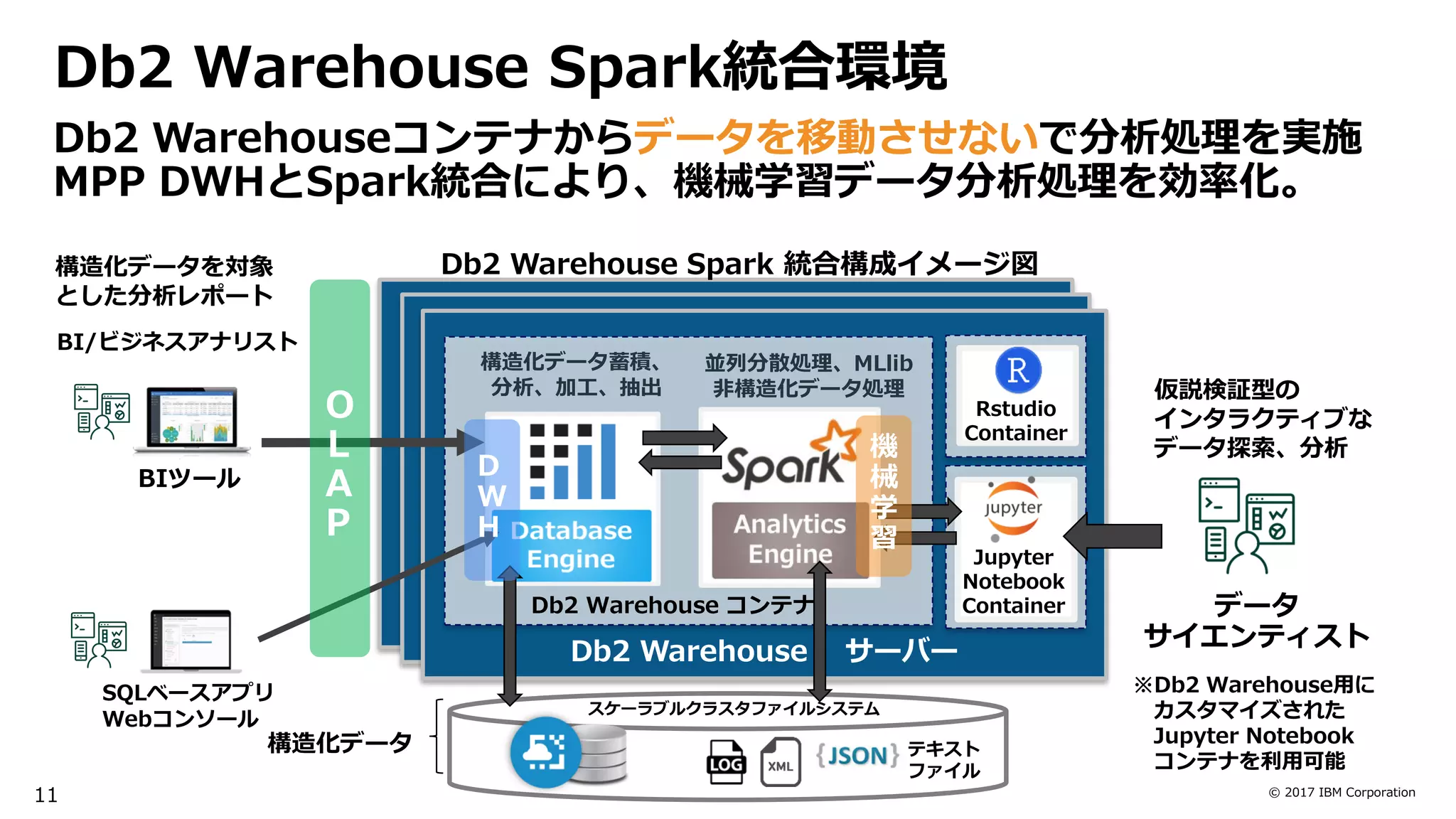
What is Db2Warehouse ?
