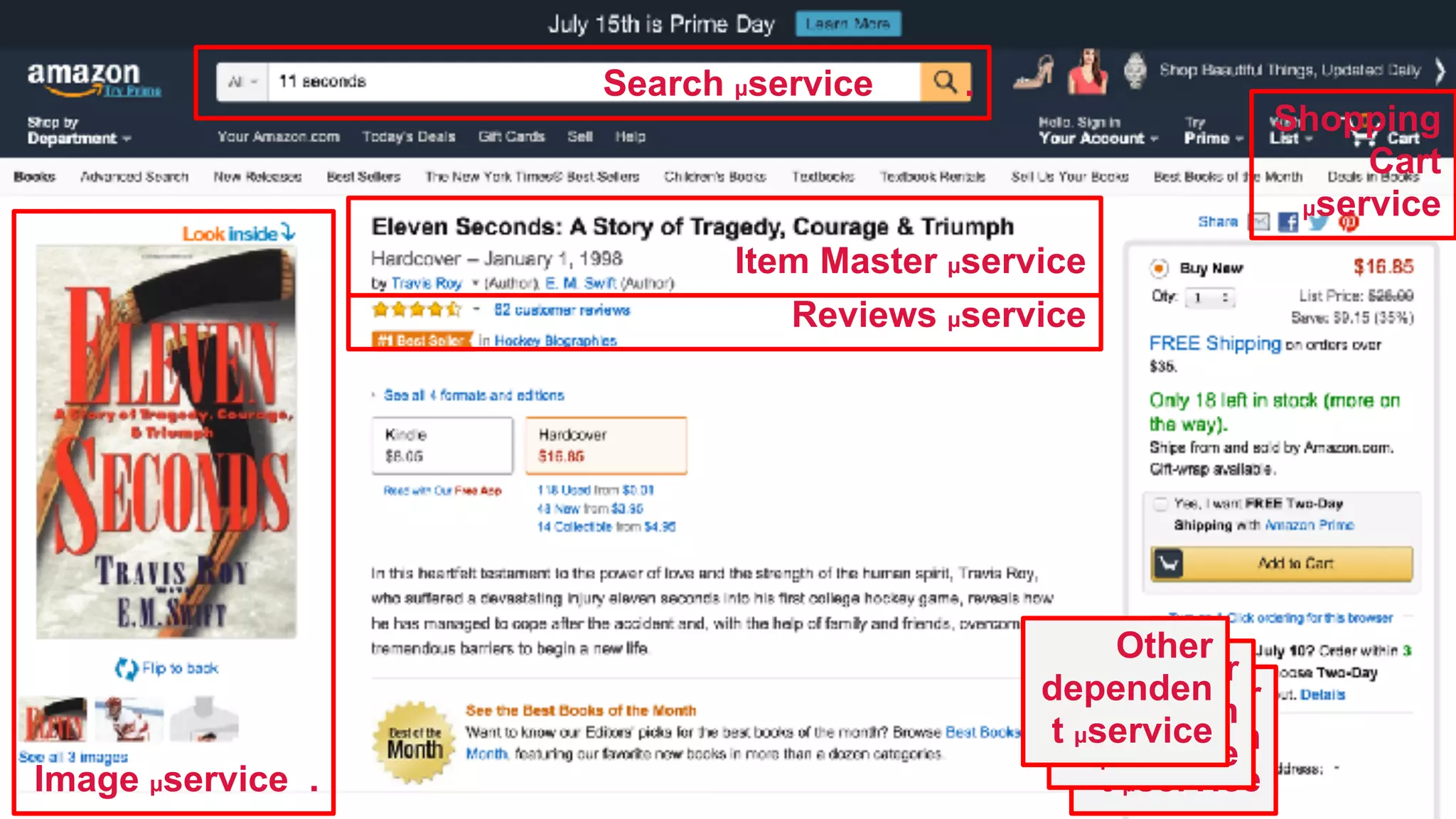
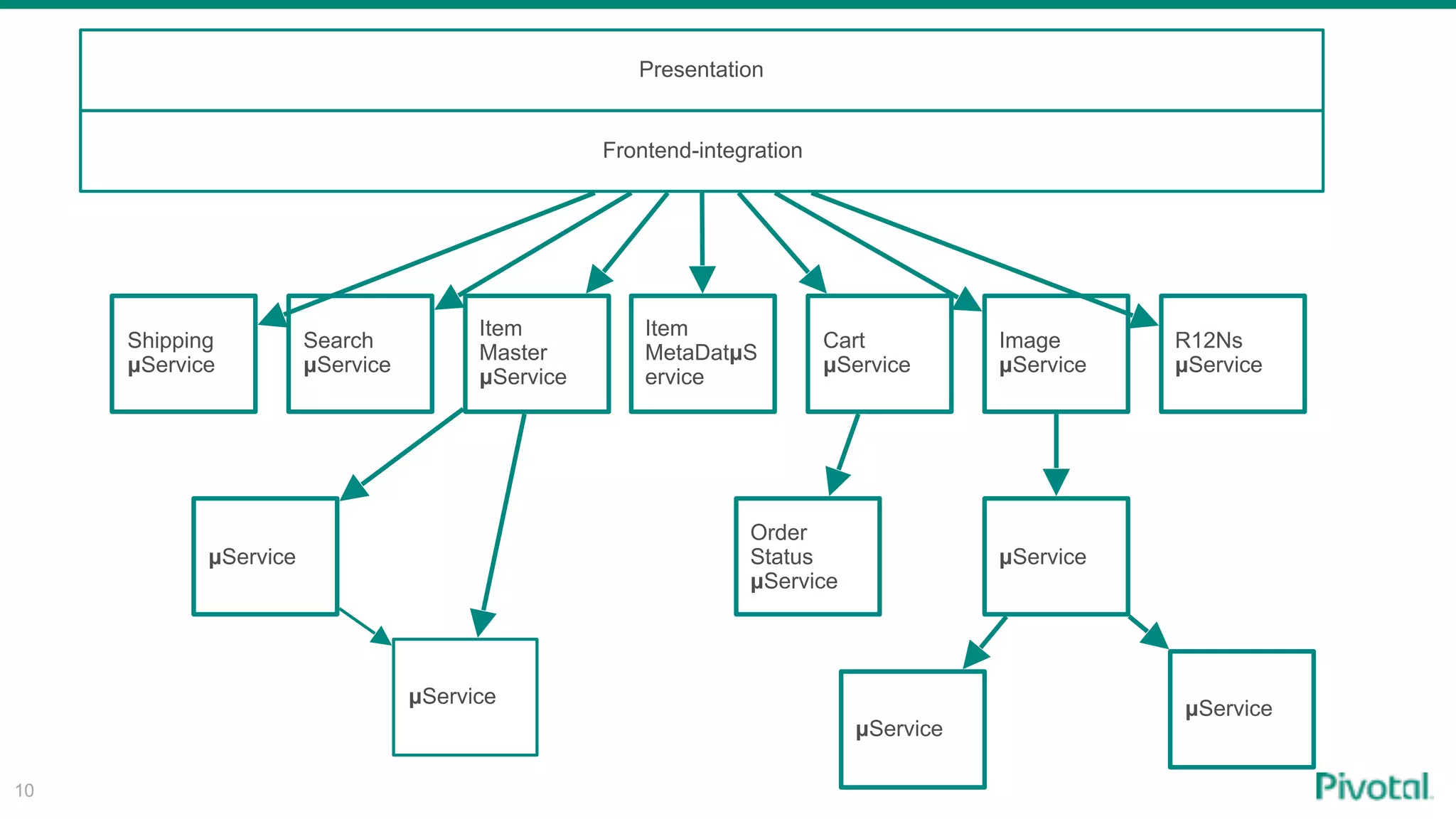
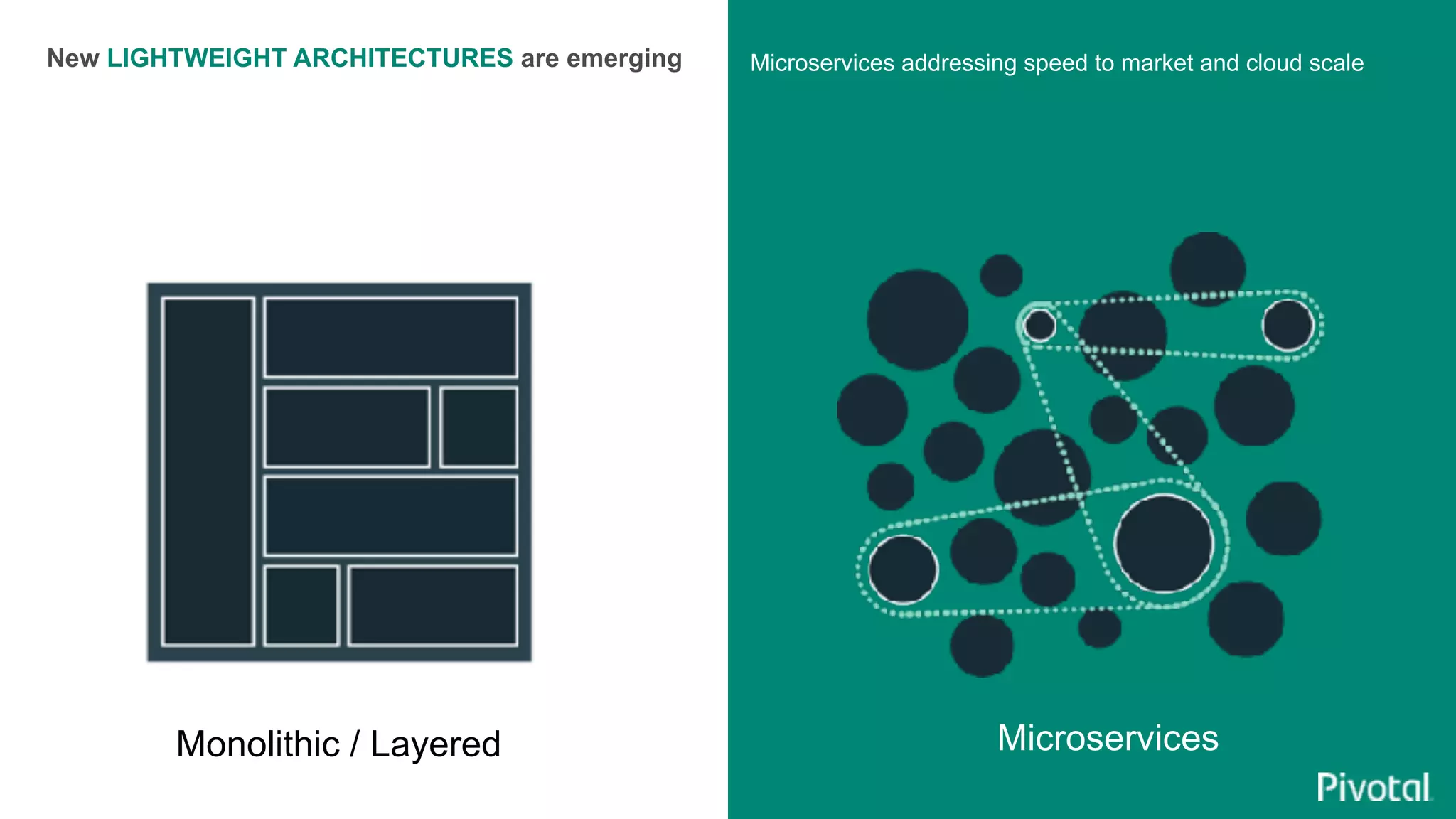


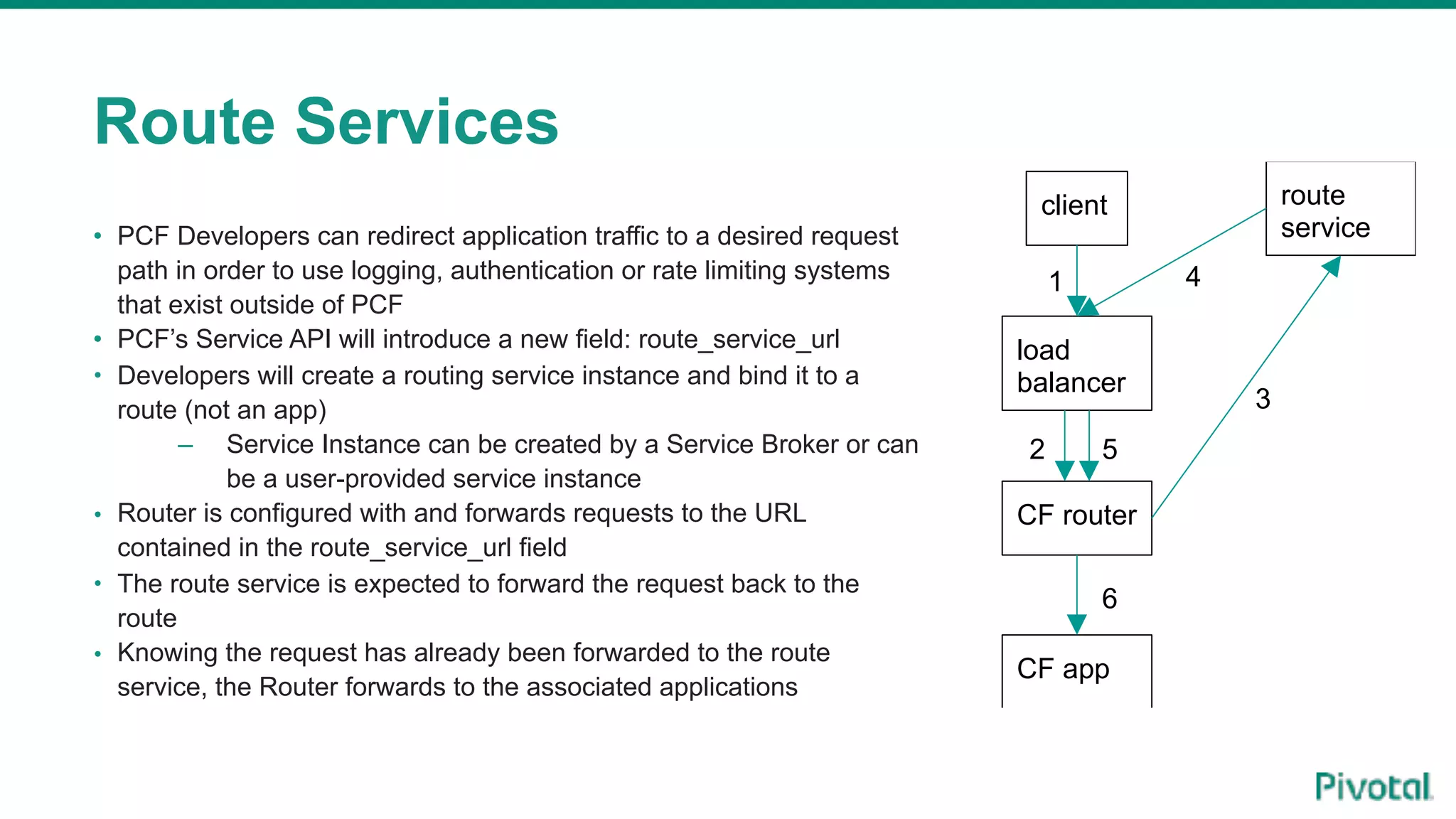
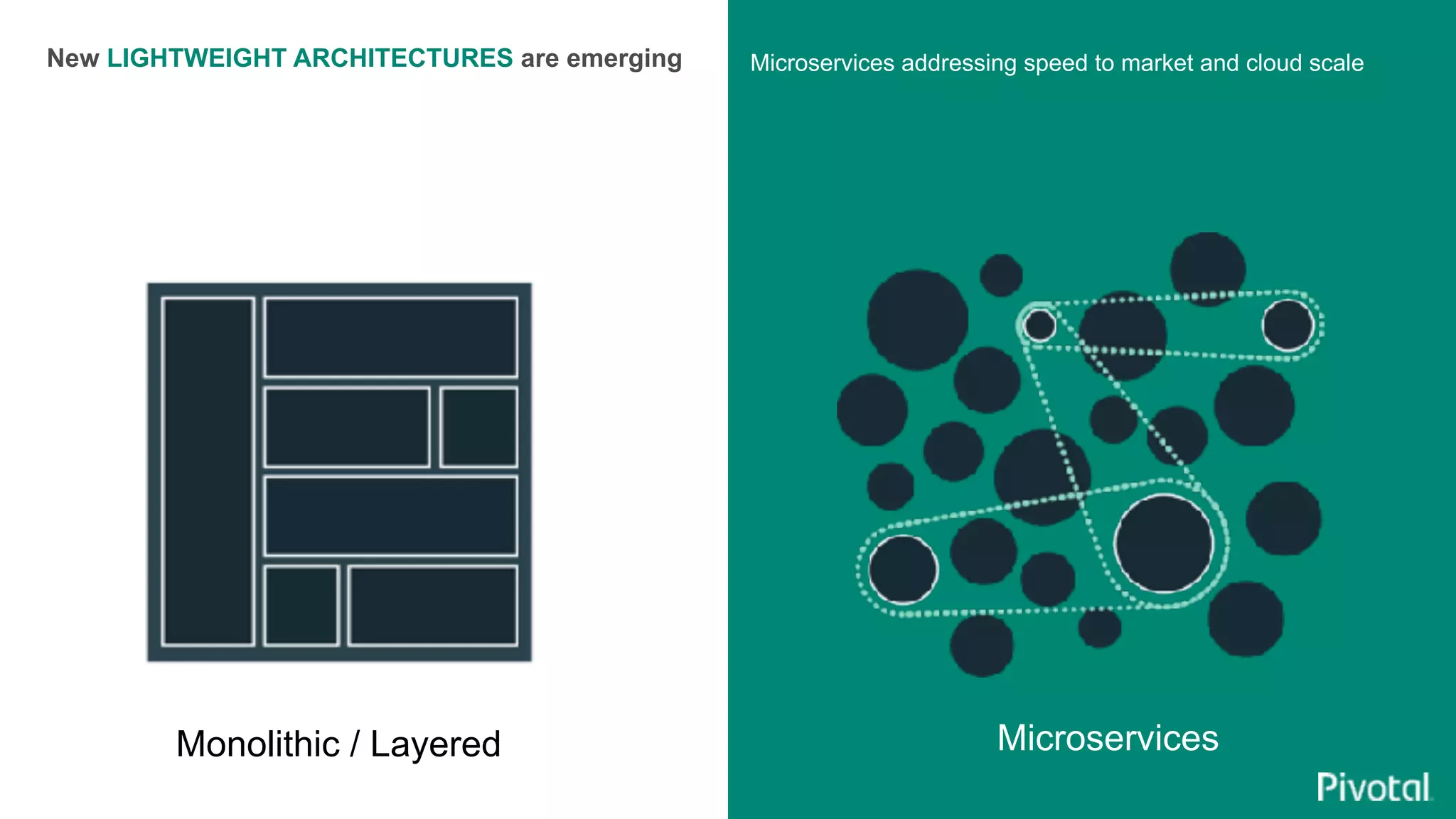
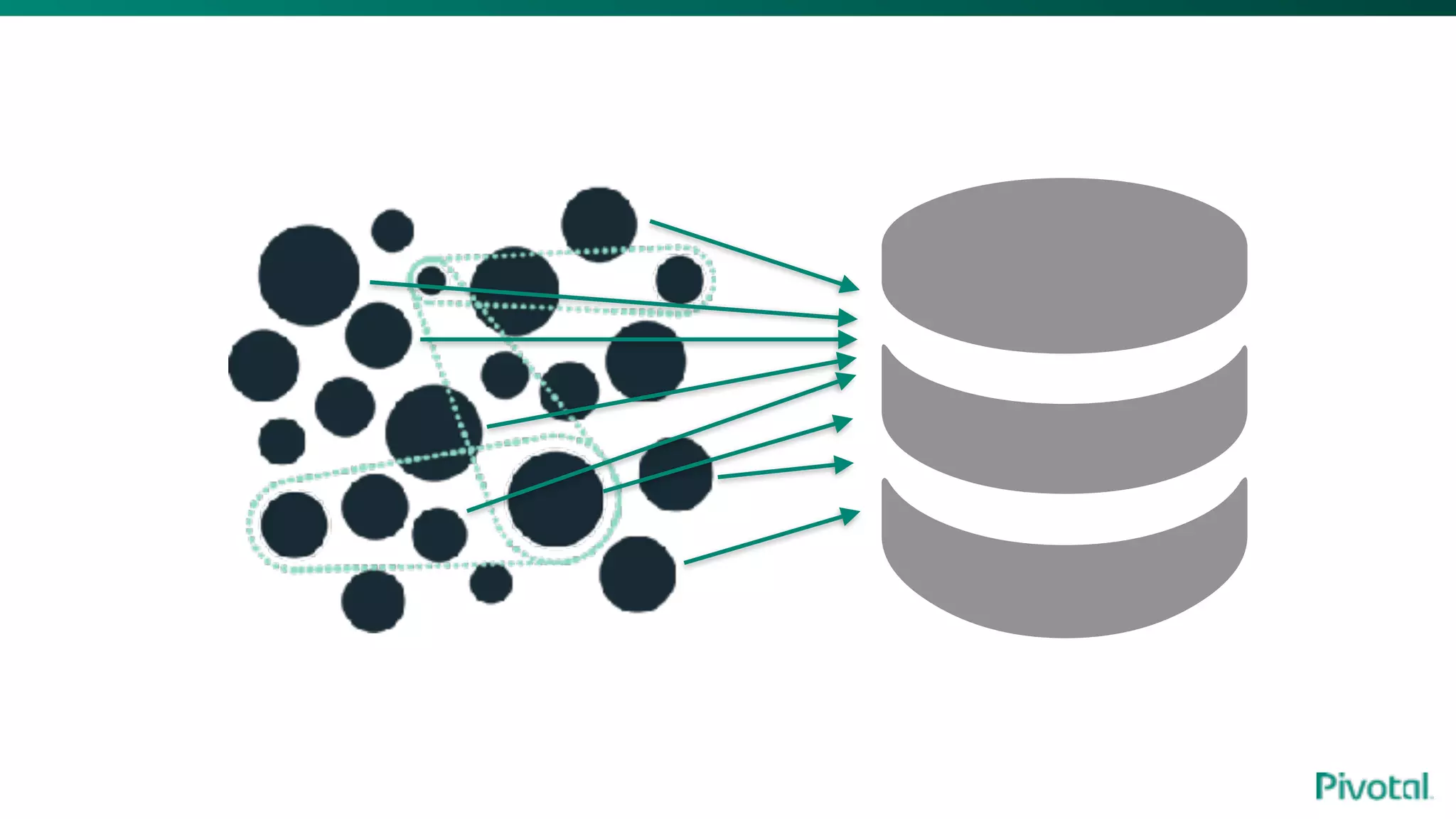

