Download as PDF, PPTX




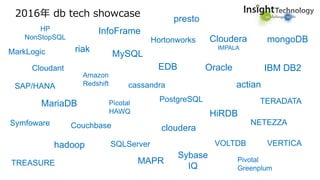
![データも適材適所?! [データベースマッピング]
HiRDB
IBM/DB2
Symfoware
HP NonStop
Oracle
SQL Server
Cloudant
Amazon Redshift
TRESURE DATA
MySQL
PostgreSQL
MariaDB
EDB
Cloudera IMPALA
Presto
HAWQ
MarkLogic
Cassandra Riak
mongoDB Couchbase
MAPR
Cloudera
Hortonworks
Mission
Criticalhadoop Leader Challenger
SQL on Hadoop
Cloud NoSQL
Hadoop
TERADATA
SybaseIQ
Pivotal
VERTICA
NETEZZA
Actian
SAP/HANA
BigData](https://image.slidesharecdn.com/waf1saonq7kghgwbprmc-signature-25a0ea6711cd6aa4d4a08a1137bfd90f9f8e7850cd850623d7101ef7c30a9b4c-poli-161007061148/85/data-analytics-showcase-B16-Live-Demo-by-8-320.jpg)




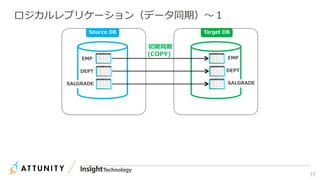
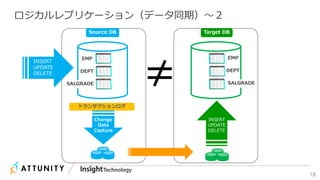


![21
Database ログモードの変更 Command
サプリメンタルロギングを有効化
■データベースレベルの最小サプリメンタルロギングの有効化
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
■テーブル毎のサプリメンタルロギングの有効化
◇プライマリキー有り
ALTER TABLE DEPT ADD SUPPLEMENTAL LOG DATA(PRIMARY KEY)
COLUMNS;
◇プライマリキー無し
ALTER TABLE SALGRADE ADD SUPPLEMENTAL LOG DATA(ALL)
COLUMNS;
PKなしテーブルに対して、
チェンジデータキャプチャを構成
■データベースレベルのCDC有効化
EXEC sys.sp_cdc_enable_db
■テーブル毎のCDC有効化(プライマリキー無しの場合)
EXEC sys.sp_cdc_enable_table
@source_schema = N’[SCHEMAname]’,
@source_name = N’[TABLEname]’,
@role_name = NULL
データ複製に関する追加情報をログに
記録することを有効化
■テーブル毎の変更データキャプチャの有効化
ALTER TABLE < name> DATA CAPTURE CHANGES
トランザクションログにプライマリキー情報を付加
Oracle
SQL Server
IBM/DB2](https://image.slidesharecdn.com/waf1saonq7kghgwbprmc-signature-25a0ea6711cd6aa4d4a08a1137bfd90f9f8e7850cd850623d7101ef7c30a9b4c-poli-161007061148/85/data-analytics-showcase-B16-Live-Demo-by-21-320.jpg)
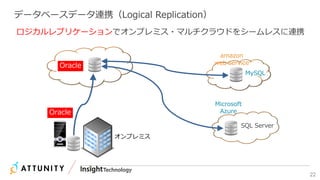
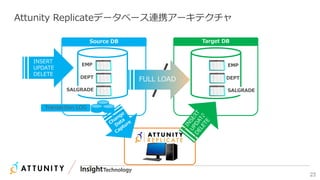
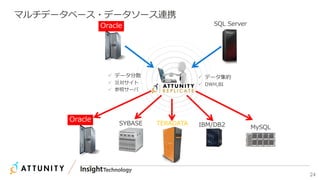


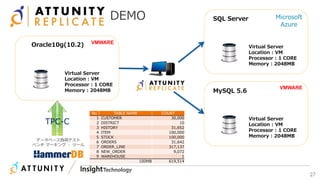




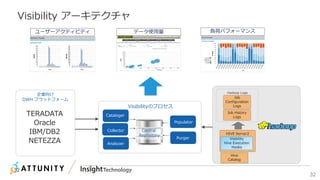
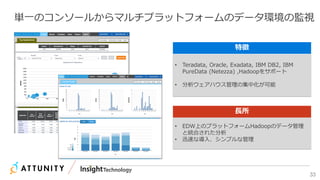
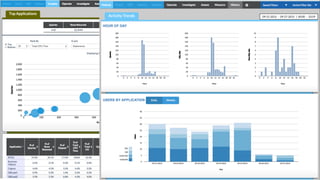
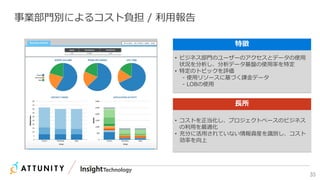
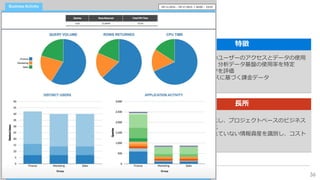
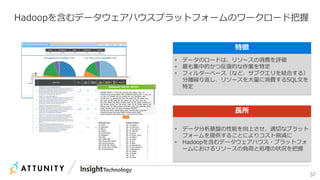