Db2 Warehouse
Container
Download and Deploy
Any Public and Private Cloud
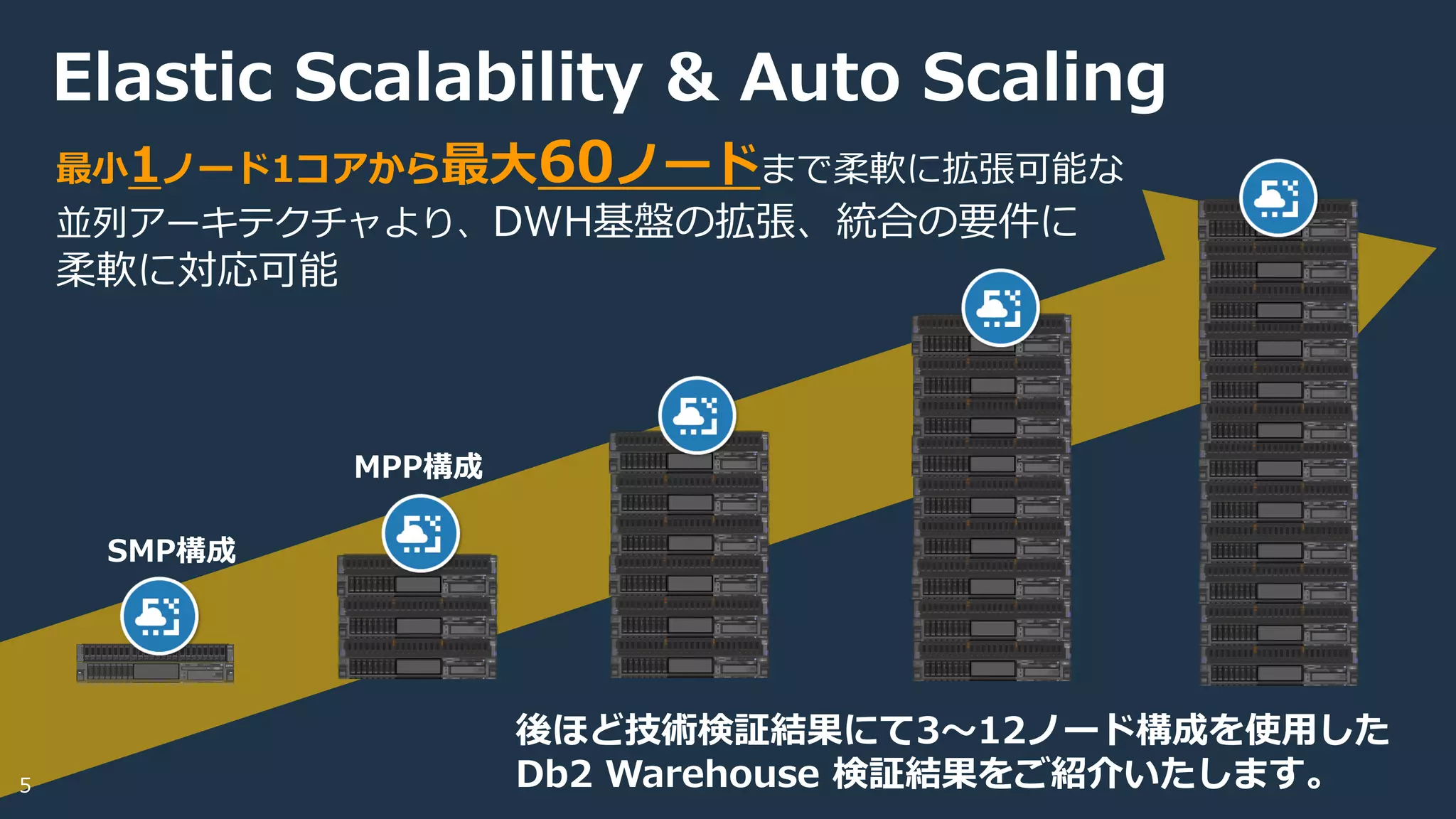
Elastic Scalability
