








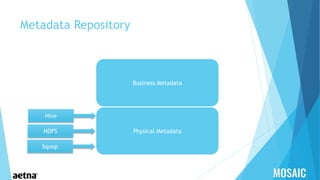
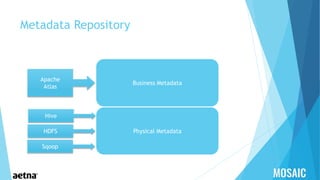
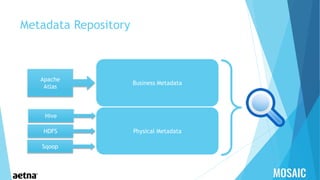

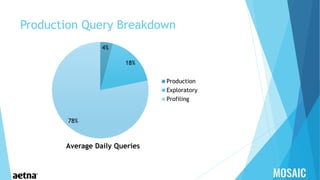








This document provides information about Aetna, a health insurance company. It summarizes that Aetna serves about 46 million customers to help them make healthcare decisions and manage healthcare spending. Aetna offers various medical, pharmacy, dental, life, and disability insurance plans as well as Medicaid services and behavioral health programs. As of March 2015, Aetna had approximately 23.7 million medical members, 15.5 million dental members, and 15.4 million pharmacy members. Aetna works with over 1.1 million healthcare professionals across more than 674,000 primary care doctors and specialists located in 5,589 hospitals across the US and globally.








































![Inspiring Travel at Airbnb [WIP]](https://cdn.slidesharecdn.com/ss_thumbnails/june91205pmairbnbqiancheng-150616222059-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

































