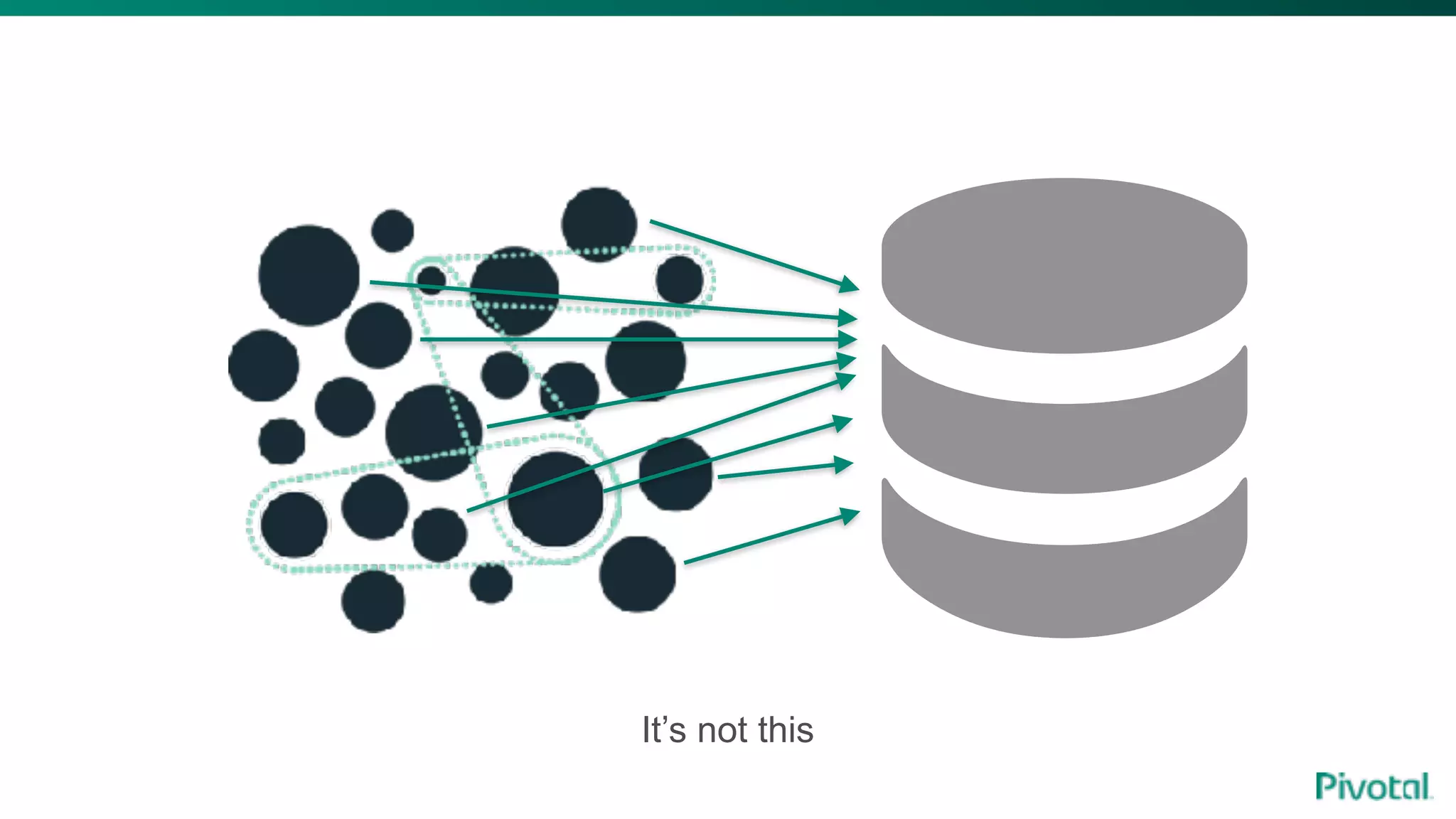



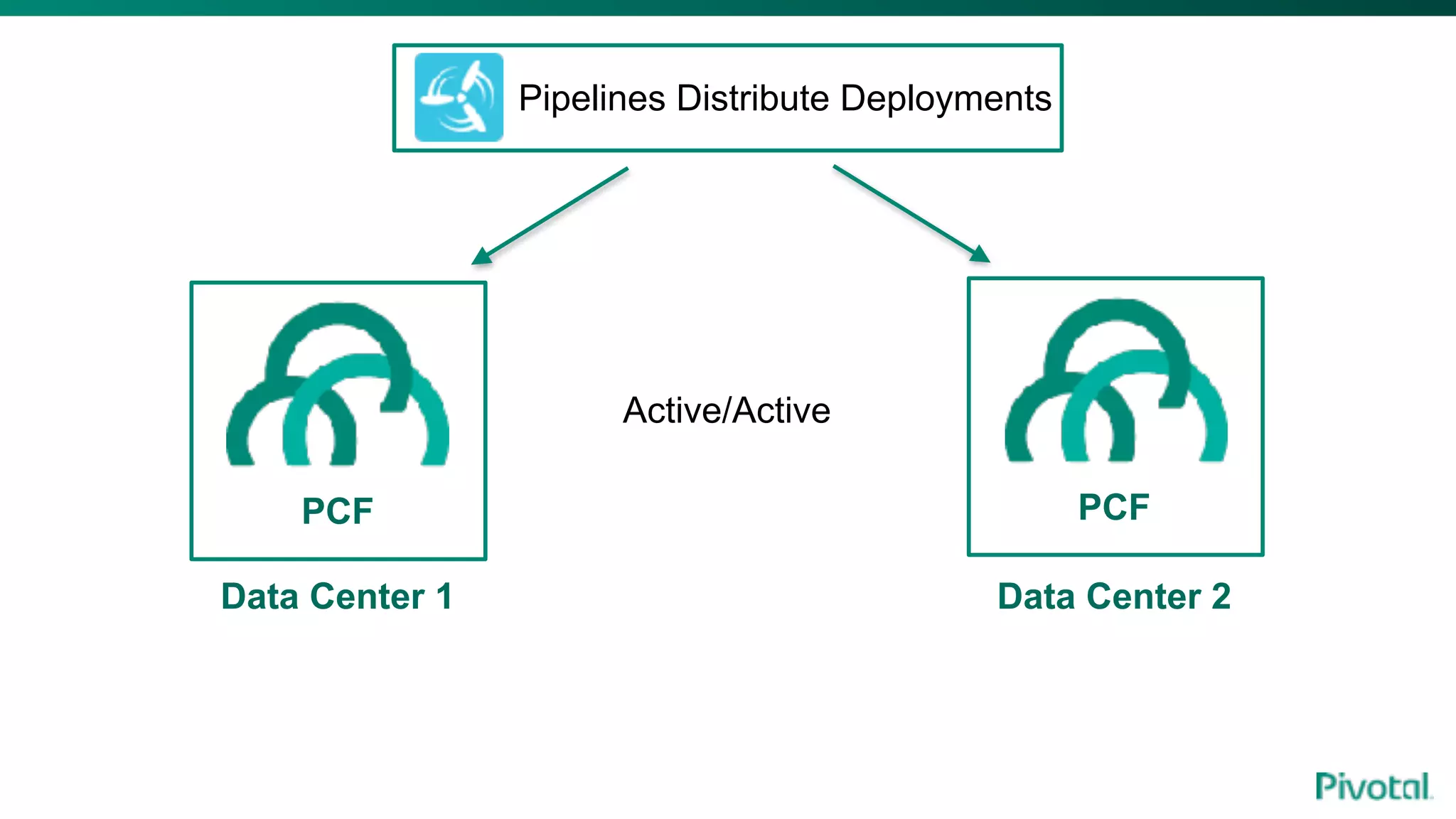
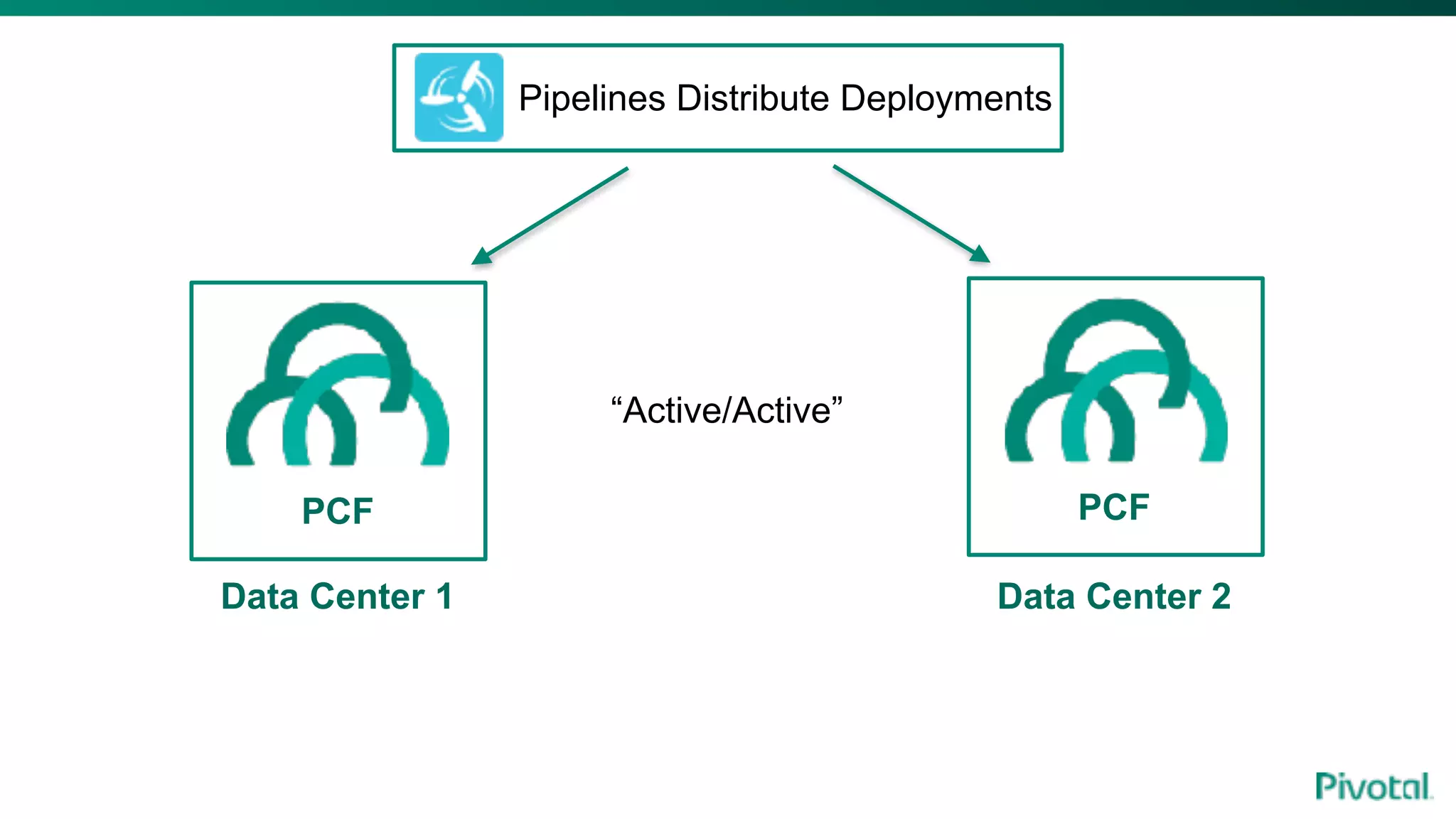
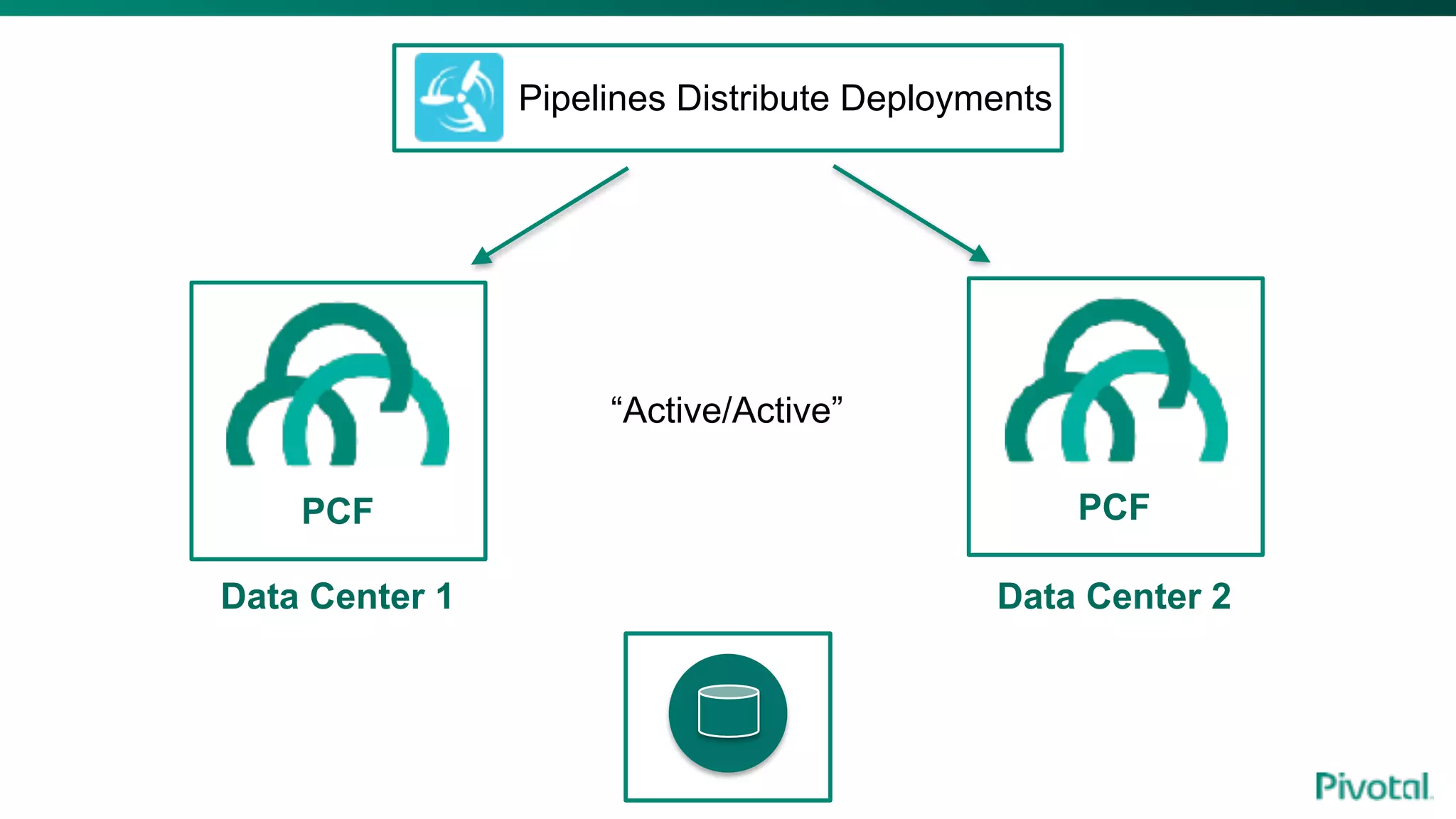
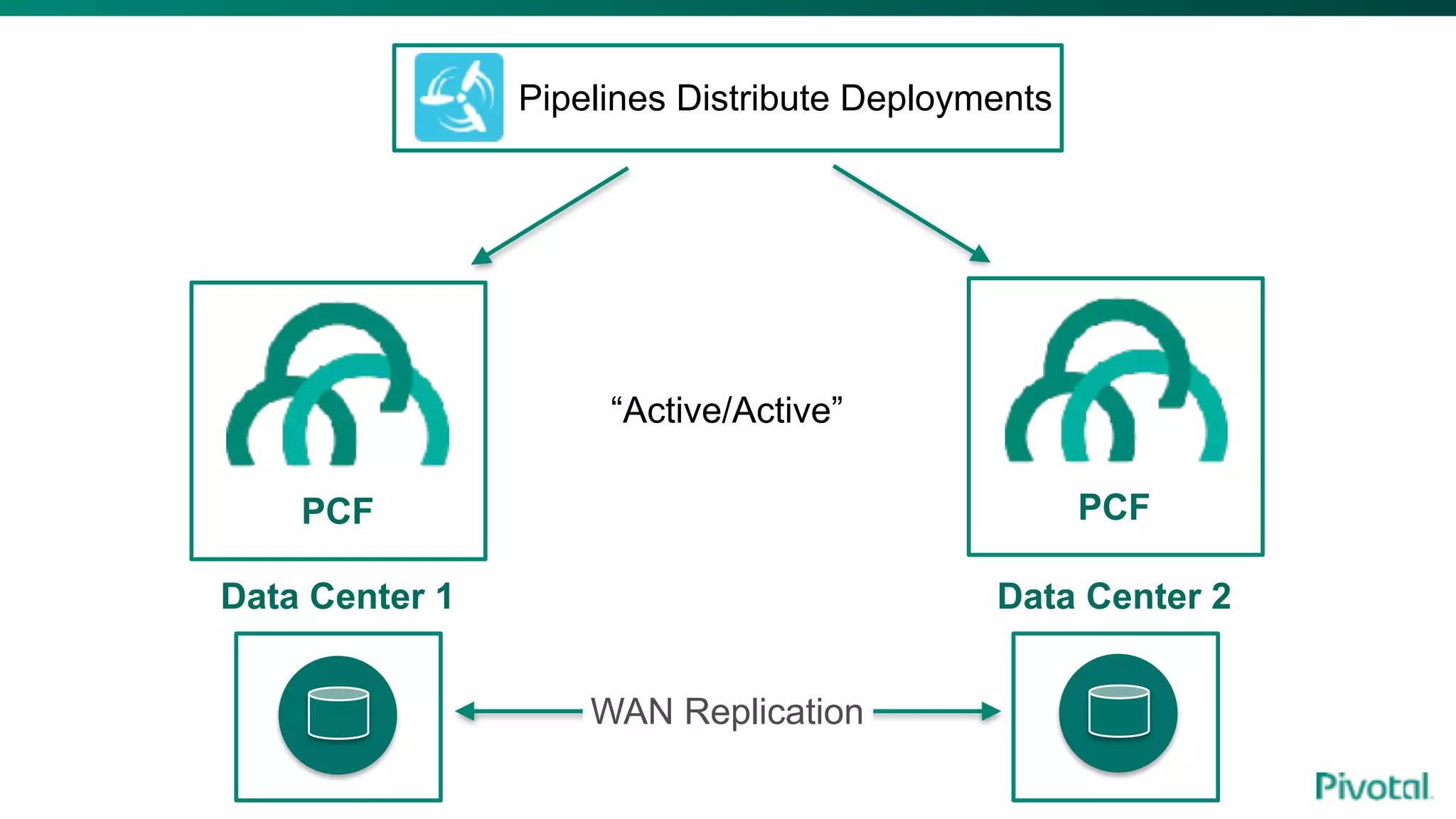

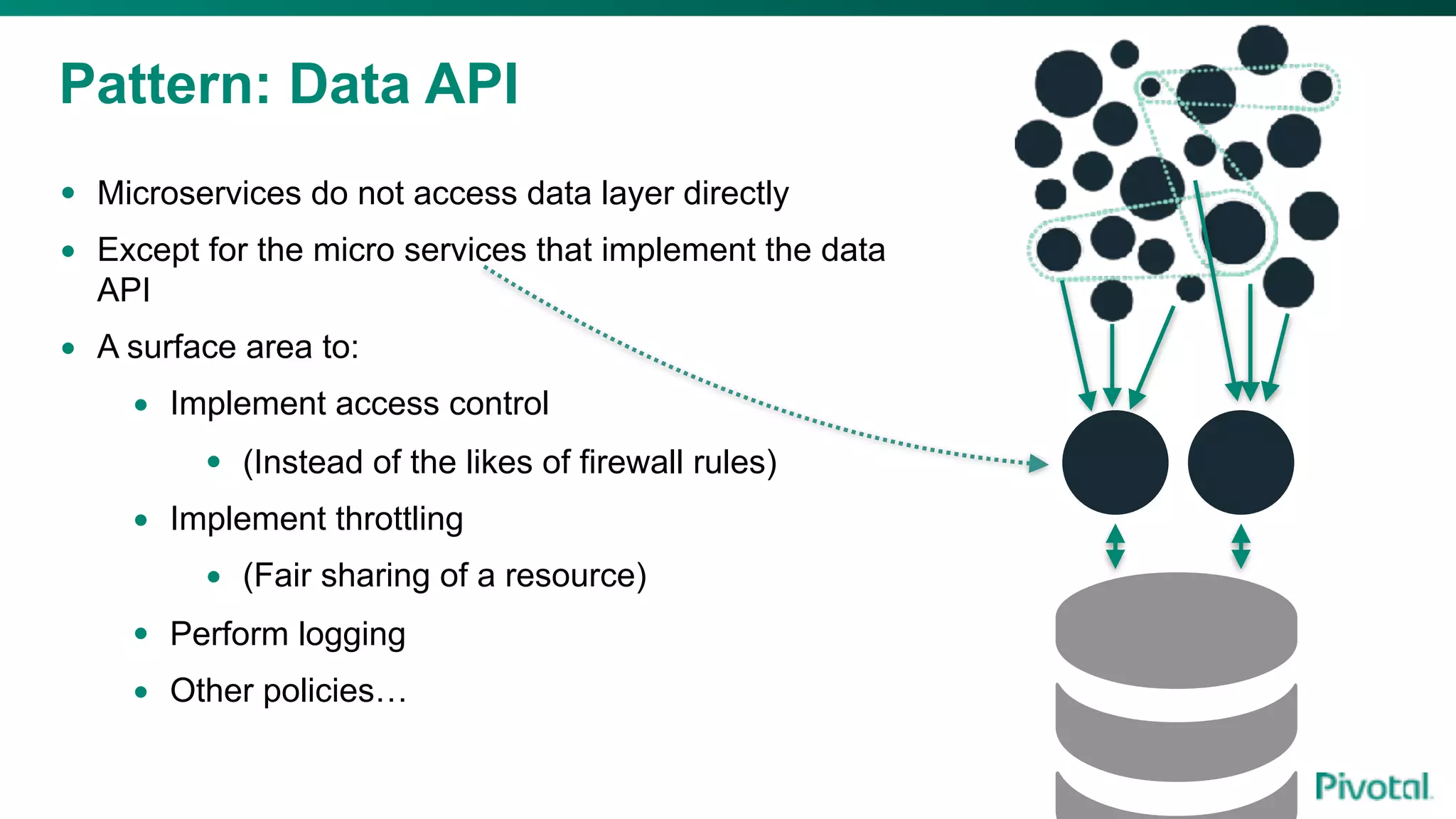