・最大60ノードまで拡張可能なスケーラビリティ
・スケールアップ & アウト自動チューニング
・データベースサイズの柔軟な拡張
3
Load and Go
・コンテナをデプロイ後、直ぐにDB利用可能。予め分析用途に
最適化され、物理設計、インデックスチューニング不要。
データロード後すぐに分析できる簡易性。
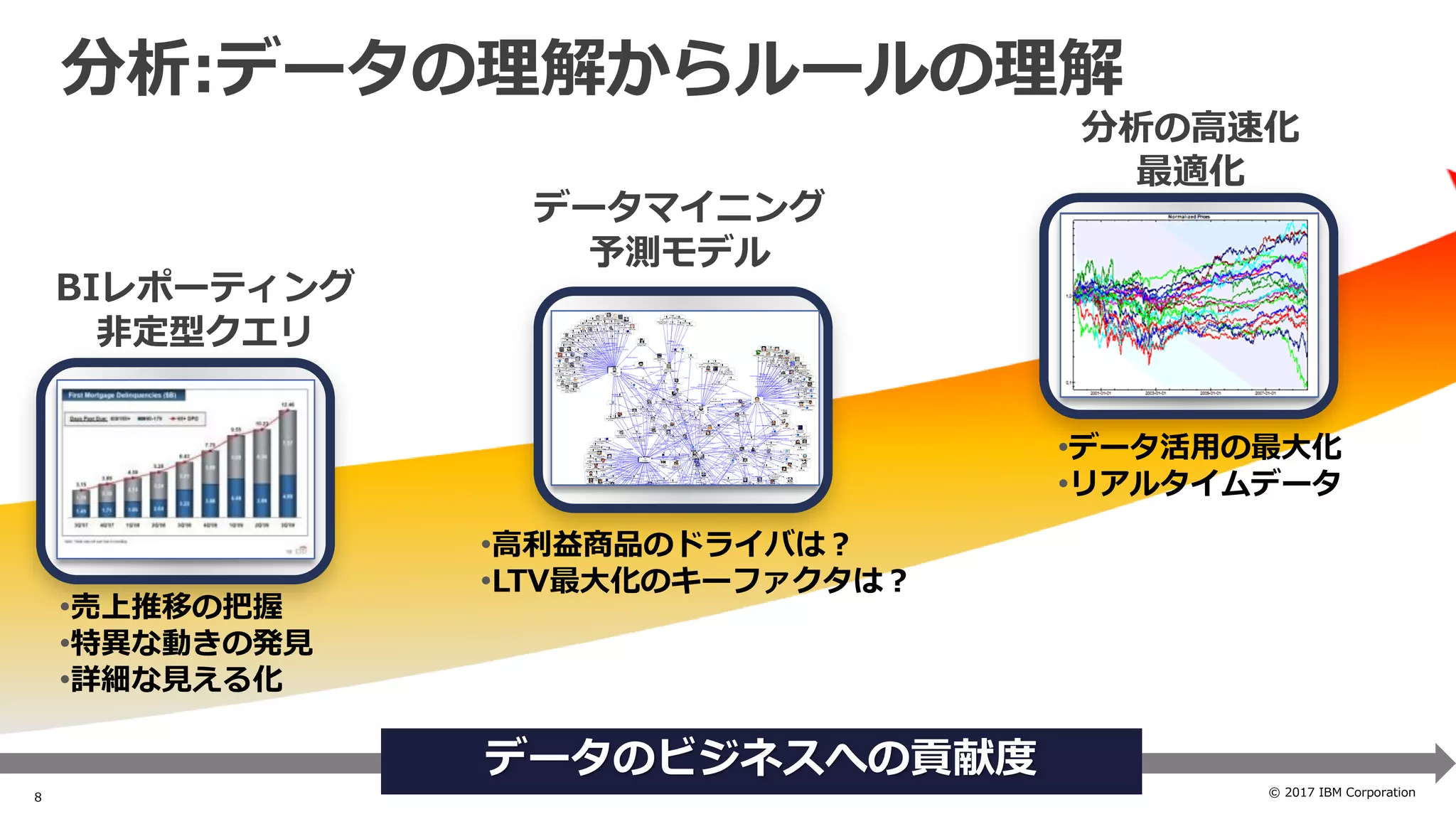
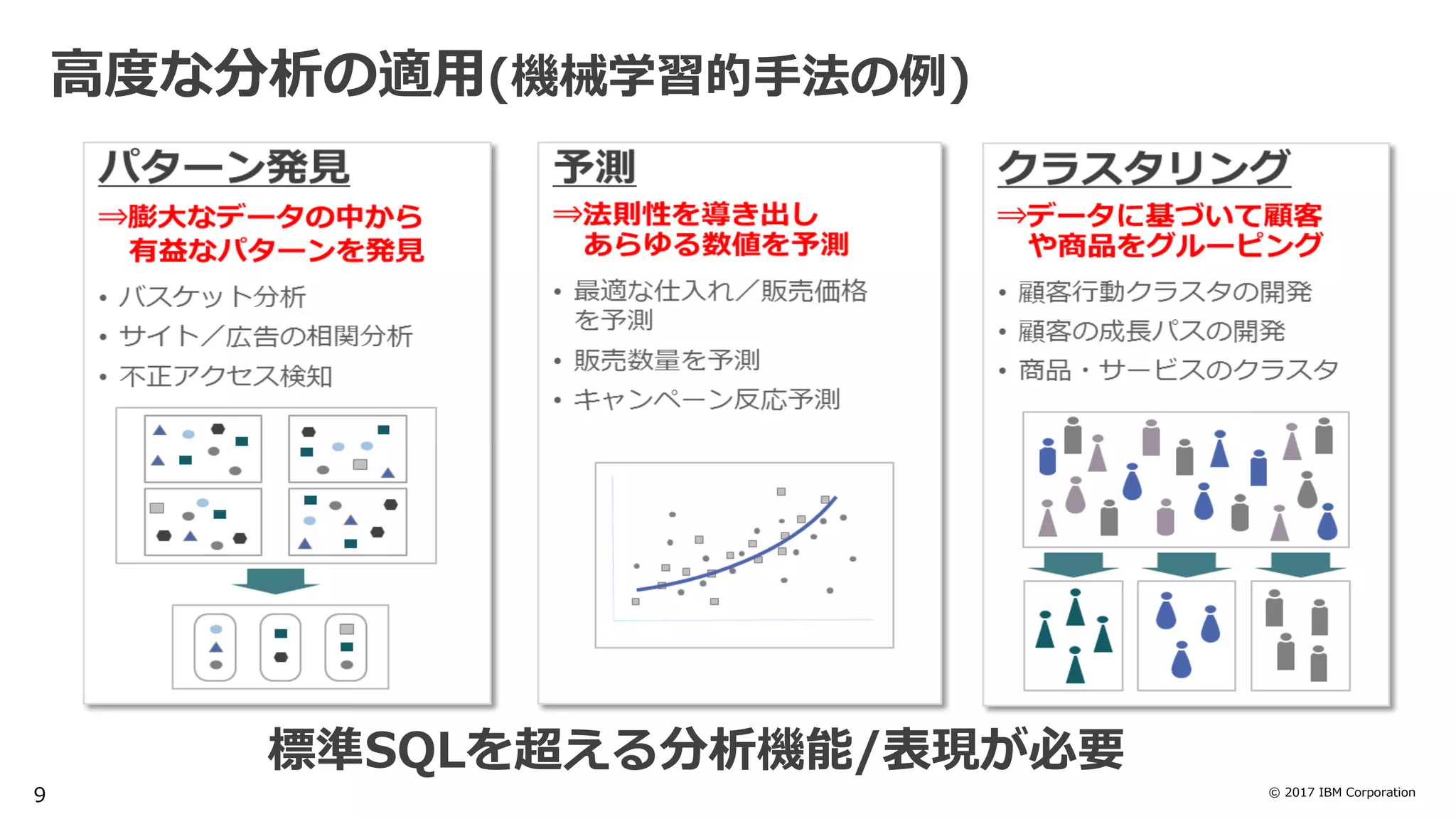
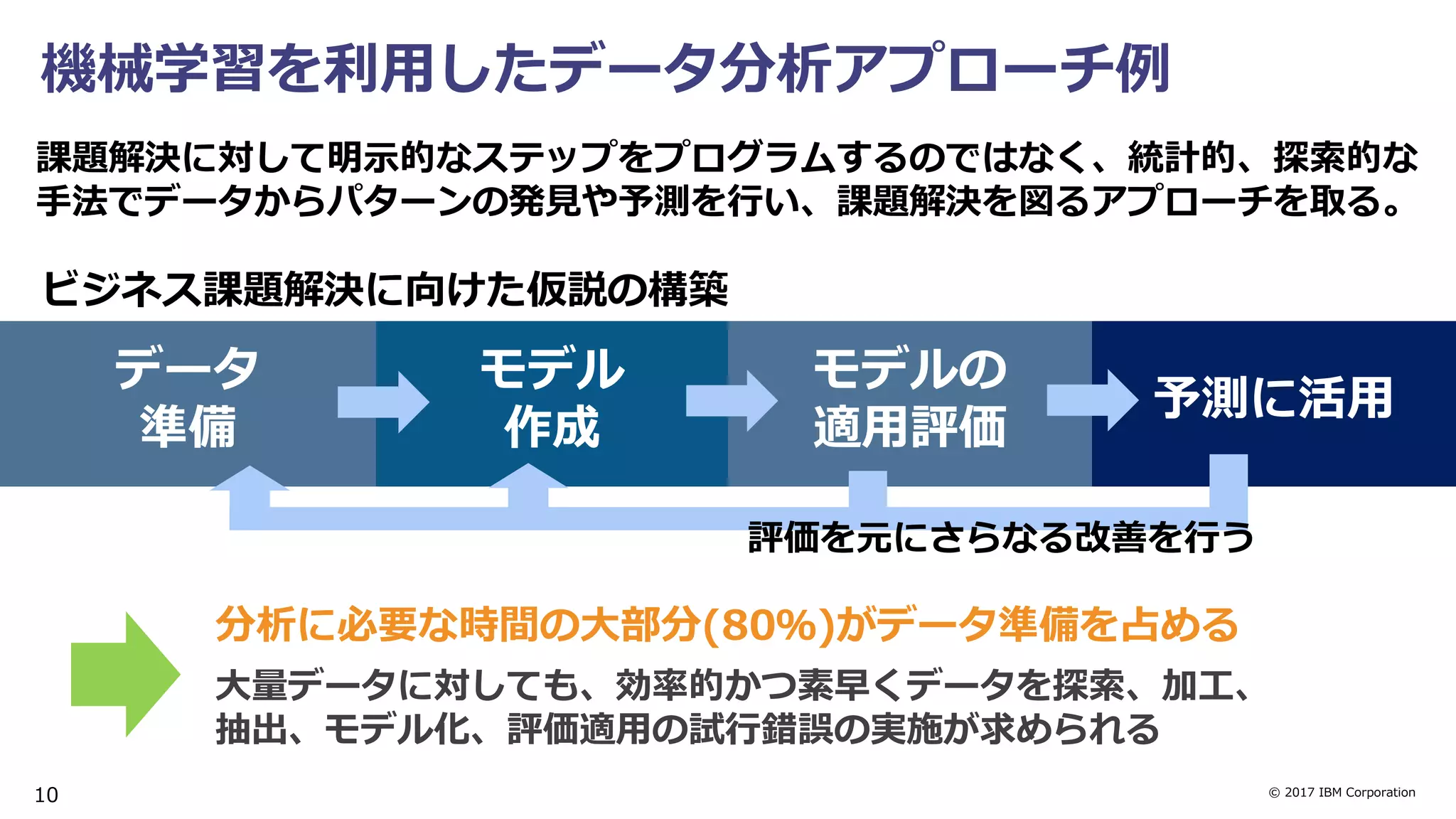
