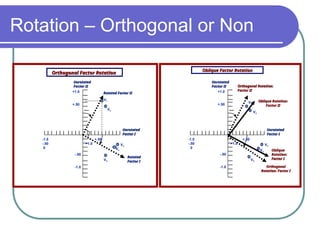
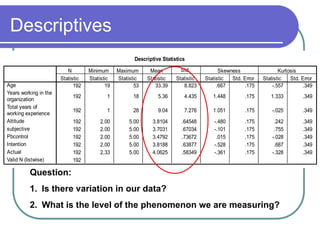
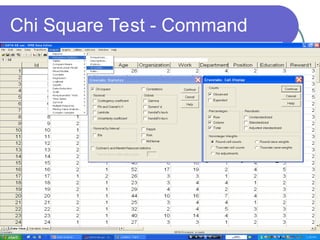
The document provides a comprehensive overview of data analysis, covering fundamental concepts such as levels of measurement, various types of variables, and key terms. It details the data analysis process, including stages like data entry, error checking, and transformation, alongside statistical methods for hypothesis testing. Additionally, it addresses reliability and validity of measurement instruments through factor analysis and reliability statistics.




















































































![Benchmark for Comparison
How good is the Hit Ratio? Compute Hit Ratio for
split sample and compare it against
Maximum Chance Criterion: This is just the size of the largest
group. Minimum criterion to be met by the Hit Ratio
Proportional Chance Criterion: Should be used when group sizes
are unequal. If two groups this is given as follows:
Cpro = p2 + (1 - p)2 p = proportion in group
Press’s Q: Compares No. of correct classification (n) against Total
Sample (N) and Number of Groups (k)
Press Q 2
with 1 degree of freedom. (3.84, 6.64)
1)
-
N(k
k)]
*
(n
-
[N
Q
Press
2
](https://image.slidesharecdn.com/editing-240914070855-54421498/85/DATA-ANALYSIS-PRESENTATION-FOR-REVISION-88-320.jpg)























































