Download to read offline


























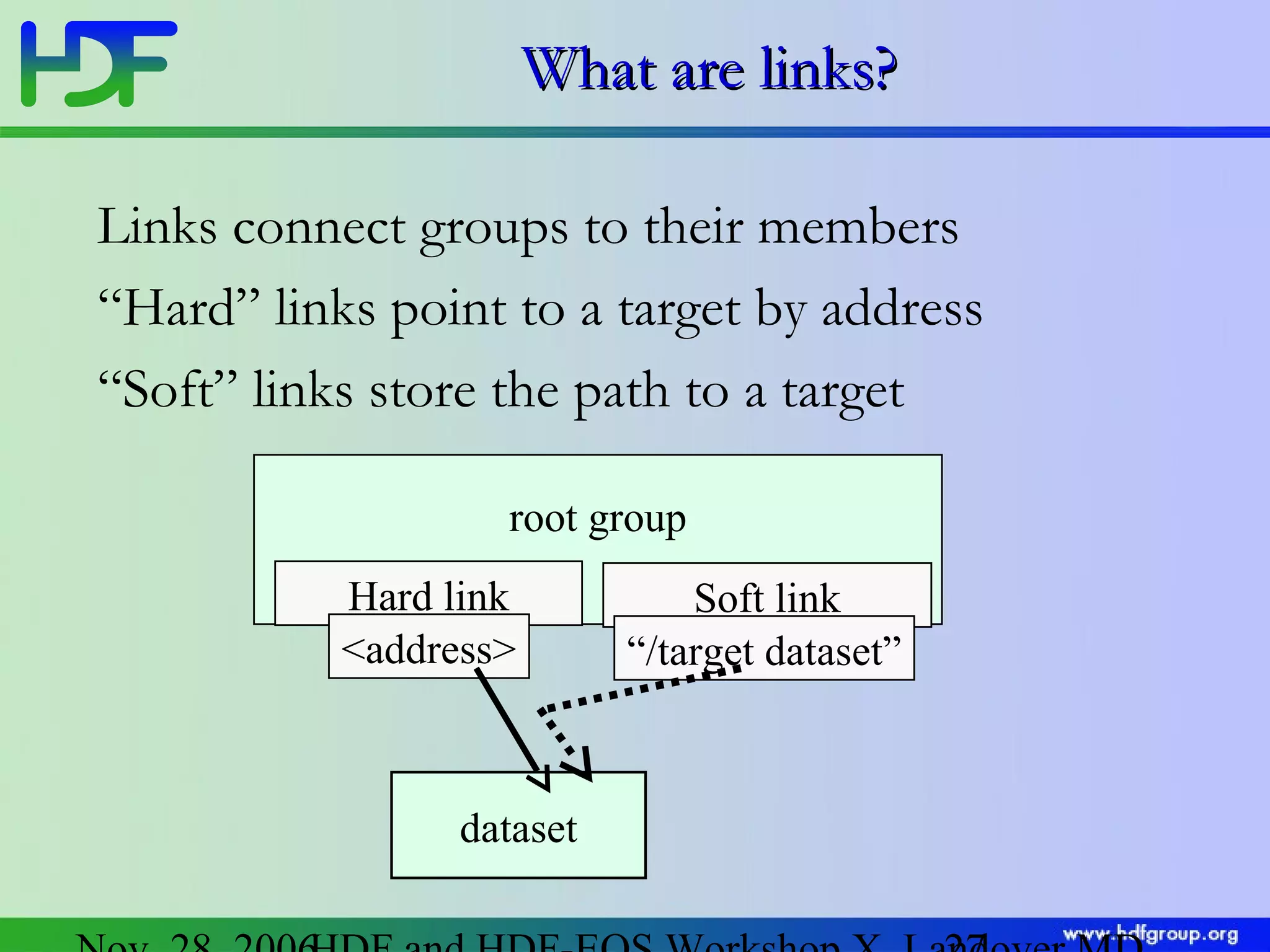
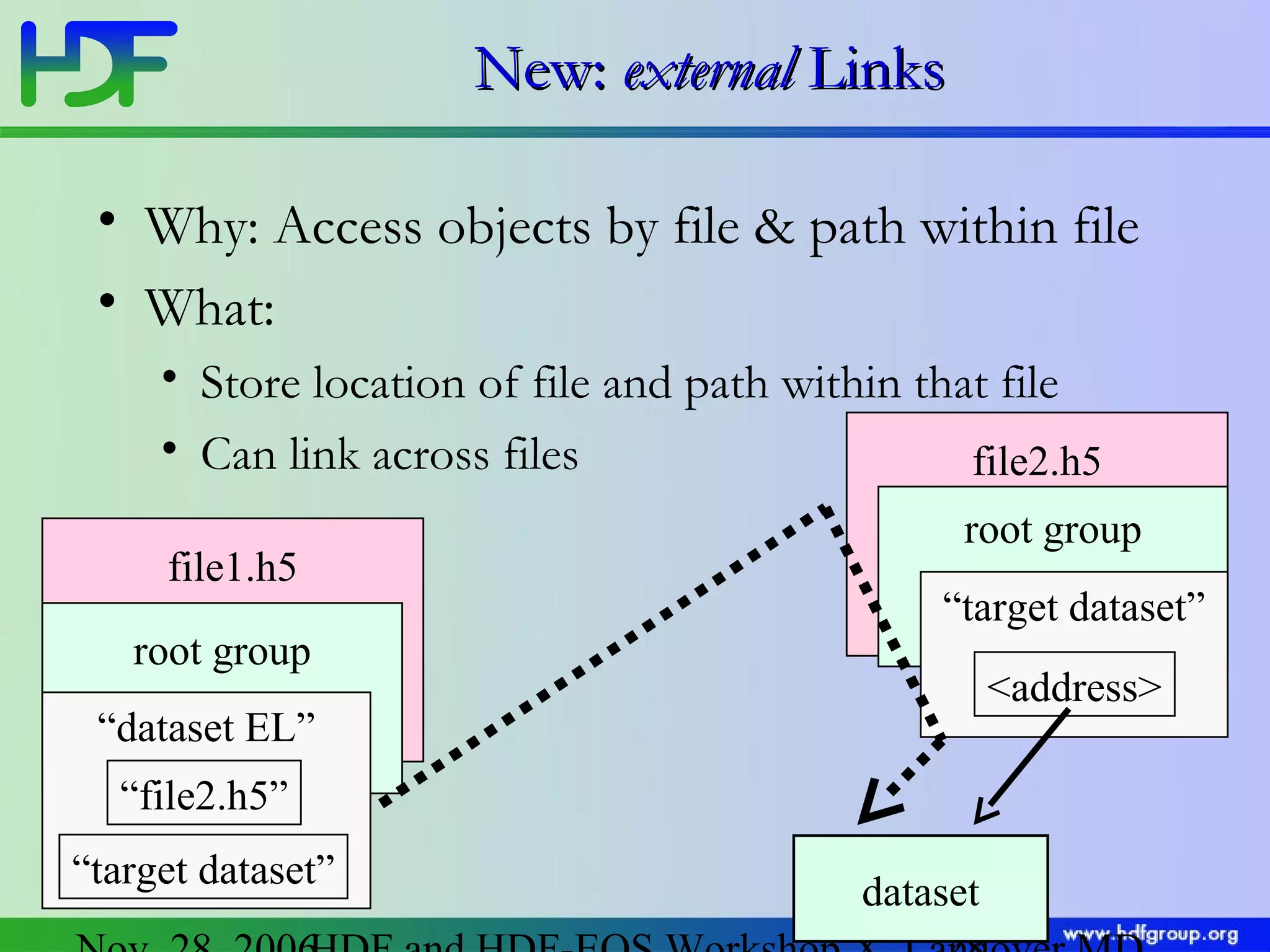