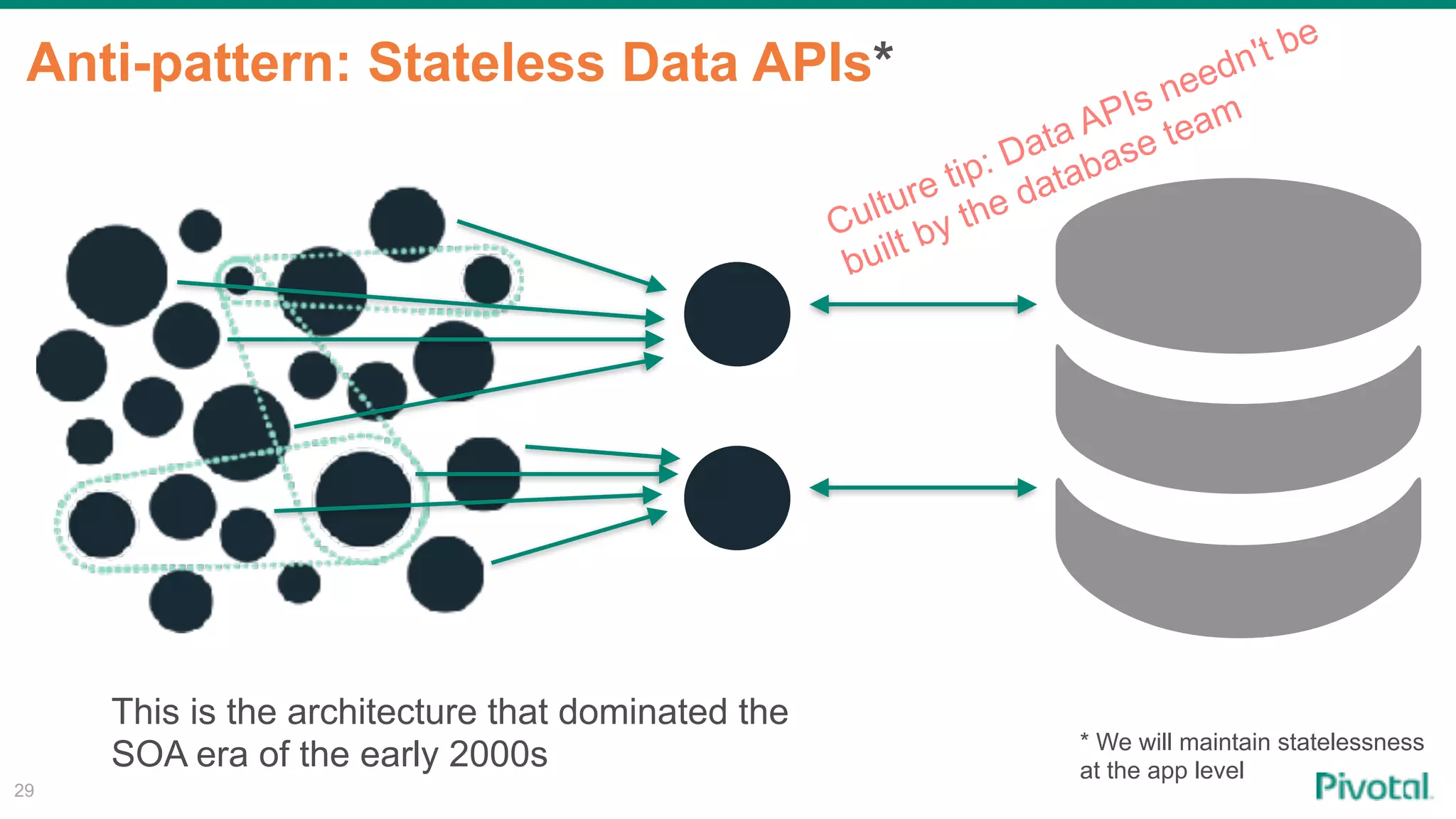
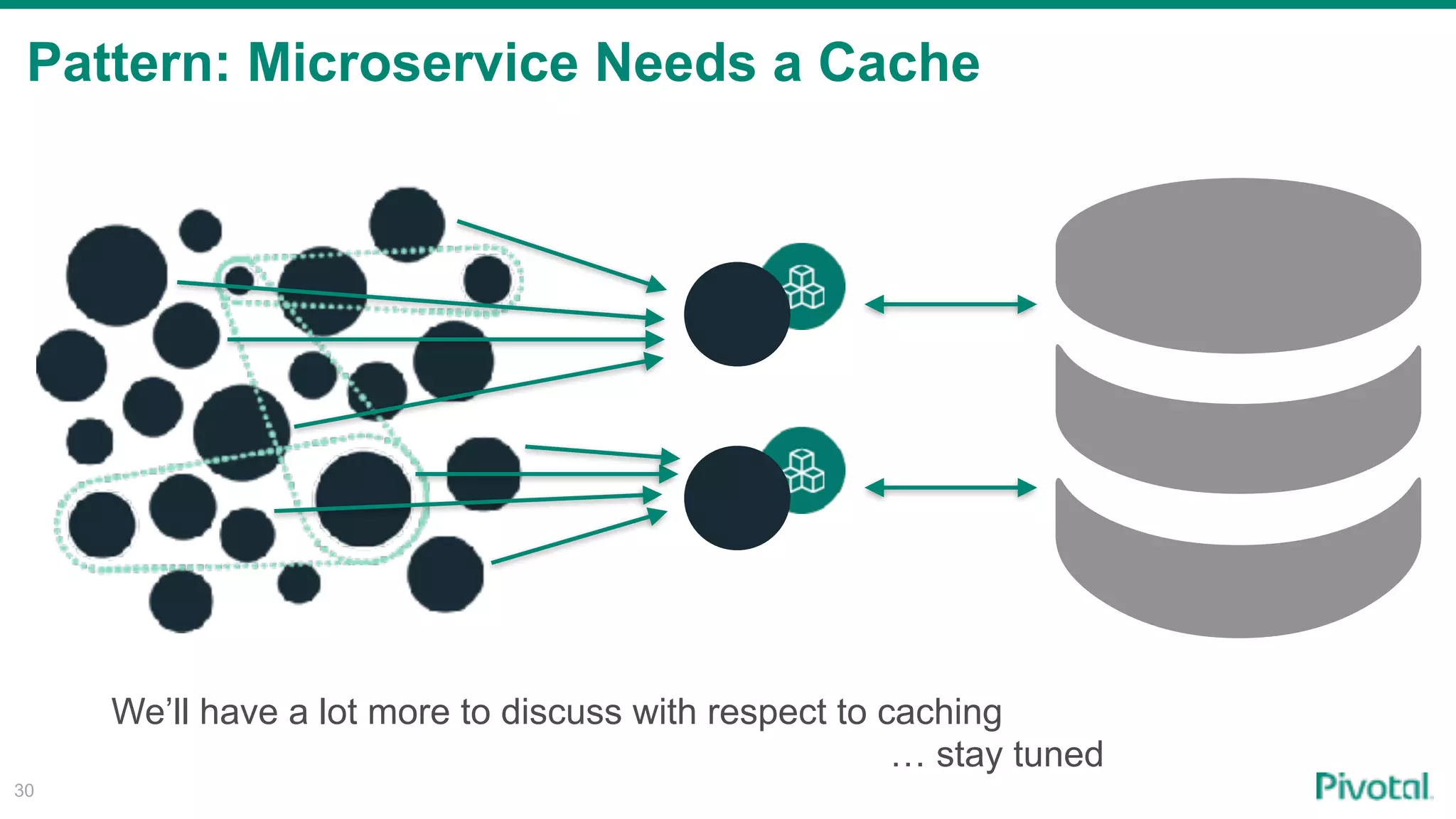
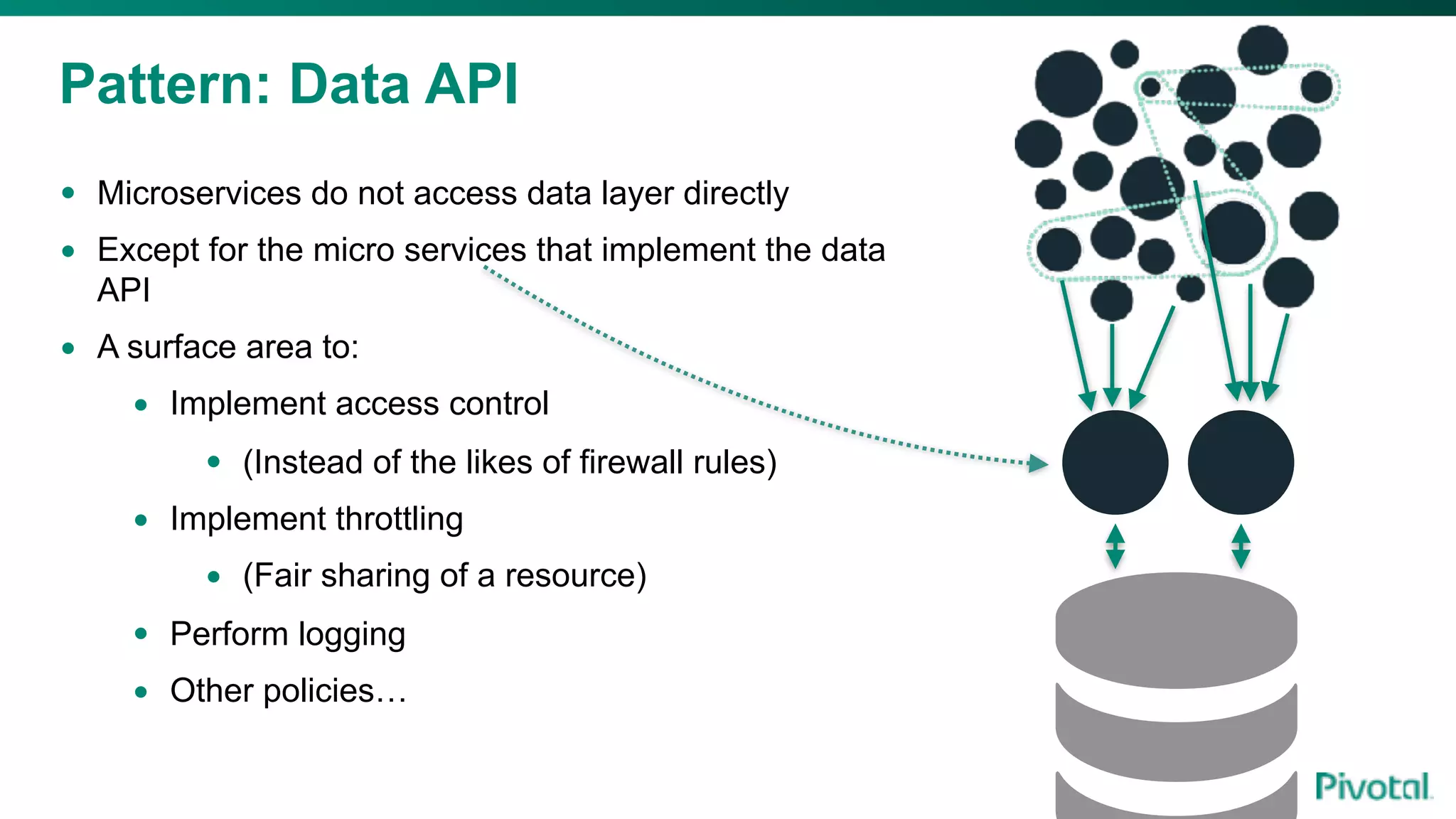
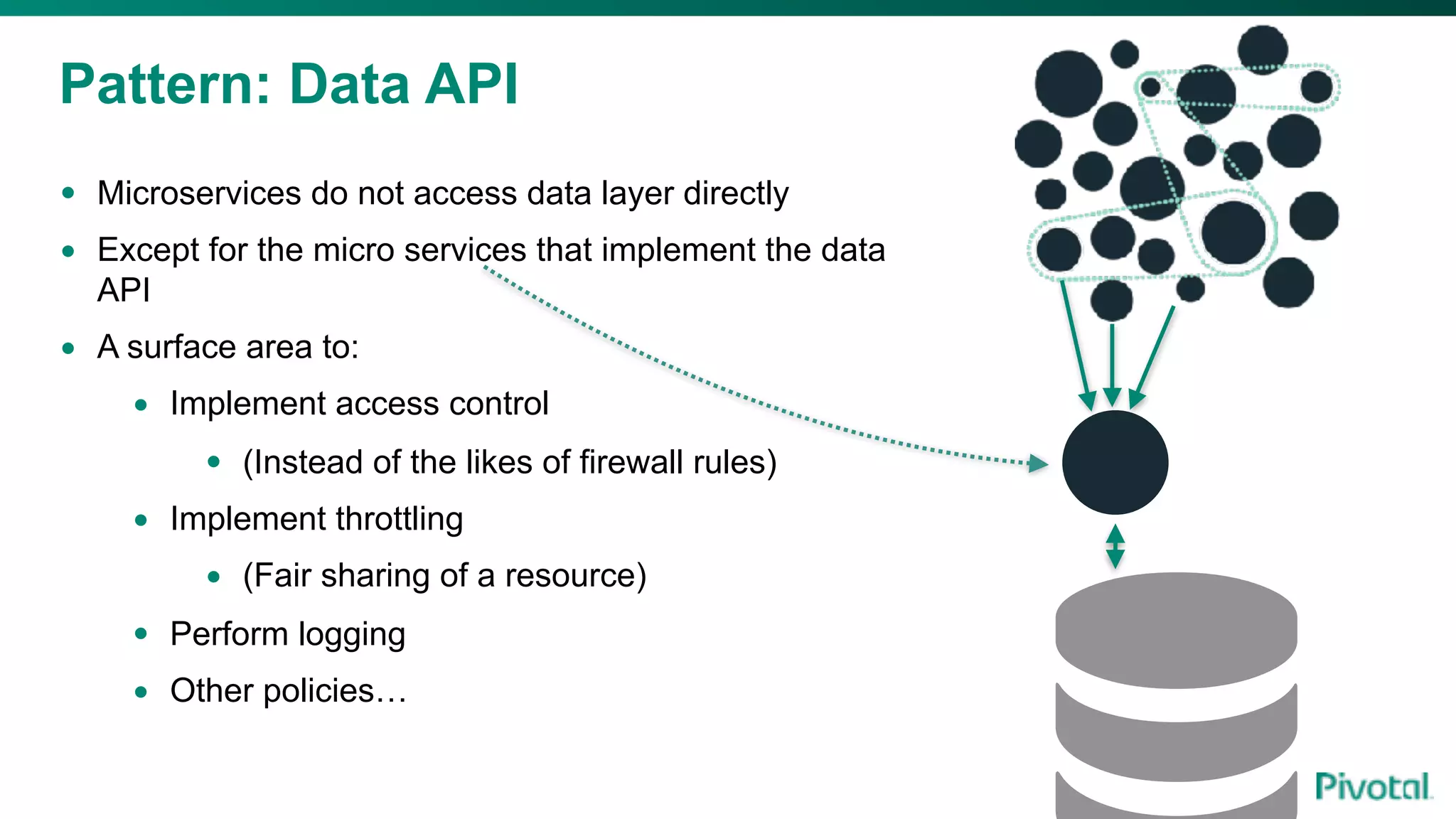
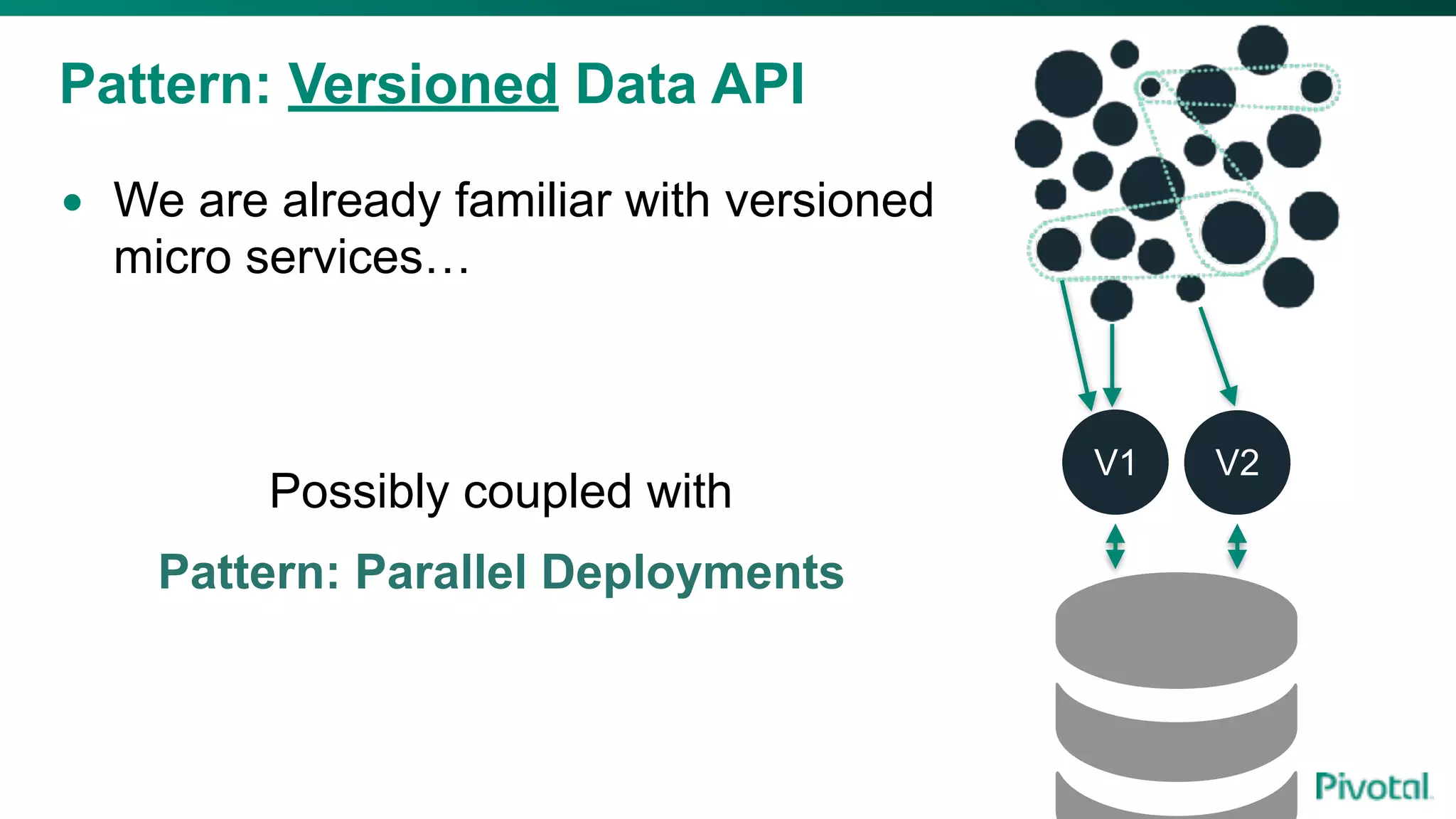

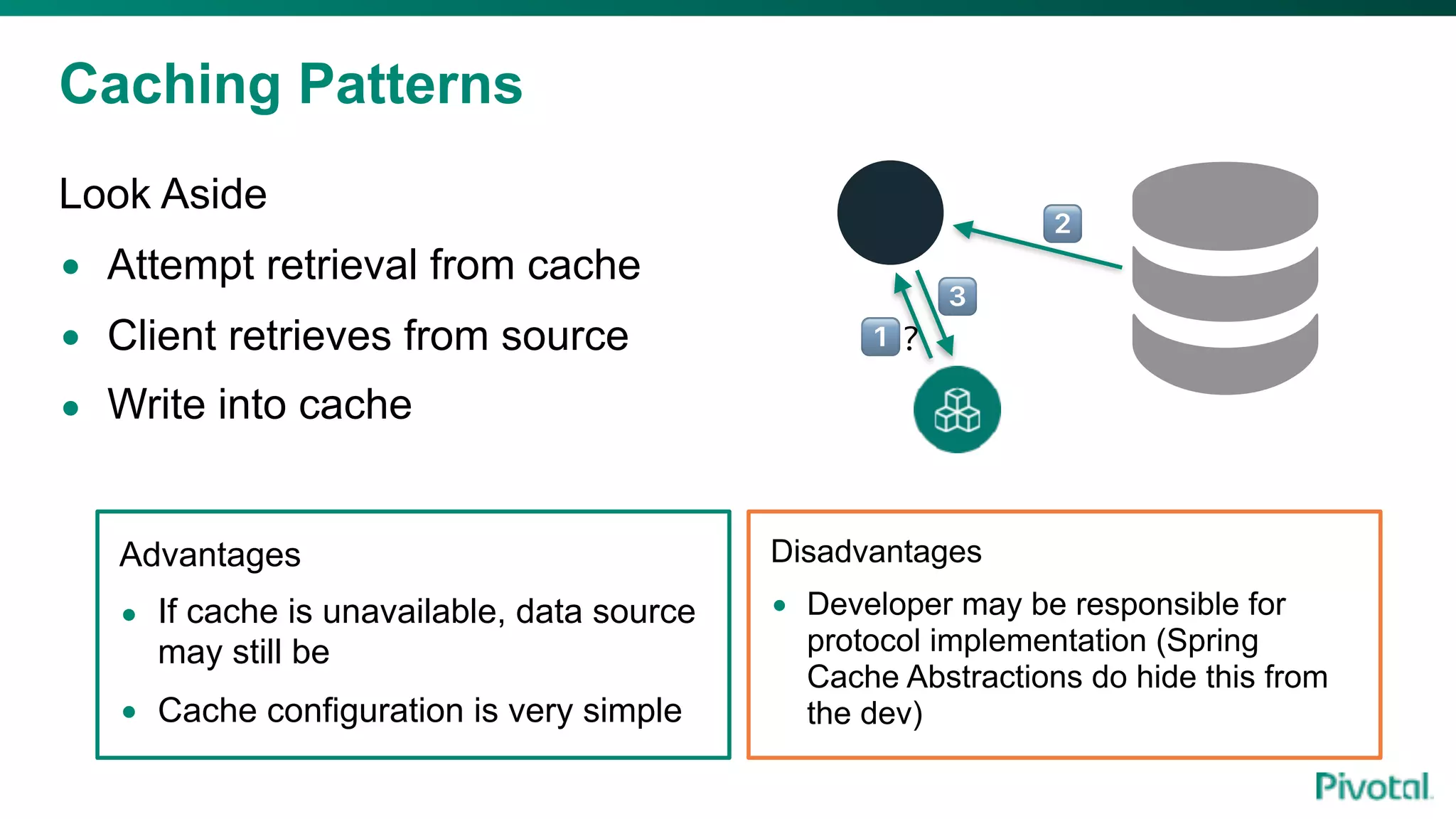