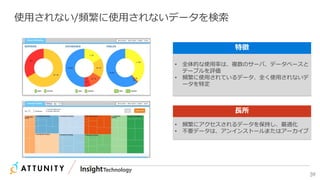
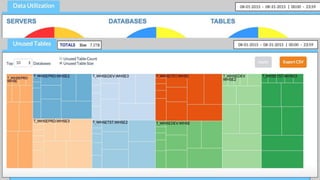




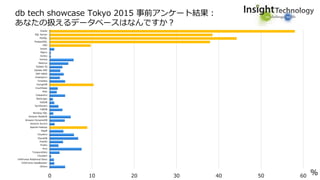
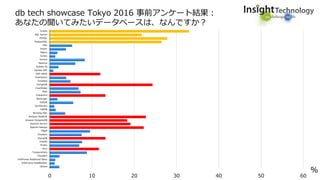
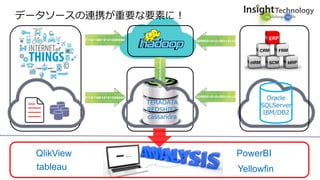
近年のマルチデータベースで構成されるデータ分析基盤では、データベース種別に依存しないオンプレミス内やオンプレミスとクラウド間でのデータ連携が必須となります。本セッションでは、データ連携に関するキーテクノロジー=データレプリケーションテクノロジーについて解説するとともに異種データベース間のデータ連携をAttunity Replicateを使用して、ライブデモでご紹介させていただきます。また、巨大なデータ量を支えるキャパシティプランニングやワークロードアクティビティを簡単に評価できるツールについてもご紹介します。
![[db tech showcase Tokyo 2017] A32: Attunity Replicate + Kafka + Hadoop マルチデータ...](https://cdn.slidesharecdn.com/ss_thumbnails/attunityreplicatekafkahadoop-170911072451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...](https://cdn.slidesharecdn.com/ss_thumbnails/e23-170912023826-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2017] B26: レデータの仮想化と自動化がもたらす開発効率アップとは?by 株式会社インサイトテクノ...](https://cdn.slidesharecdn.com/ss_thumbnails/b26-170912020934-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2017] E24: 流行りに乗っていれば幸せになれますか?数あるデータベースの中から敢えて今Db2が選ば...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017db2ibm-171006012214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] E35: 12台でやってみた!DWHソフトウェアアプライアンス Db2 Warehouse ~...](https://cdn.slidesharecdn.com/ss_thumbnails/e35-2-170913082538-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2017] C25: 世界最速のAnalytic DBがHadoopとタッグを組んだ! ~スケールアウト検...](https://cdn.slidesharecdn.com/ss_thumbnails/c25-170913052337-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b12infoframe-databoosternec-150618053539-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...](https://cdn.slidesharecdn.com/ss_thumbnails/d35-170912024713-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcasetokyo2015e26couchbaseandjbossdatavirtualization-150616073132-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] D33: Deep Learningや、Analyticsのワークロードを加速するには-Ten...](https://cdn.slidesharecdn.com/ss_thumbnails/d33-170912071011-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase OSS 2017] A22: NoSQL:誰のための、何のためのデータベース?その将来は?by Aerospike, ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcaseoss2017aerospike-170621081031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E27: Neo4jグラフデータベース by クリエーションライン株式会社 李昌桓](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015e27neo4jcreationline-150623051314-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] B16:ビッグデータには、なぜ列指向が有効なのか? by 日本ヒューレット・パッカード株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015b16bigdataverticahewletpackard-150918014205-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d13hardwareflashhgst-150629025827-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] A16: Using a Multi-Model Database to Improve Da...](https://cdn.slidesharecdn.com/ss_thumbnails/a16-170913083202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d32in-memorysap-hanahp-150619092635-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] D35:高トランザクションを実現するスケーラブルRDBMS技術 by 日本電気株式会社 並木悠太](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d35infoframe-relational-storenec-150616022508-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2018] #dbts2018 #E37 『Attunity Replicateが変えた Oracle D...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018e37ctc-181004235303-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...](https://cdn.slidesharecdn.com/ss_thumbnails/ist18a-2-180822044642-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018e28hadoopdatalake-181004235141-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Modern Cloud Day Tokyo 2019] 基調講演(Day2):次世代クラウドがもたらす日本のイノベーション](https://cdn.slidesharecdn.com/ss_thumbnails/mcdk2-190826054116-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Modern Cloud Day Tokyo 2019] 次世代型データベース・クラウドの魅力に迫る ~ Autonomous Database Dee...](https://cdn.slidesharecdn.com/ss_thumbnails/mcd19e-3-190826045623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] A15: レプリケーションを使用したデータ分析基盤構築のキモ(事例)by 株式会社インサイトテ...](https://cdn.slidesharecdn.com/ss_thumbnails/a15-170912020524-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db analytics showcase Sapporo 2017] B27:世界最速のAnalytic DBはHadoopの夢を見るか by 株式会...](https://cdn.slidesharecdn.com/ss_thumbnails/dbas20170701-170707082516-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2018] #dbts2018 #C17 『OracleからPostgreSQLへ移行する際のポイントとレ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018c17quest-180929165135-thumbnail.jpg?width=640&height=640&fit=bounds)

















![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)