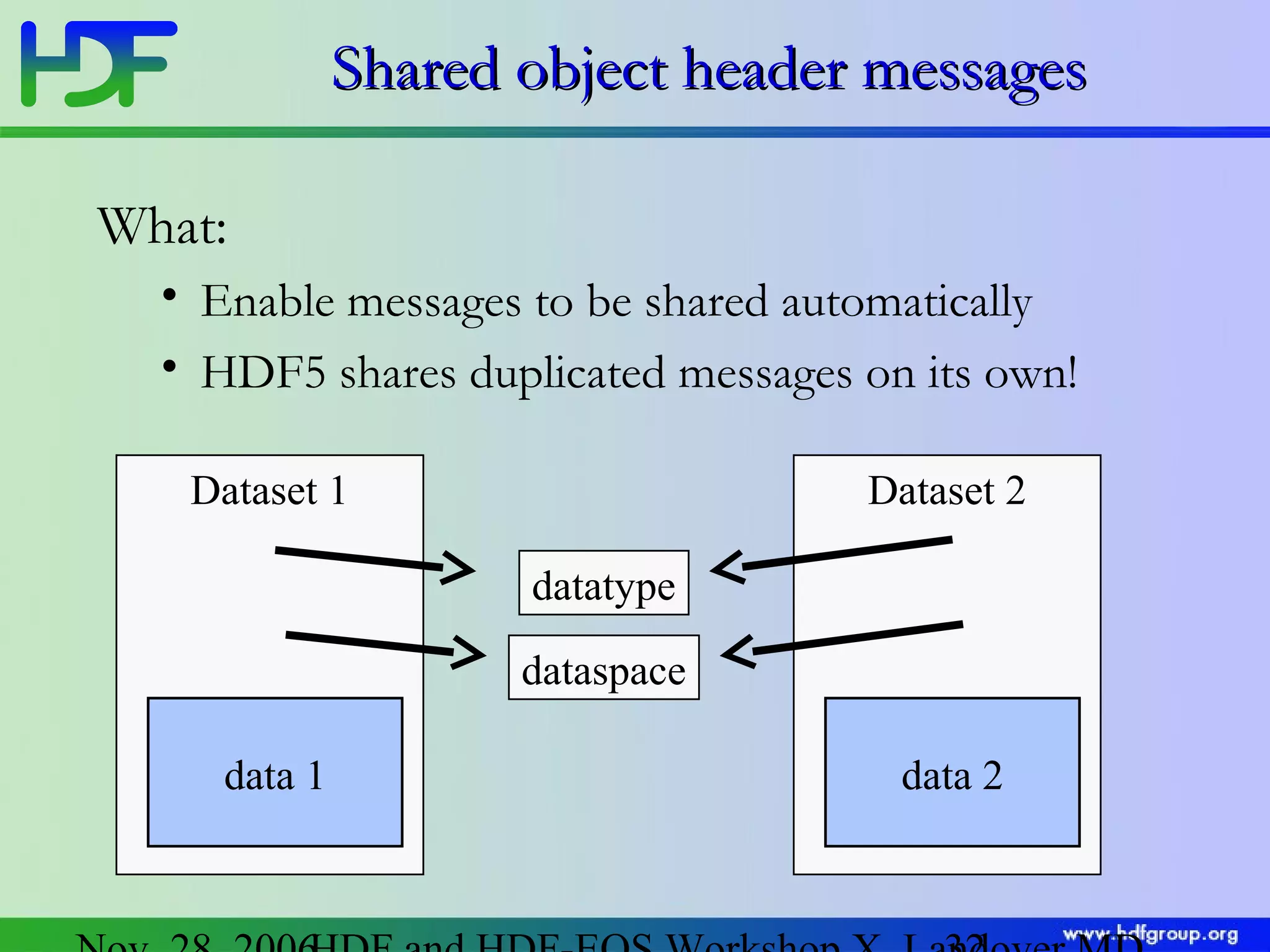










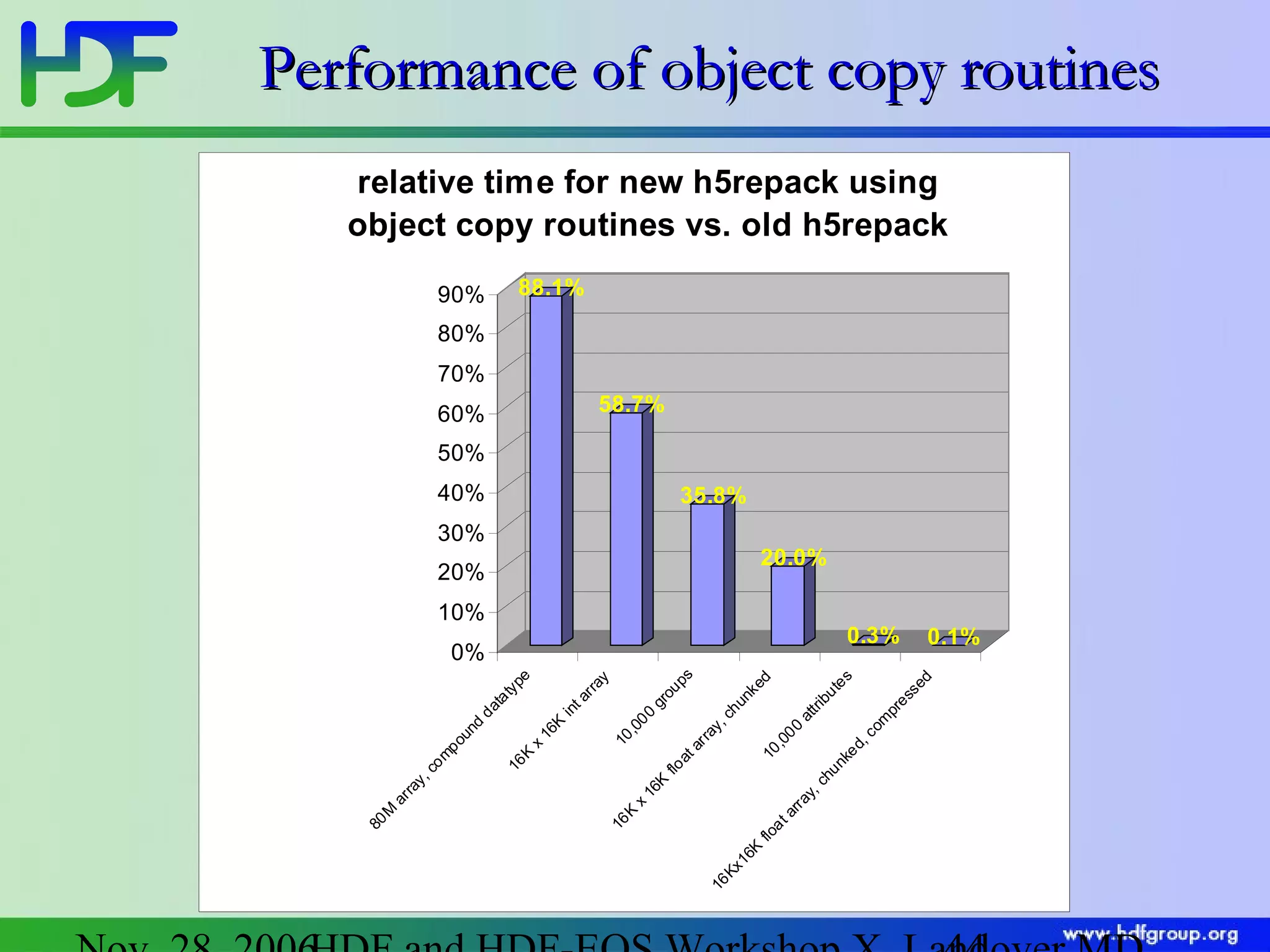





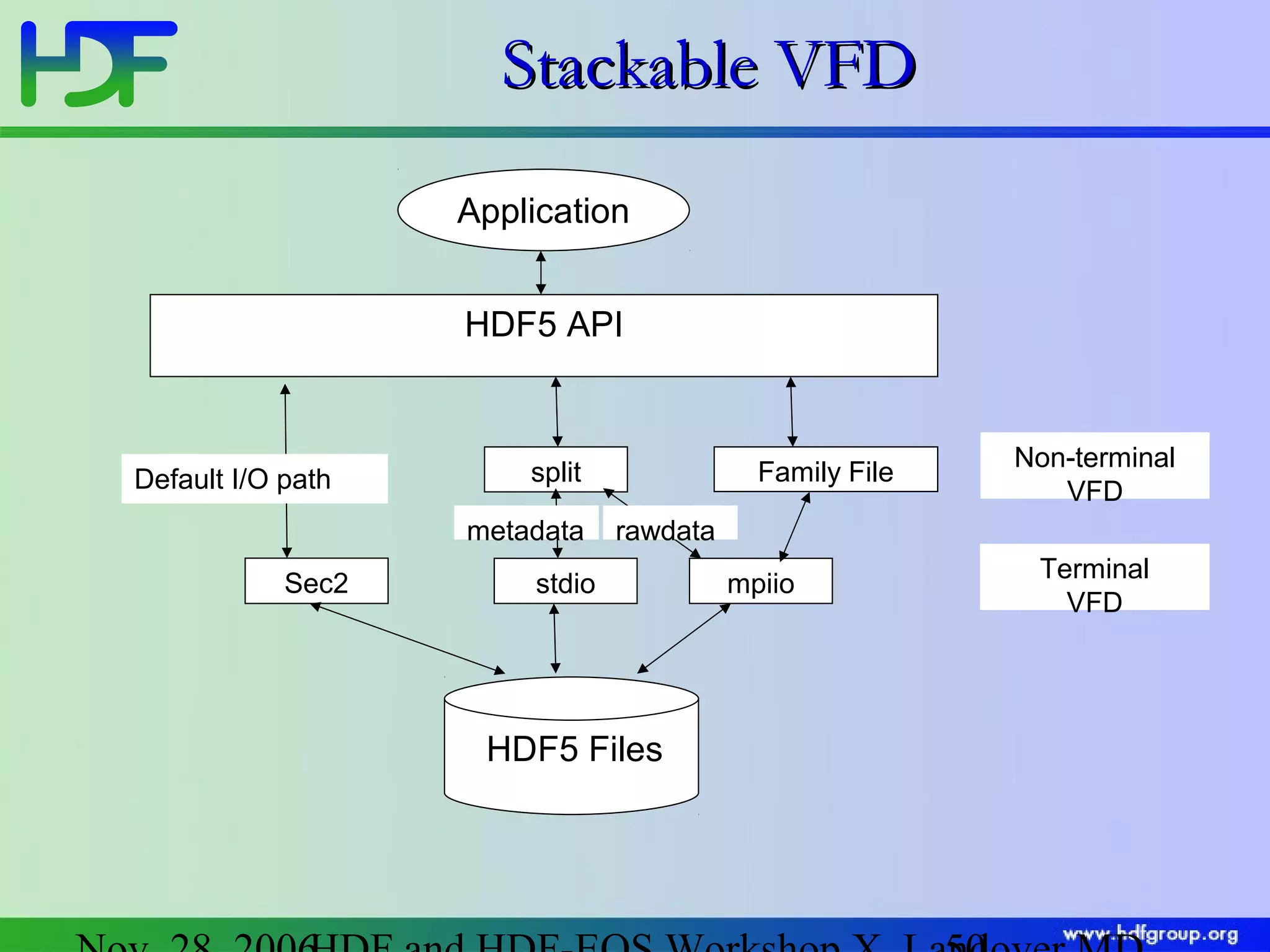







