Downloaded 15 times








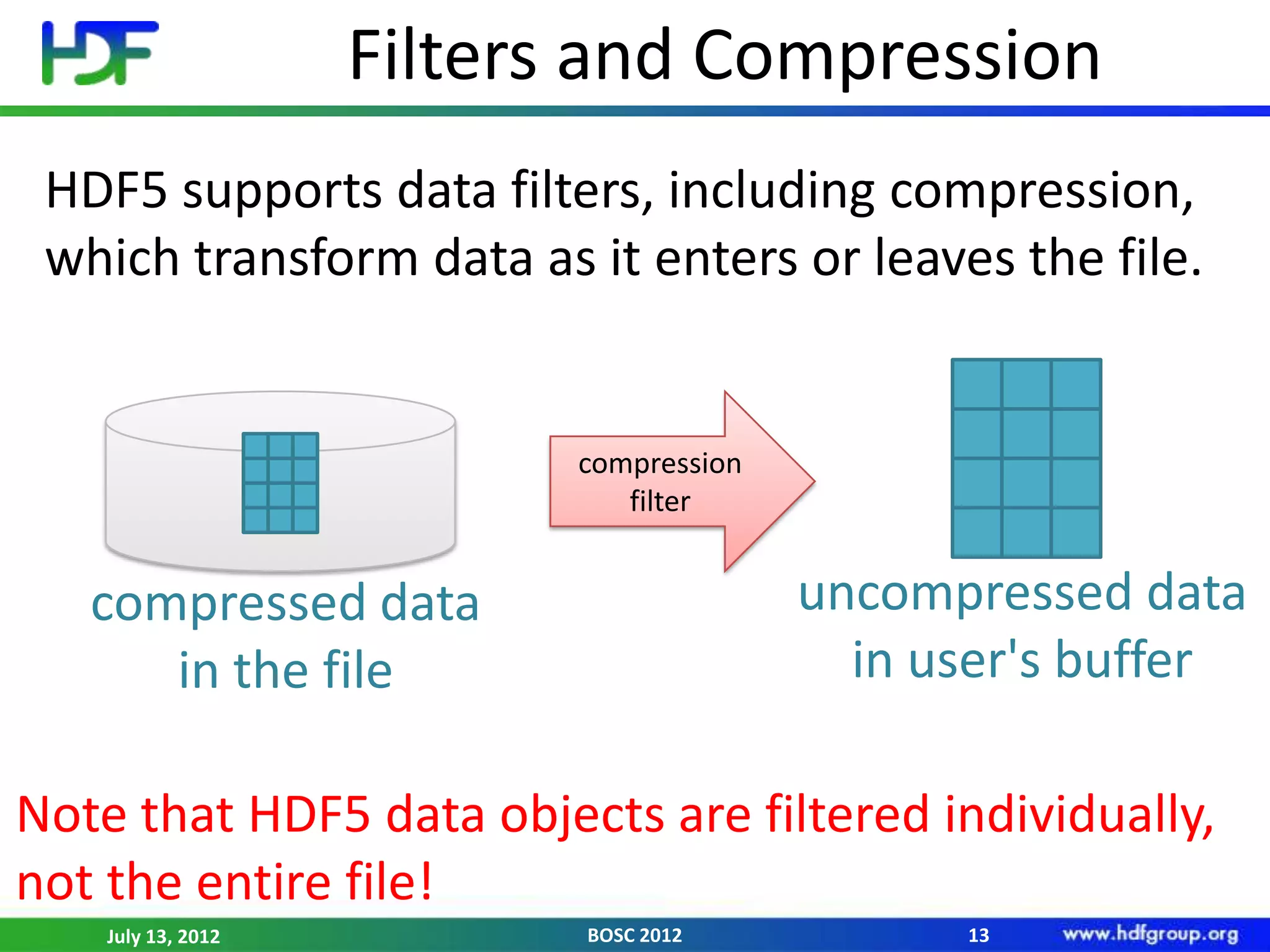


The document provides an overview of the HDF5 technology stack, which is designed for organizing and storing large quantities of heterogeneous multidimensional biological data. It highlights the advantages of HDF5, including scalability, self-describing files, and support for parallel I/O and compression, while also noting the absence of a built-in query engine. Additionally, it mentions the availability of higher language bindings for various programming languages to facilitate data access.































































