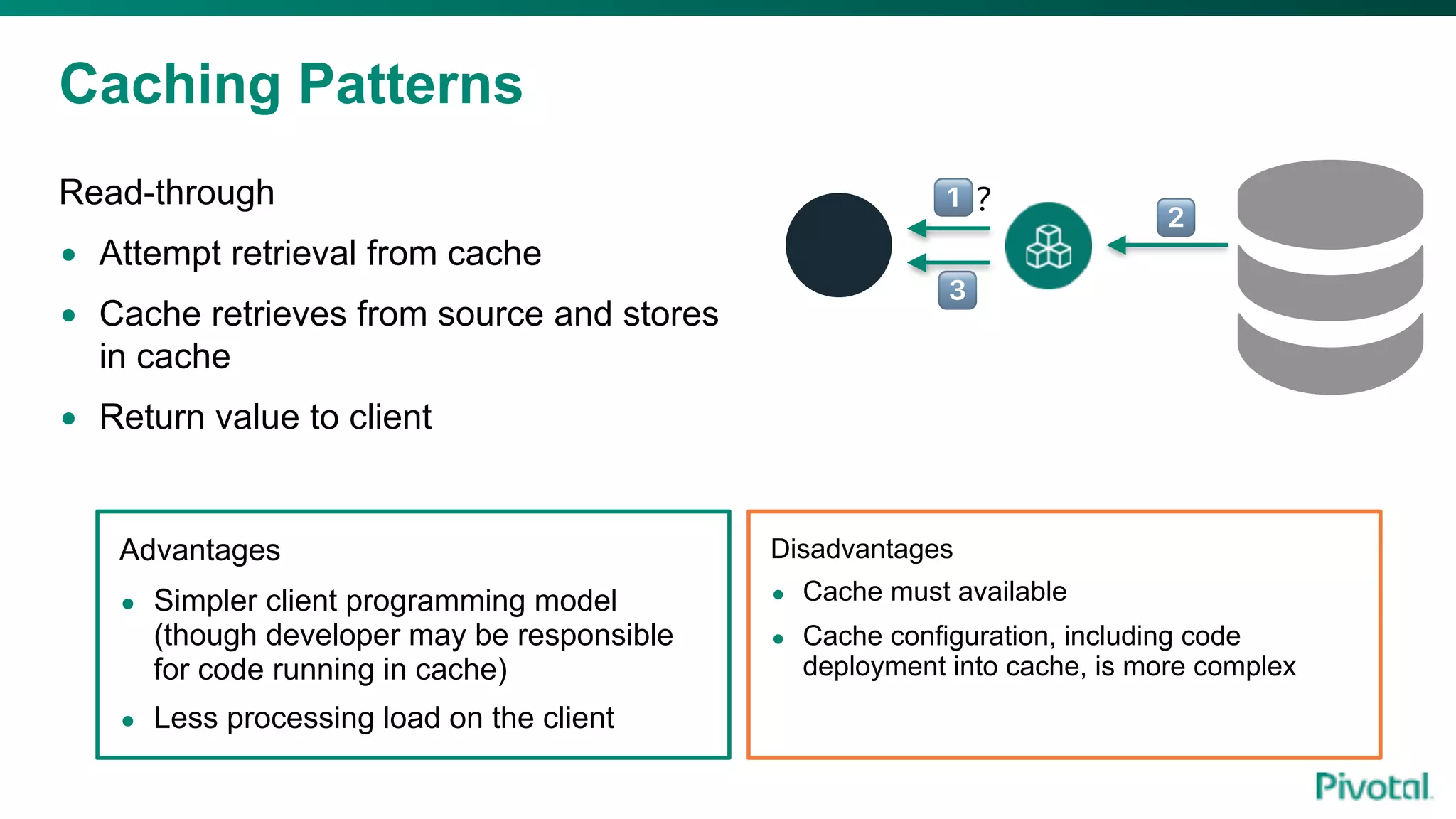
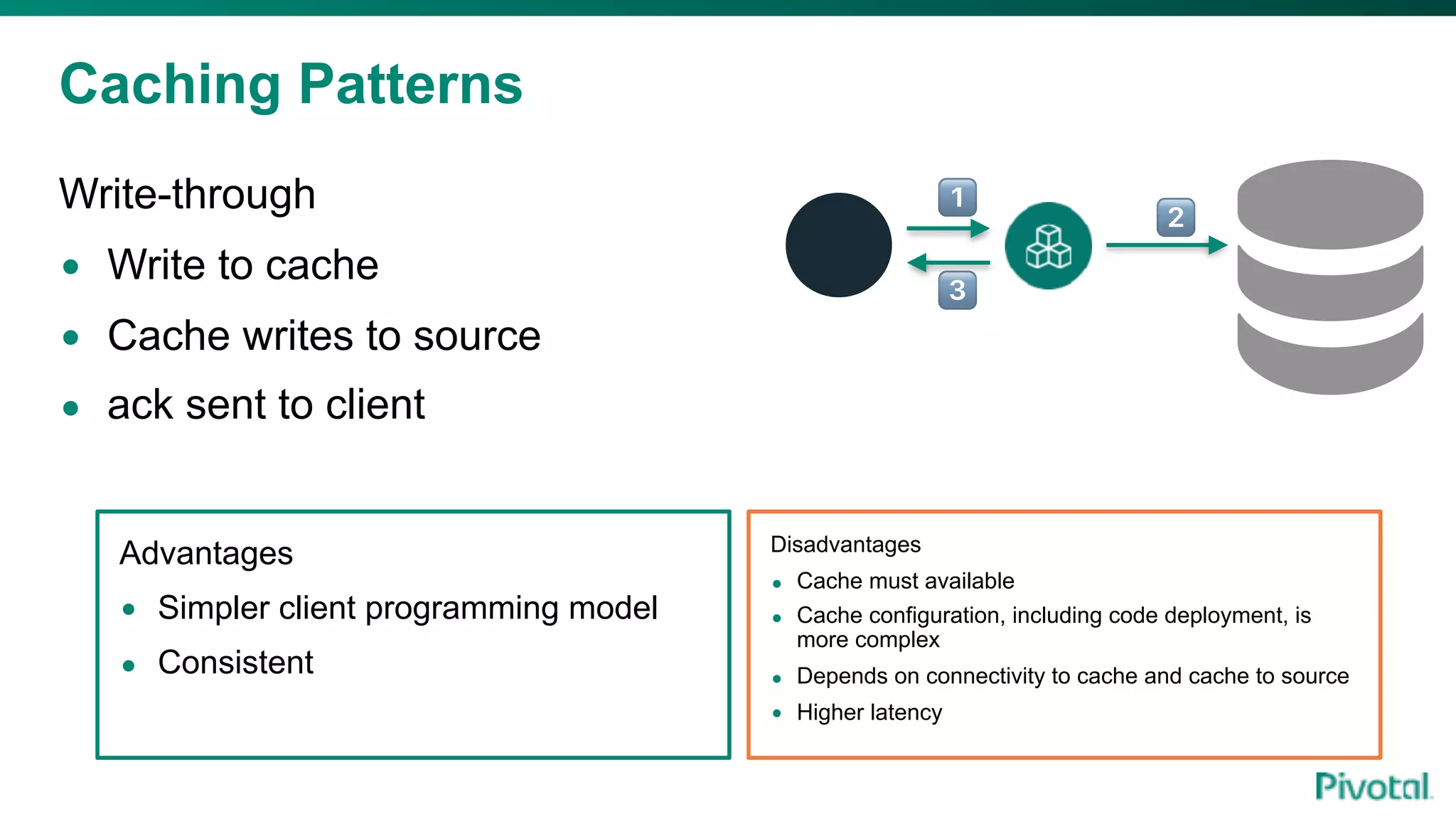
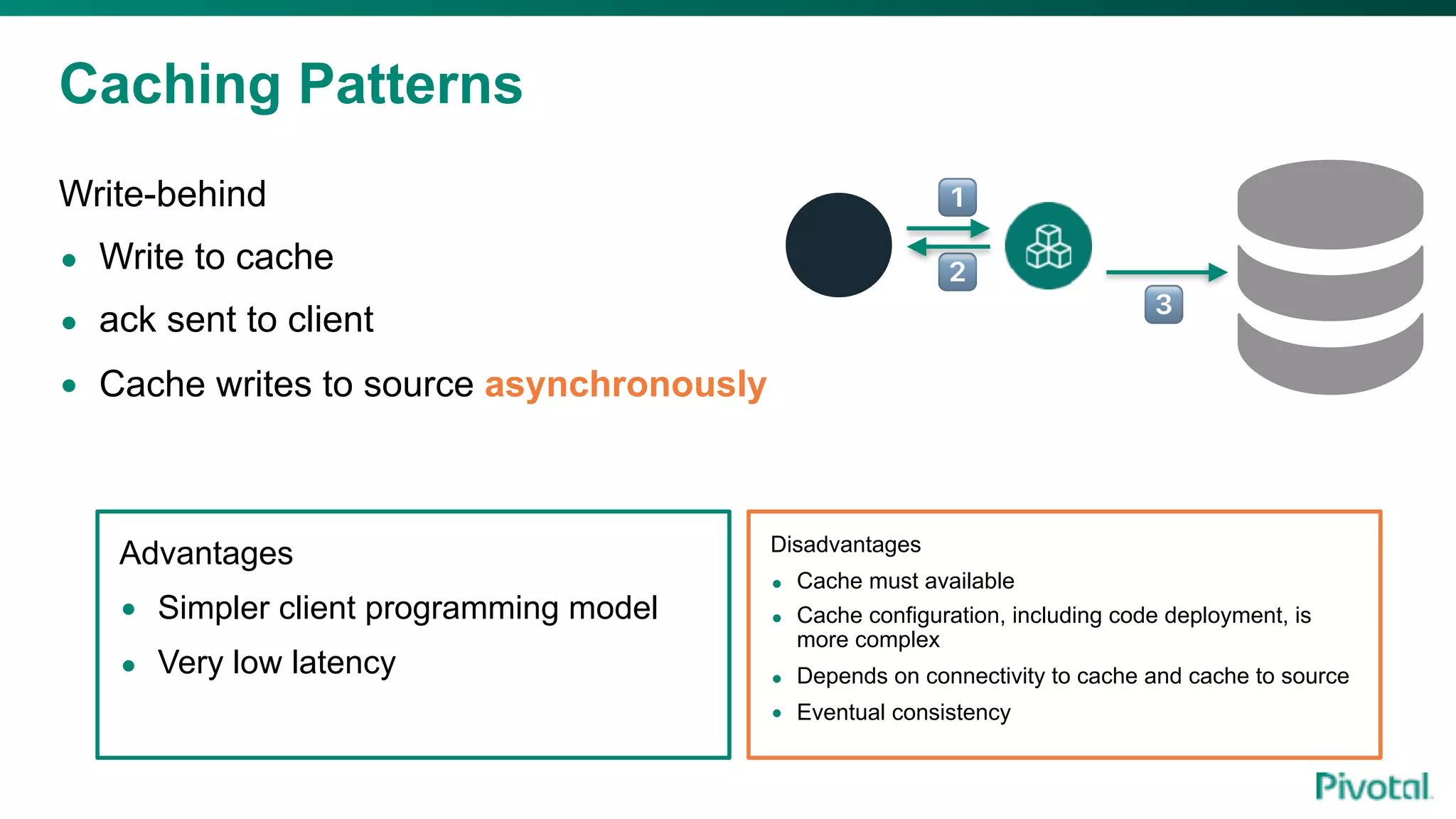
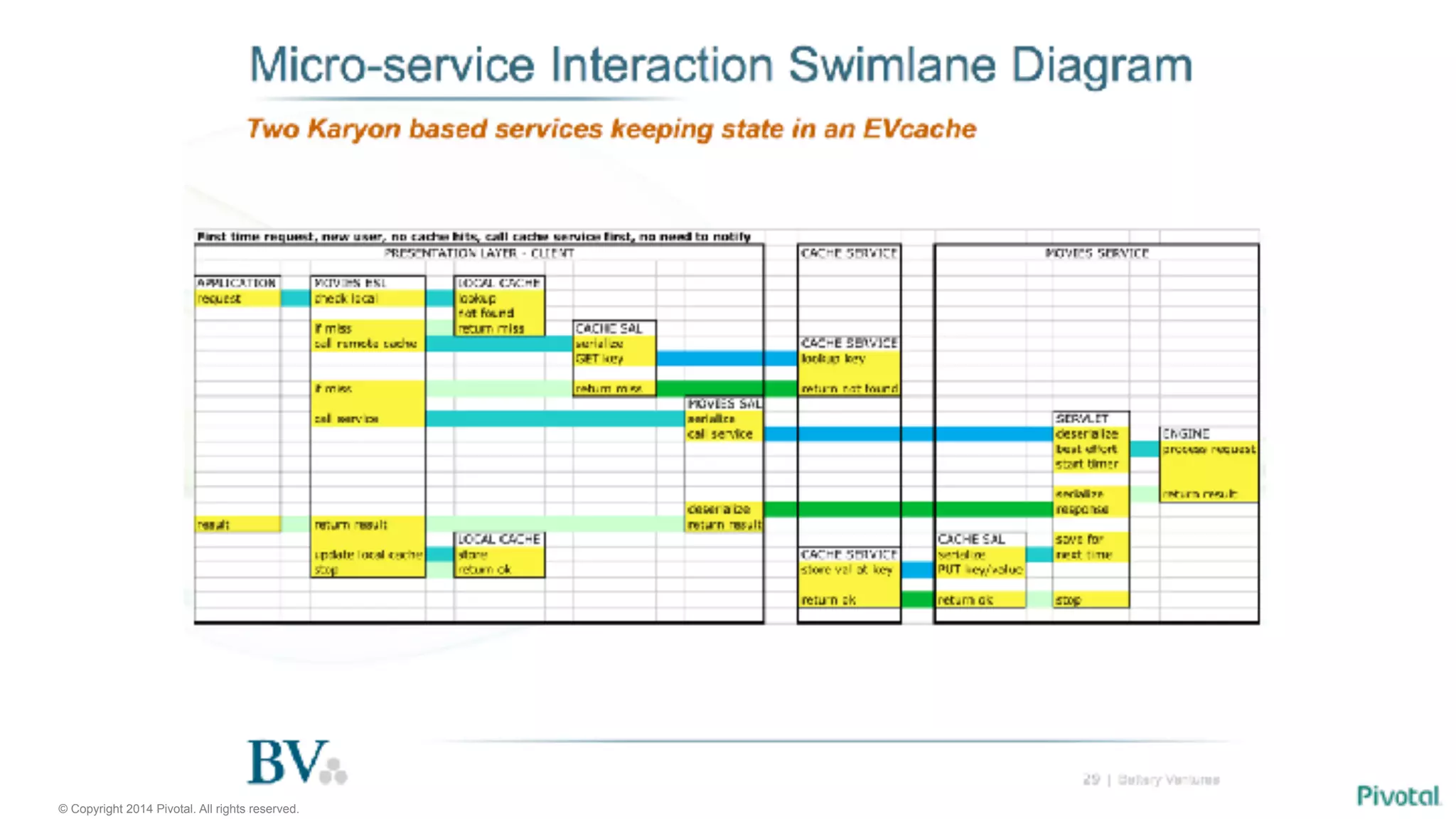
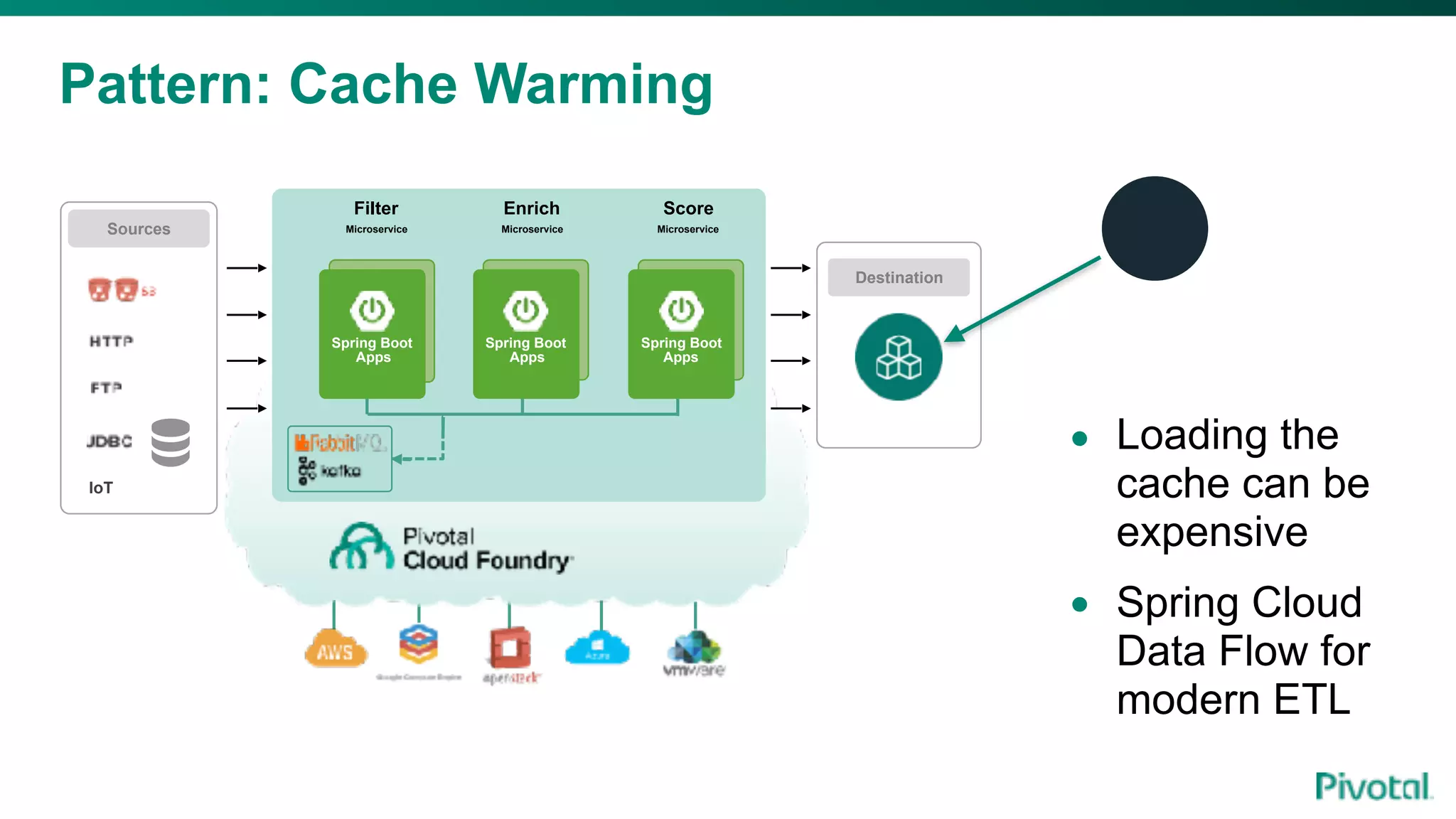

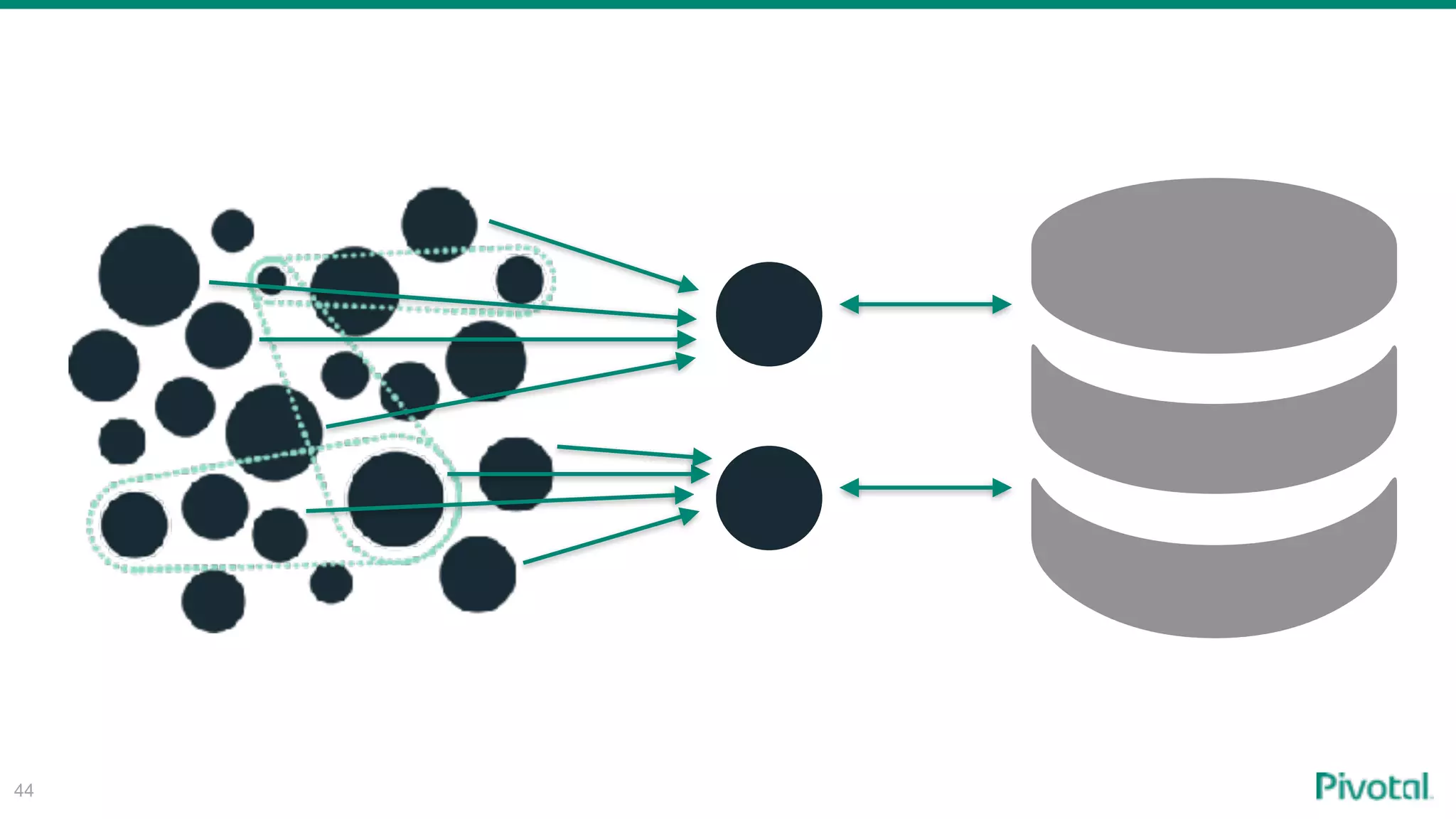

