Download to read offline

































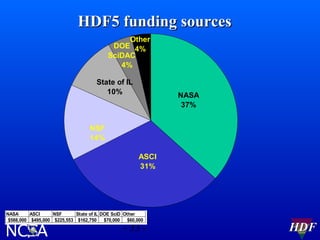


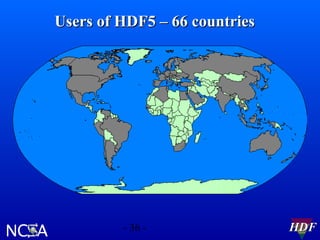










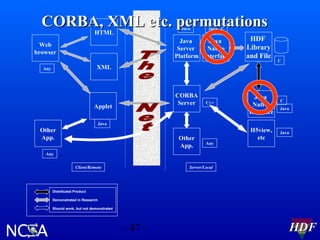


This document summarizes HDF software activities in 2002, including support and funding sources for HDF, recent and upcoming releases of HDF4 and HDF5 libraries and tools, and other HDF-related projects. The HDF5 library saw improvements to performance, compilers supported, and tools like HDFView and converters. The next major HDF5 release in 2003 will focus on new features, performance enhancements, and special platform support. High level APIs and the parallel HDF5 programming model were also under development.






















































