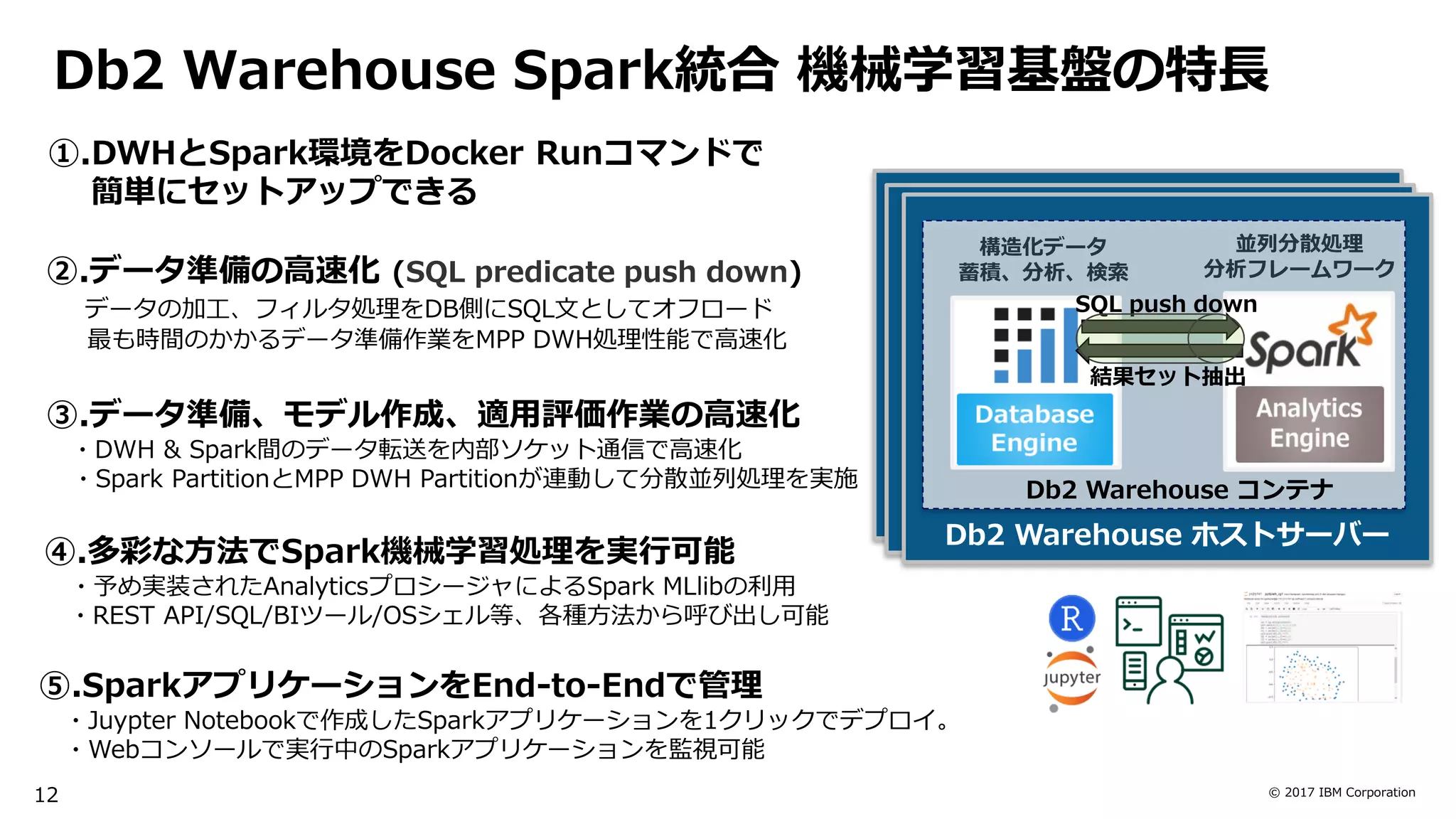
High Speed & Machine Learning
・インメモリカラムストア & MPPアーキテクチャ
・列圧縮、検索対象外データの読み飛ばし(データスキッピング)
・DWH & Spark統合による機械学習処理の効率化
4.