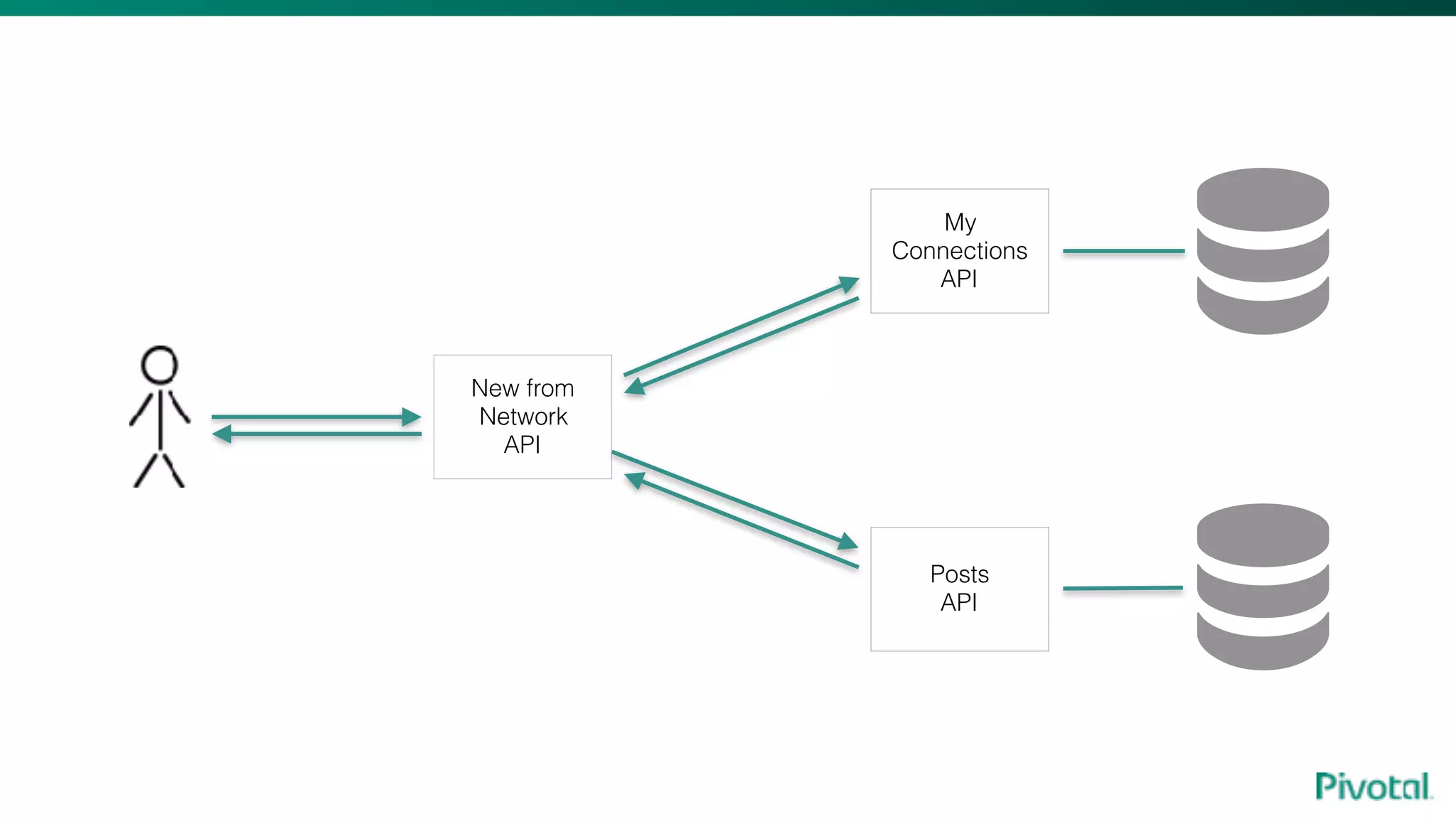
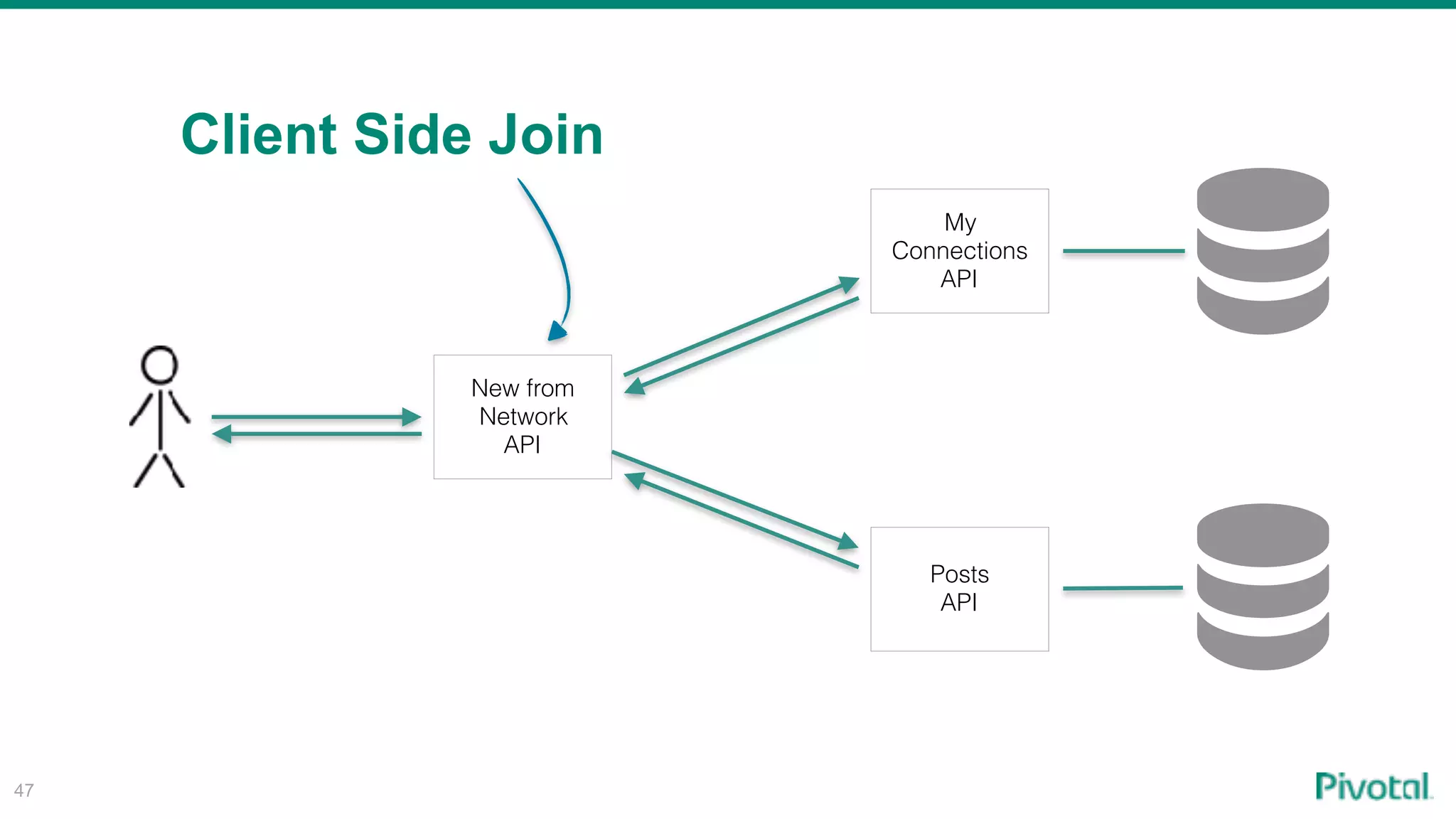
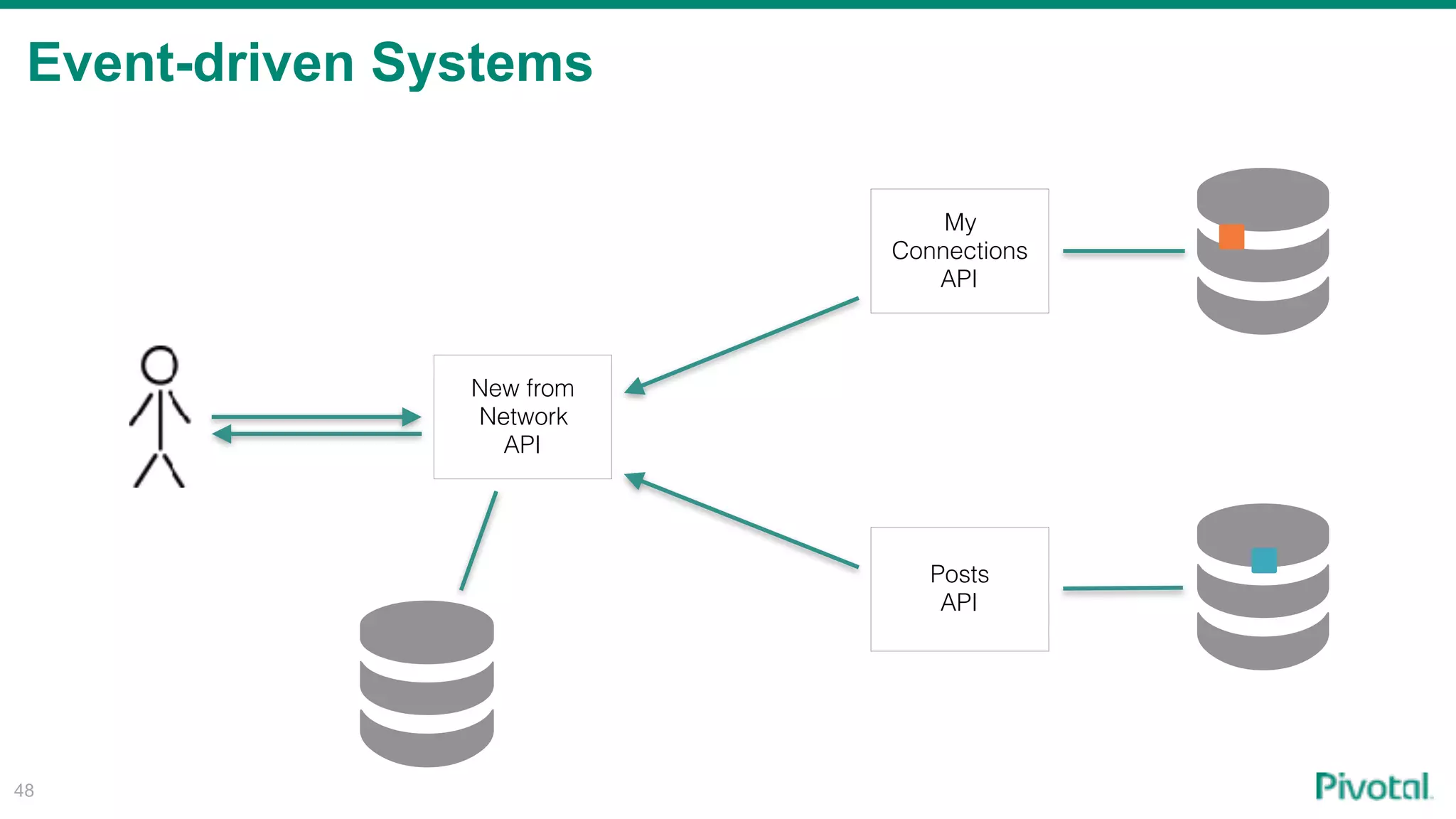
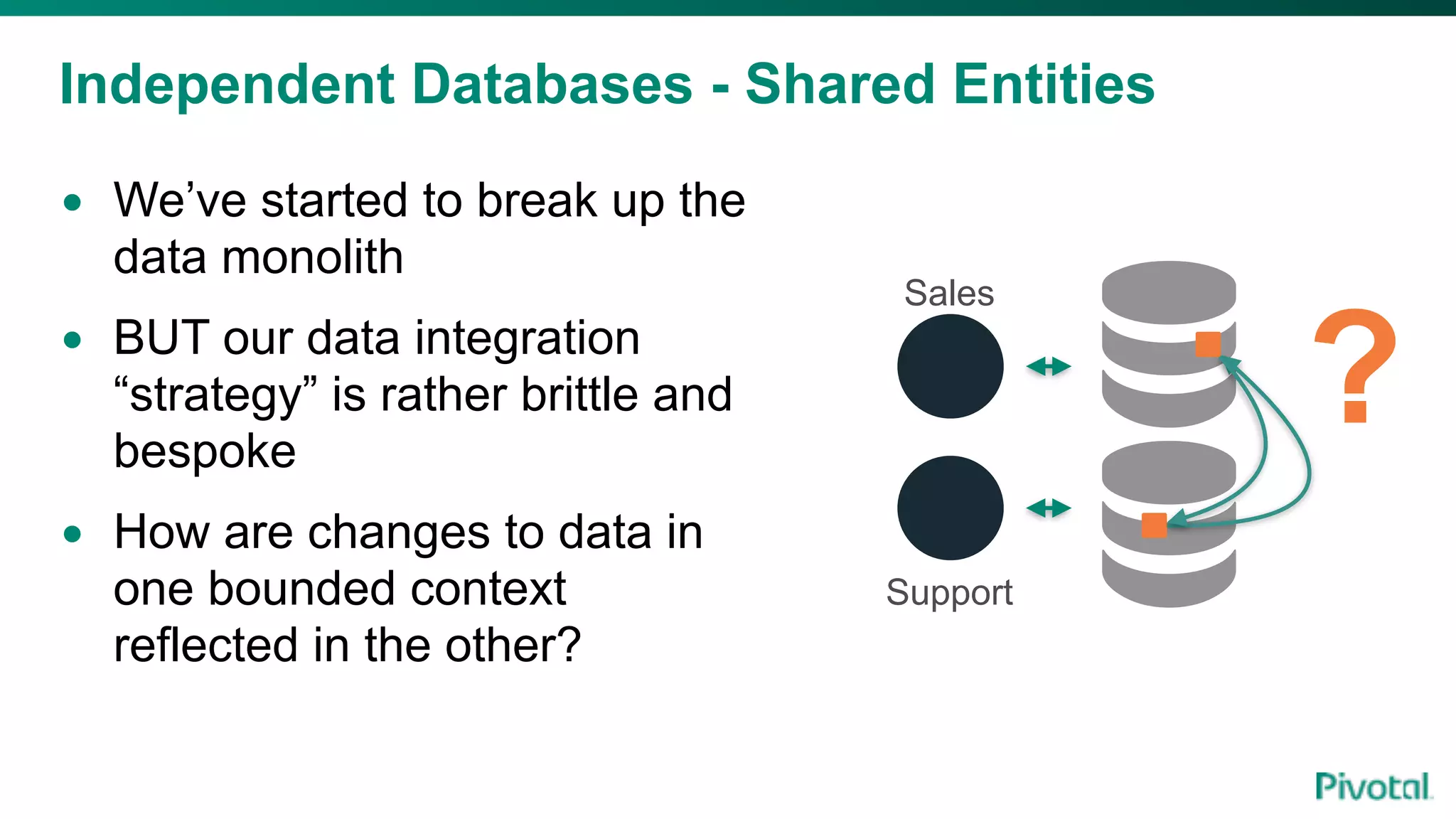
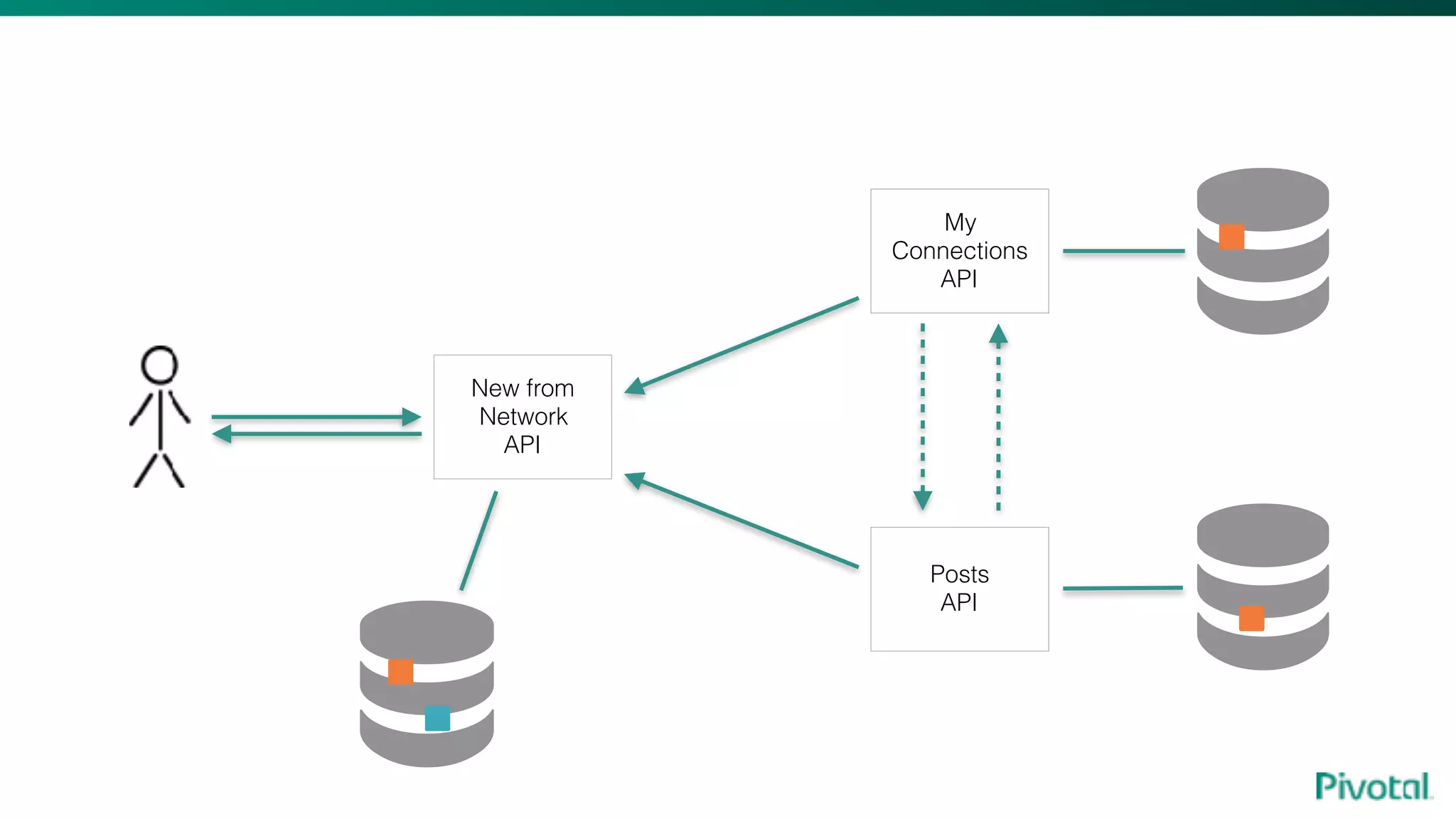
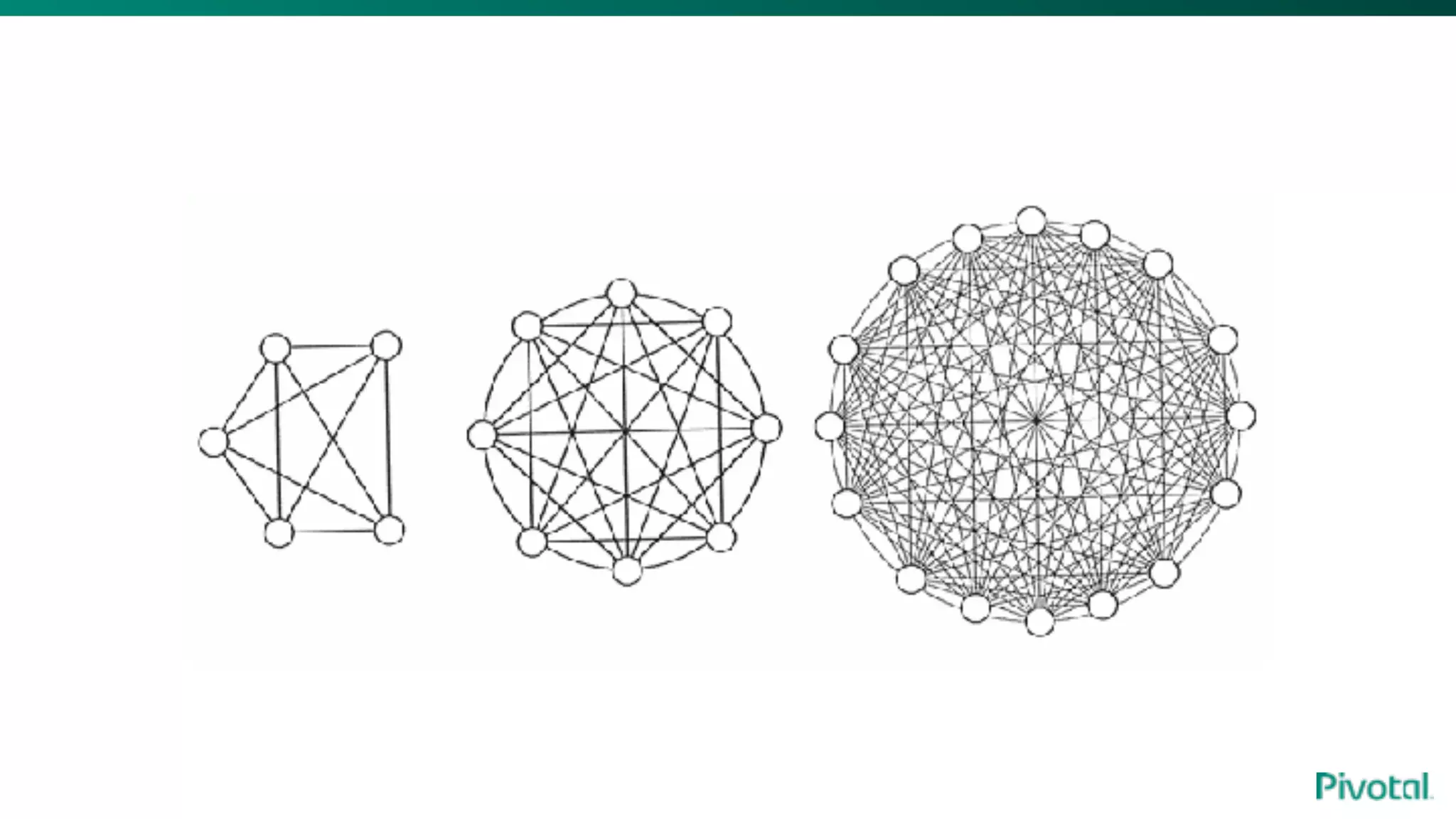