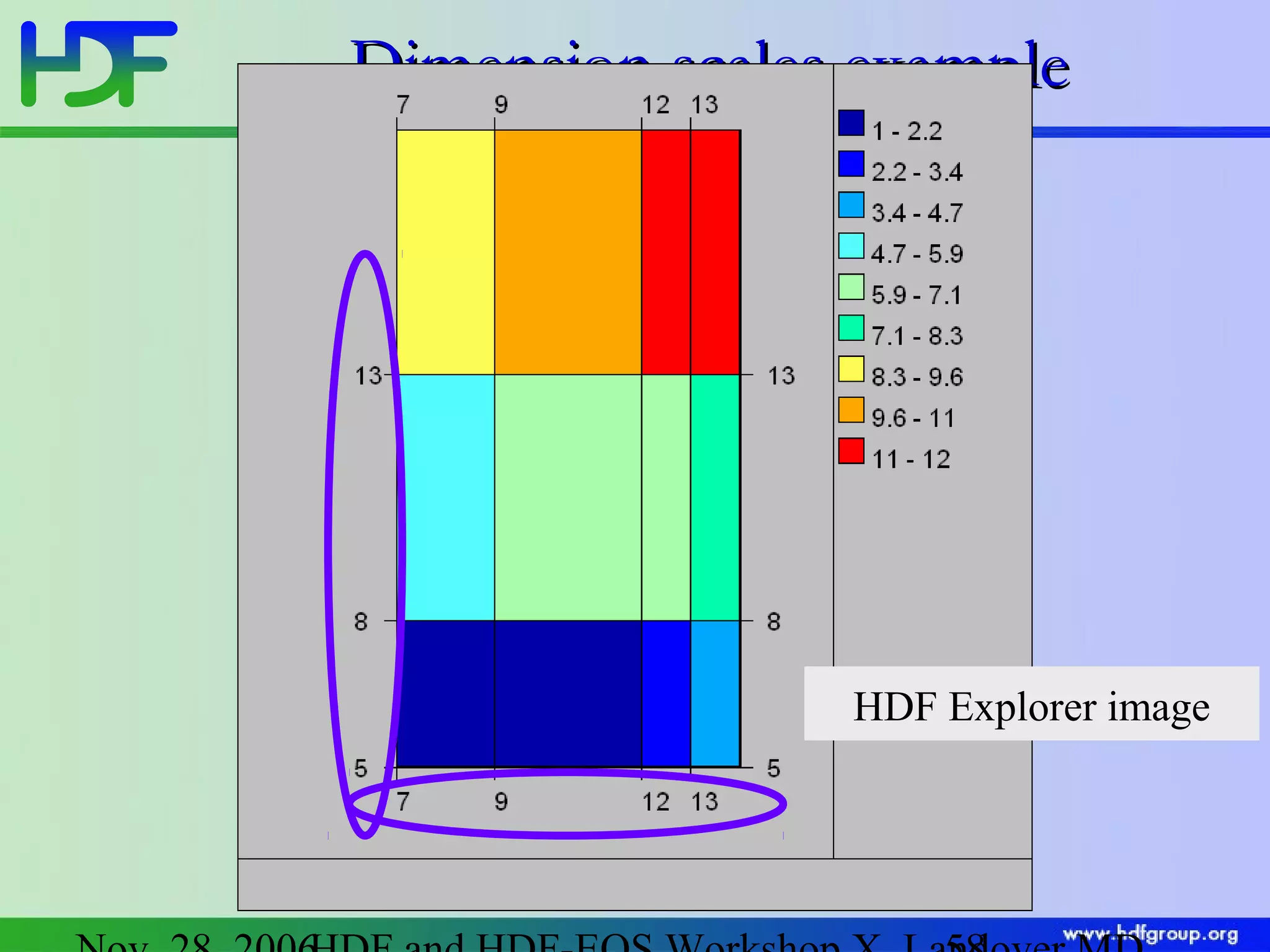
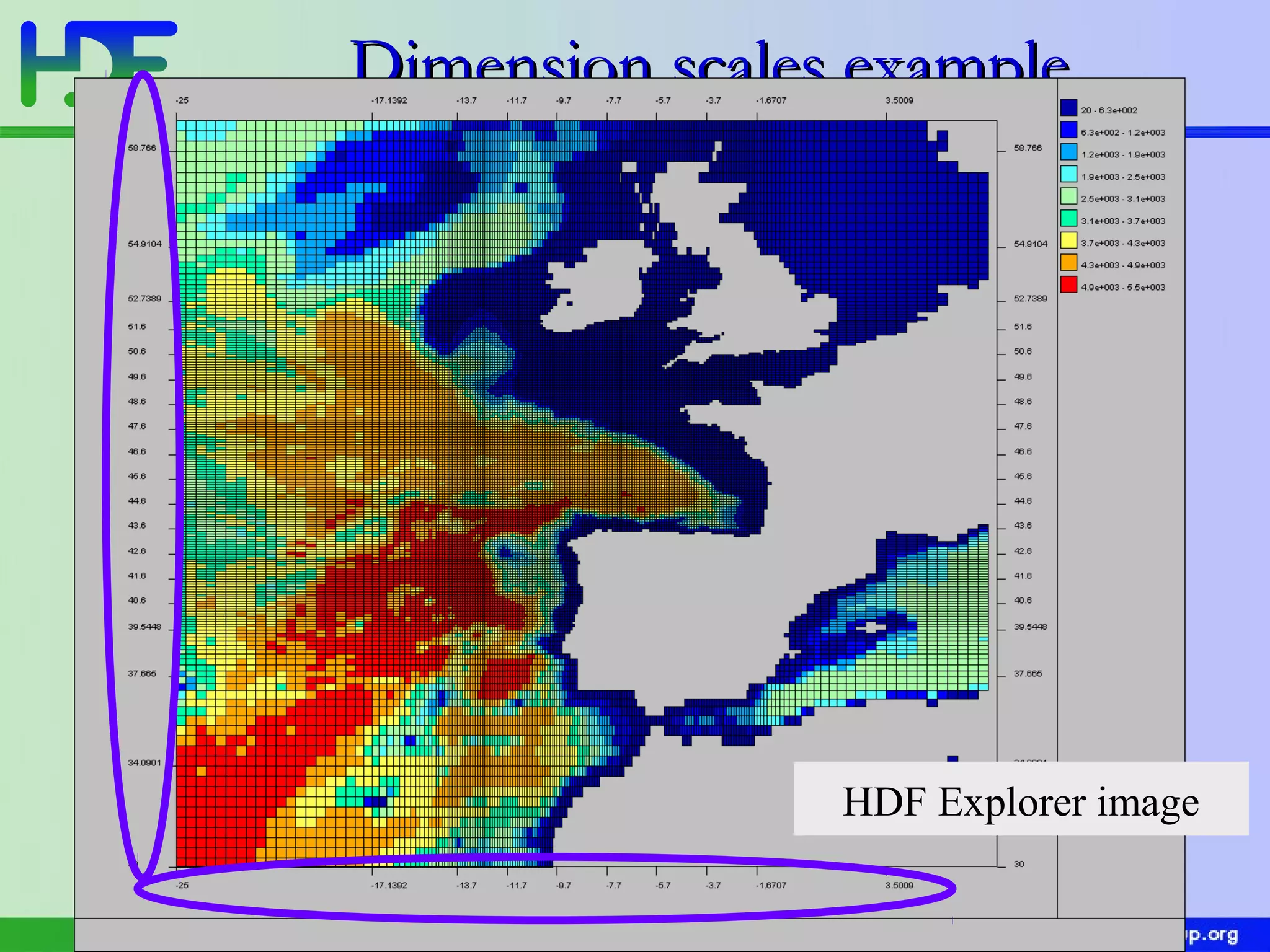















The document discusses updates in HDF5 version 1.8, highlighting improvements in APIs, data types, and performance optimizations for datasets and metadata handling. Key changes include new high-level APIs, enhancements for managing datasets, and features for serialization, compression, and error handling. Additionally, it addresses changes in platform support and introduces parallel I/O capabilities to enhance overall functionality and efficiency in data management.























































