What is Db2Warehouse ?
Write Once, Run Anywhere
・Common SQL Engine, Netezza & Oracle互換機能
・Dockerコンテナポータビリティ
・プライベートクラウド、マルチクラウド対応
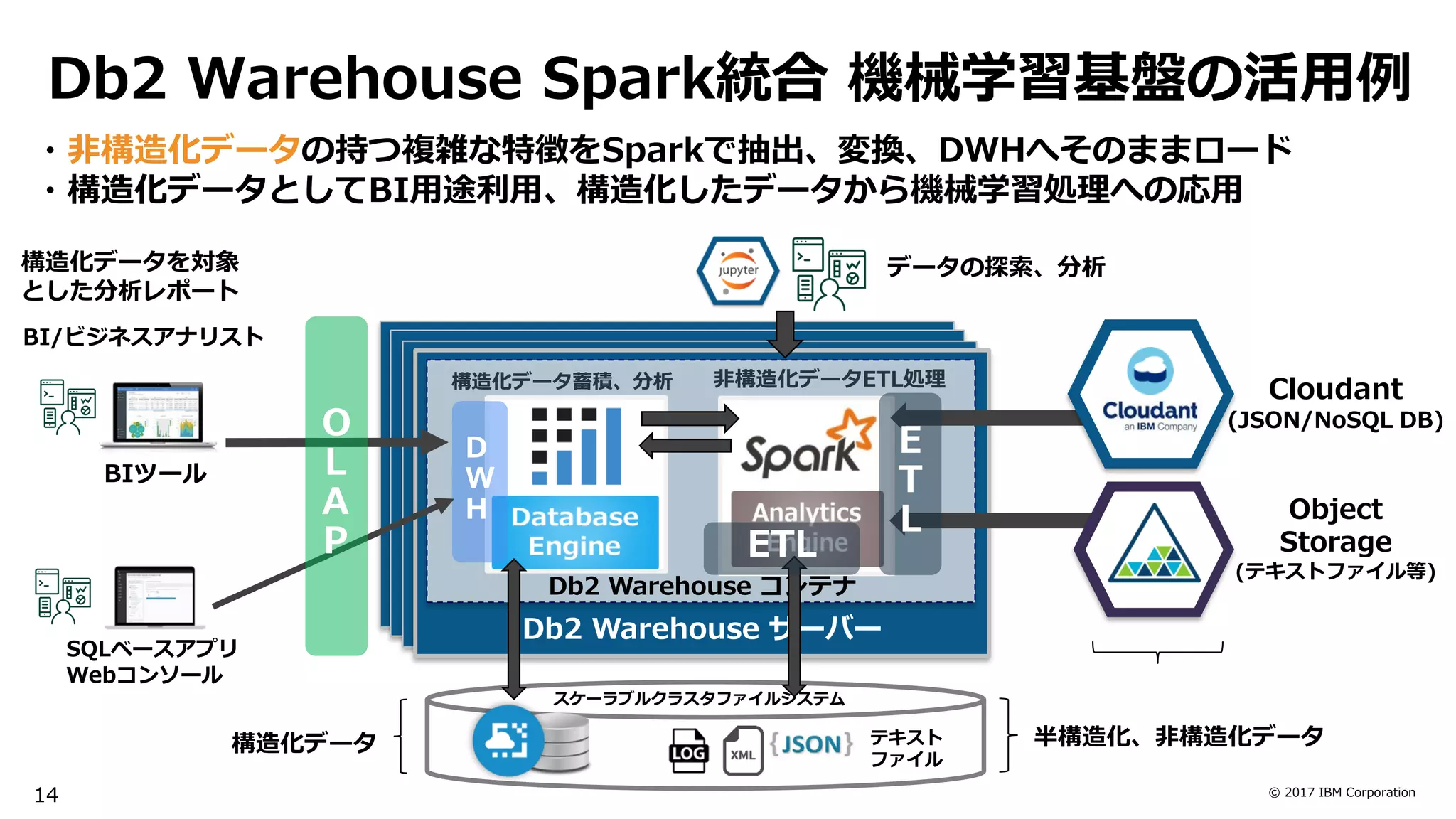
Data Virtualization & Move
・FluidQueryによるRDB, Hadoopとのデータ連携
・DB Migrationによる高速データ移動
(Netezza->Db2 Wh, Db2 Wh ->Db2 Wh)
Flexible Price & Low TCO
・クラウド利用を想定したVPC単位の月額ライセンス課金
・開発、運用管理コスト低減によるTCO低減
1月 12月
Oracle Netezza SQLserver
Db2 Family & Hadoop
Powered by FluidQuery
4






![© 2017 IBM Corporation
DB
Coordinator
Spark Driver
Jupyter Server
Data
Partition
s
Worker
DB
Data
Nod
es
Cluster Mgr
Master
Executor
Worker
Executor
Worker
Executor
Worker
Executor
ML SP &
Submit SP
Client App
DB
Data
Nod
es
DB
Data
Nod
es
DB
Data
Nod
es
DB
Data
Nod
es
DB
Data
Nod
es
DB
Data
Nod
es
DB
Data
Nod
es
Data
Partition
s
Data
Partitions
Data
Partition
s
Data
Partition
s
Data
Partitions
Data
Partition
s
Data
Partition
s
Data
Partitions
Data
Partition
s
Data
Partition
s
Data
Partitions
DB
Data
Nodes
DB
Data
Nodes
DB
Data
Nodes
DB
Data
Nodes
Spark Kernels
Head Node
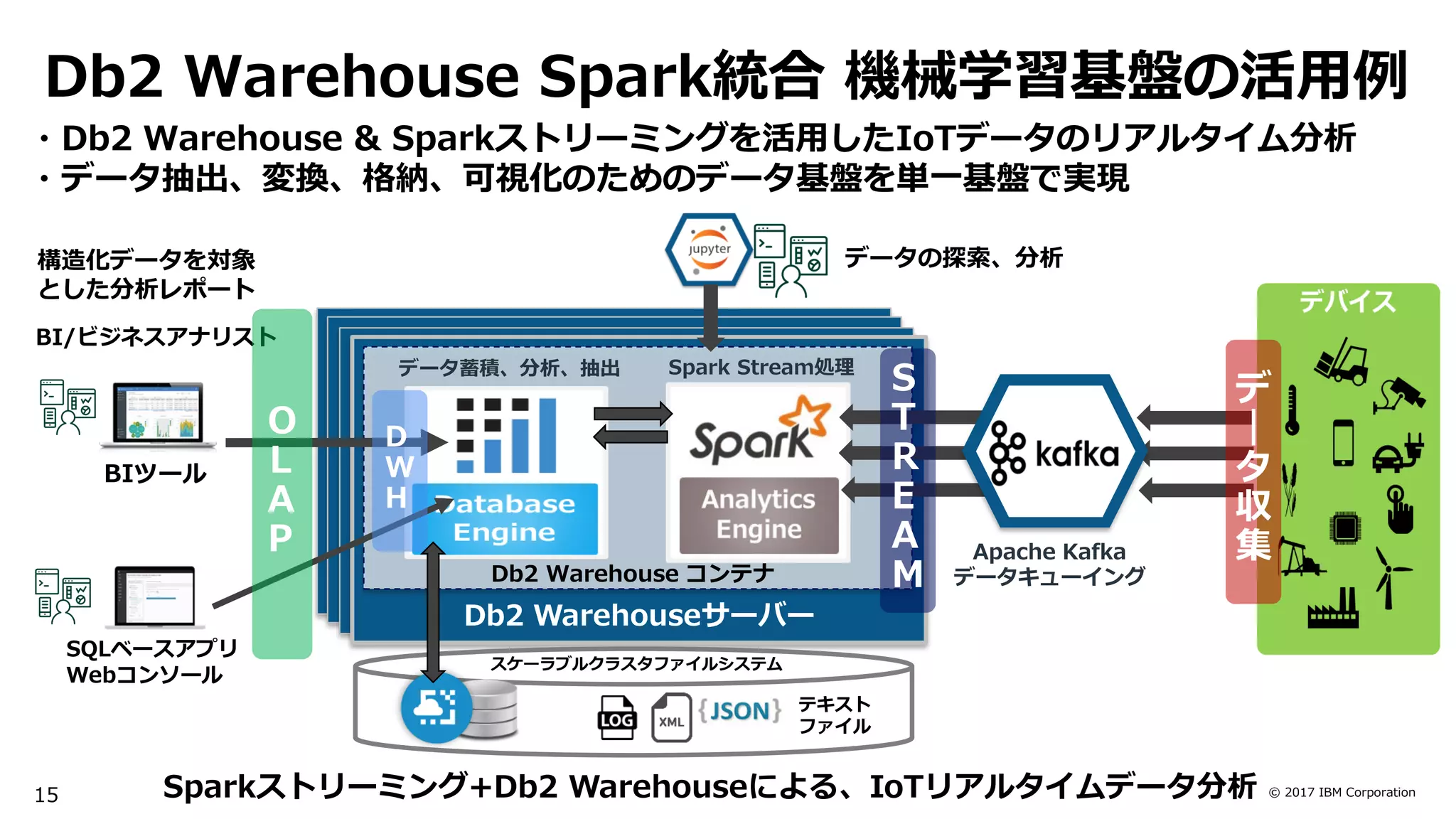
参考: Db2 Warehouse with Spark ハイレベルアーキテクチャ
Data Node
[Spark Apps実行方法]
1.Spark-submit.sh
2.Submit Stored Procedure
3.ML Stored Procedure
4.REST API
5.Jupyter Notebook
Data
Partition
s
DB
Data
Nod
es
DB
Data
Nod
es
Data
Partition
s
Data
Partitions
DB
Data
Nodes
Worker
Executor
Db2 Warehouse
Web Console
13](https://image.slidesharecdn.com/e35-2-170913082538/75/db-tech-showcase-Tokyo-2017-E35-12-DWH-Db2-Warehouse-DWH-Docker-Spark-by-13-2048.jpg)