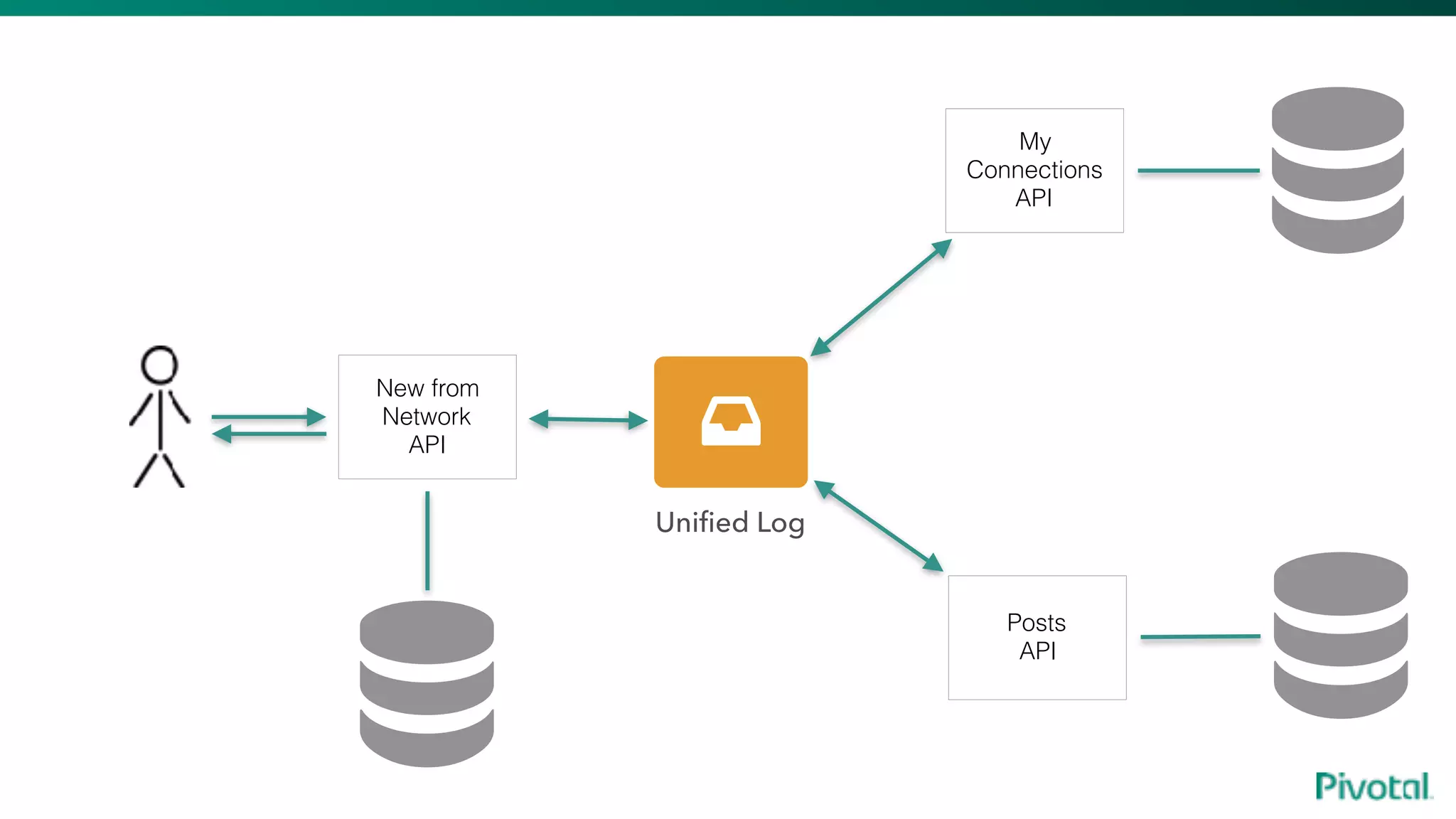
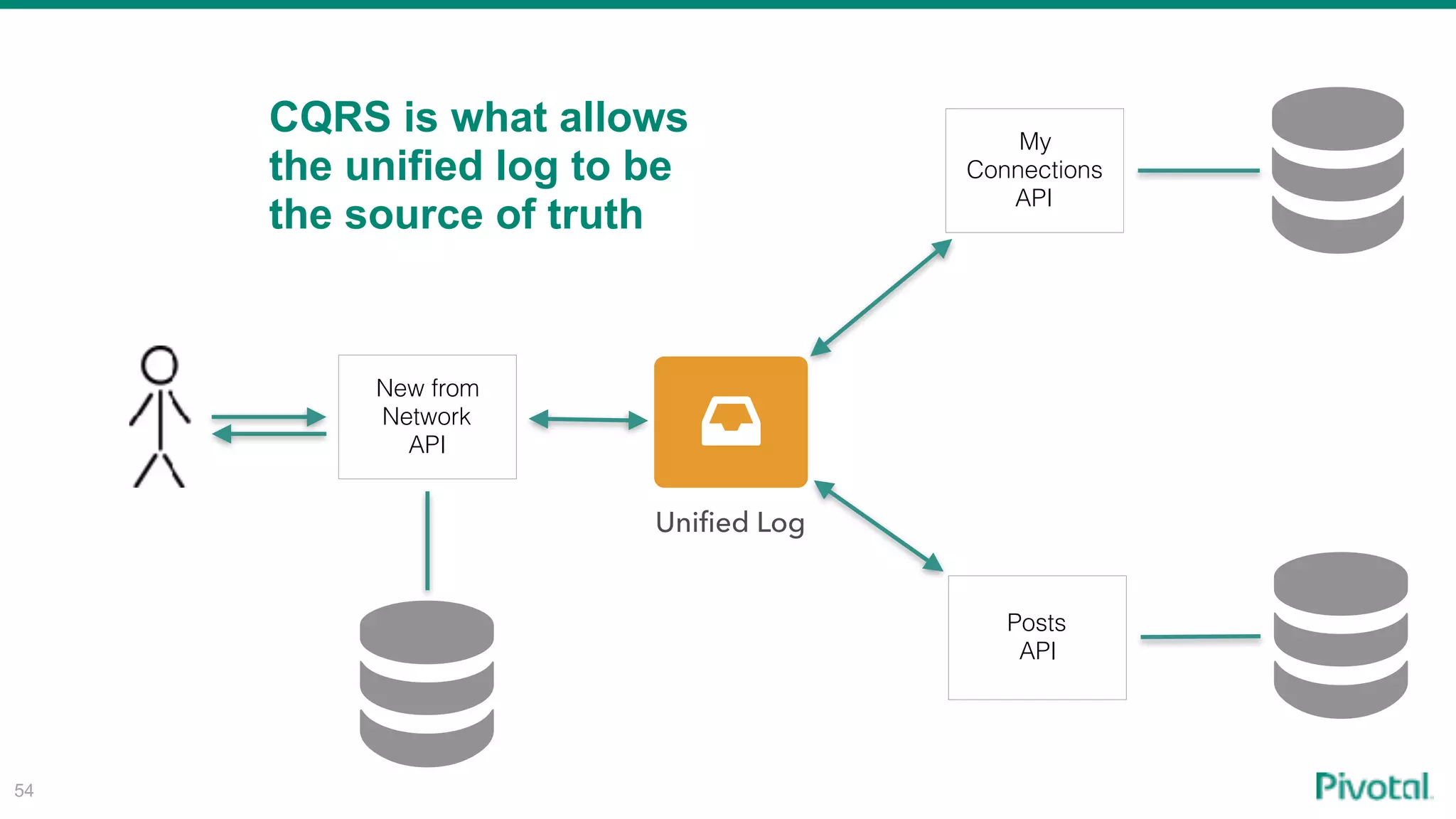

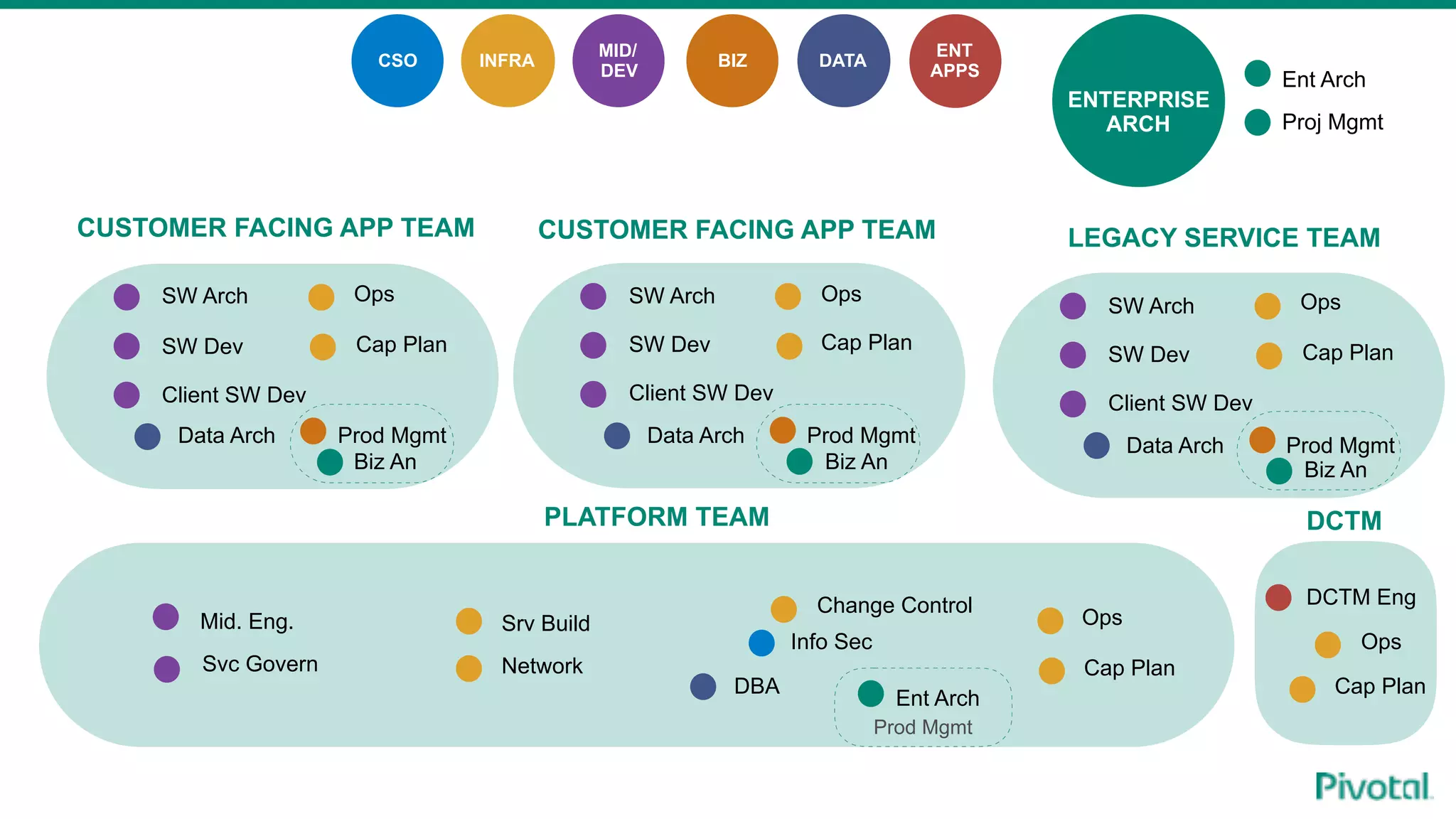

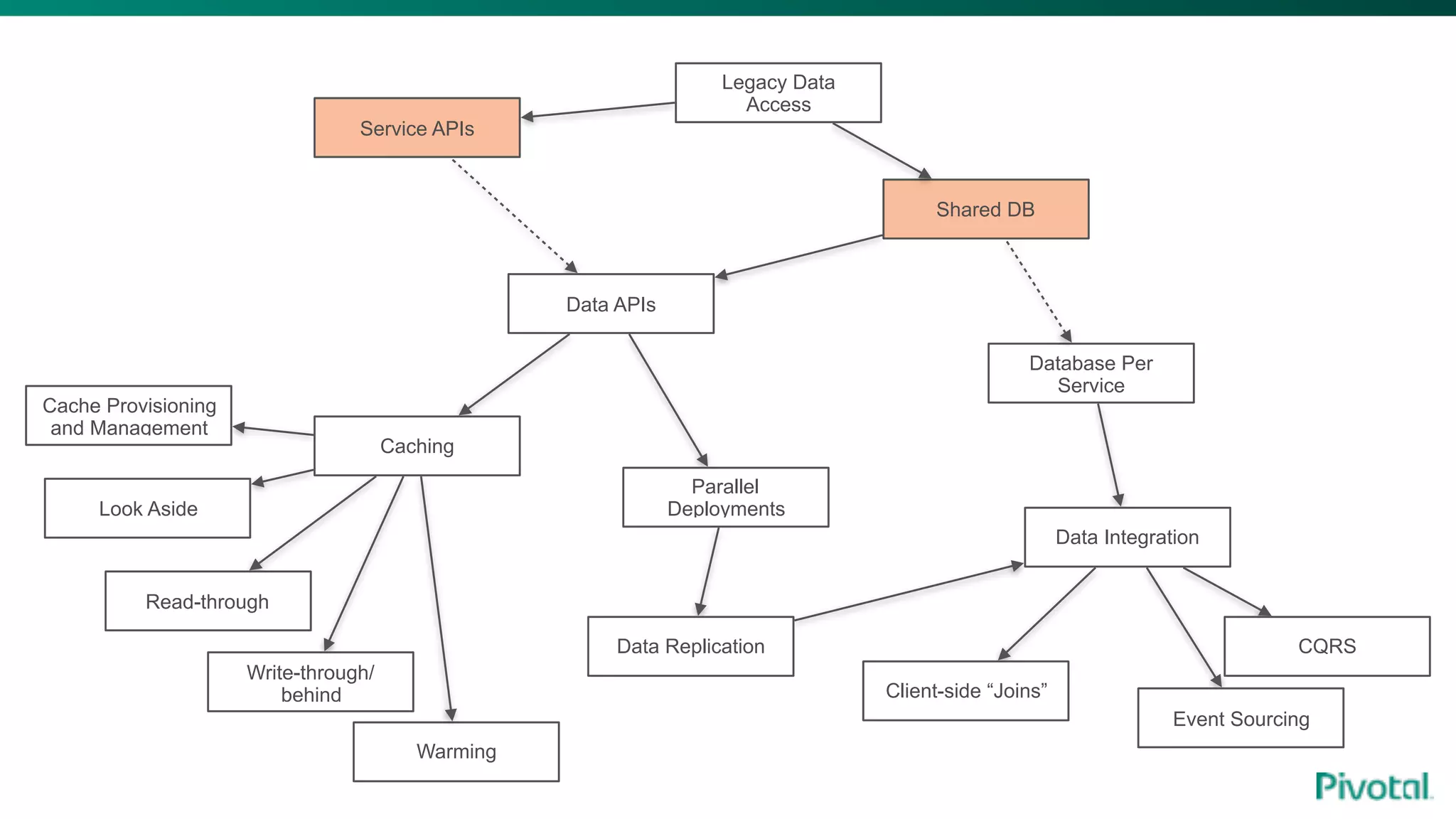




The document discusses the evolution of cloud-native data architecture beyond traditional applications, emphasizing the shift towards microservices for enhanced scalability, resilience, and continuous delivery of value. It outlines challenges like silos in development and operations, and introduces cloud-native patterns such as event sourcing and data APIs to address these issues. Additionally, it highlights the importance of caching strategies and independent databases to improve application performance and agility.











































