![[db tech showcase Tokyo 2017] E24: 流行りに乗っていれば幸せになれますか?数あるデータベースの中から敢えて今Db2が選ば...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017db2ibm-171006012214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] B16:ビッグデータには、なぜ列指向が有効なのか? by 日本ヒューレット・パッカード株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015b16bigdataverticahewletpackard-150918014205-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...](https://cdn.slidesharecdn.com/ss_thumbnails/d35-170912024713-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[data analytics showcase] B16: Live Demo! データ分析基盤を支えるデータレプリケーション技術とデータワークロード分...](https://cdn.slidesharecdn.com/ss_thumbnails/waf1saonq7kghgwbprmc-signature-25a0ea6711cd6aa4d4a08a1137bfd90f9f8e7850cd850623d7101ef7c30a9b4c-poli-161007061148-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D35:高トランザクションを実現するスケーラブルRDBMS技術 by 日本電気株式会社 並木悠太](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d35infoframe-relational-storenec-150616022508-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] C25: 世界最速のAnalytic DBがHadoopとタッグを組んだ! ~スケールアウト検...](https://cdn.slidesharecdn.com/ss_thumbnails/c25-170913052337-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] E34: データベース・サービスを好きなところで動かそう Db2 Warehouse by 日...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017e34-170911070313-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcasetokyo2015e26couchbaseandjbossdatavirtualization-150616073132-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b12infoframe-databoosternec-150618053539-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...](https://cdn.slidesharecdn.com/ss_thumbnails/e23-170912023826-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E27: Neo4jグラフデータベース by クリエーションライン株式会社 李昌桓](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015e27neo4jcreationline-150623051314-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] AzureでOSS DB/データ処理基盤のPaaSサービスを使ってみよう (Azure Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/20170907dbtechshowcaseazureossdb-170907082746-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2017] A32: Attunity Replicate + Kafka + Hadoop マルチデータ...](https://cdn.slidesharecdn.com/ss_thumbnails/attunityreplicatekafkahadoop-170911072451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d13hardwareflashhgst-150629025827-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] D33: Deep Learningや、Analyticsのワークロードを加速するには-Ten...](https://cdn.slidesharecdn.com/ss_thumbnails/d33-170912071011-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] B22: DevOpsにおけるDelphix(デルフィックス)by Delphix Softw...](https://cdn.slidesharecdn.com/ss_thumbnails/b22-170920002542-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DI03] DWH スペシャリストが語る! Azure SQL Data Warehouse チューニングの勘所](https://cdn.slidesharecdn.com/ss_thumbnails/di03-170605023803-thumbnail.jpg?width=640&height=640&fit=bounds)










![[db tech showcase Tokyo 2017] E35: 12台でやってみた!DWHソフトウェアアプライアンス Db2 Warehouse ~...](https://cdn.slidesharecdn.com/ss_thumbnails/e35-170913052338-thumbnail.jpg?width=640&height=640&fit=bounds)









![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)















