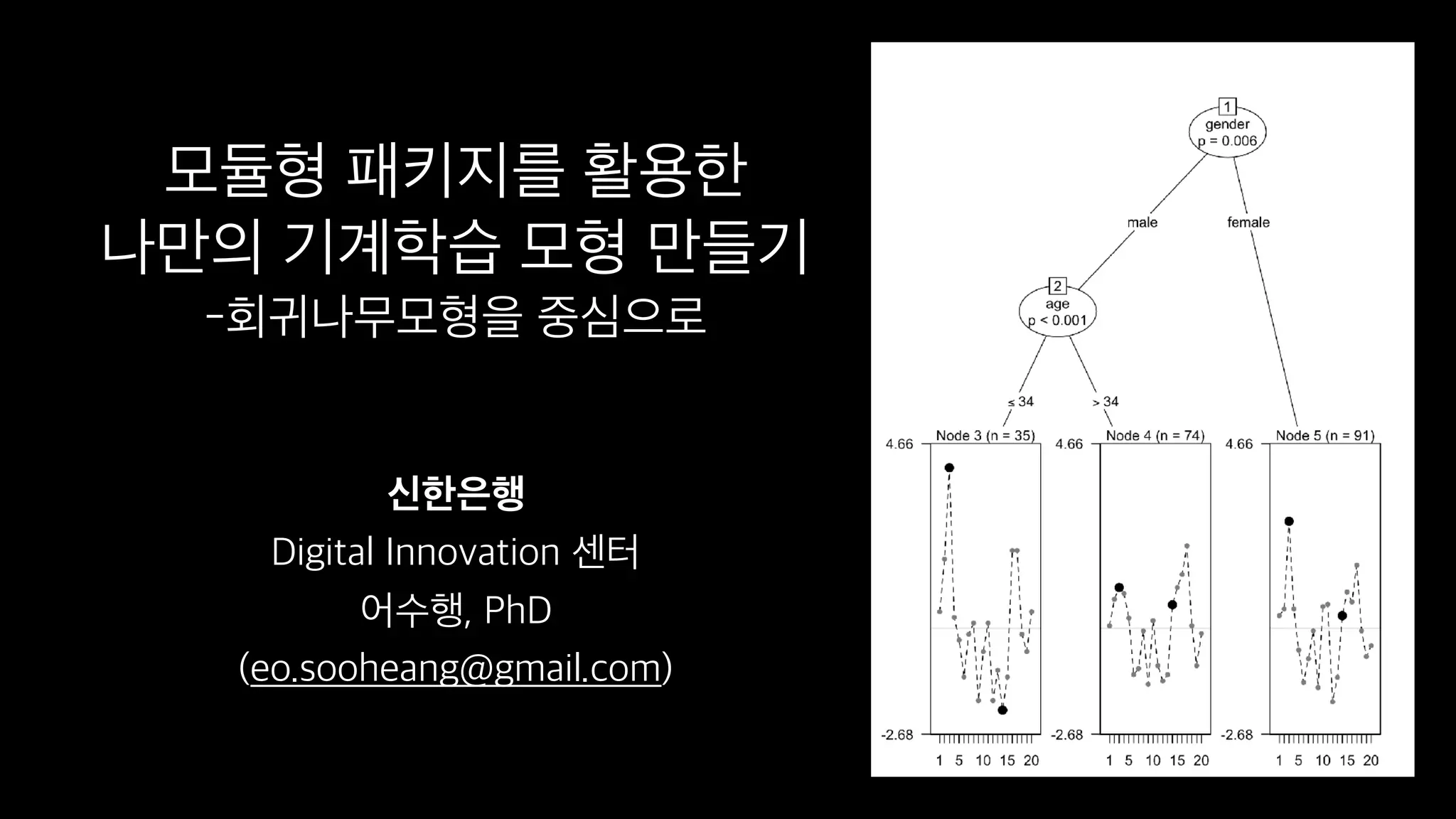
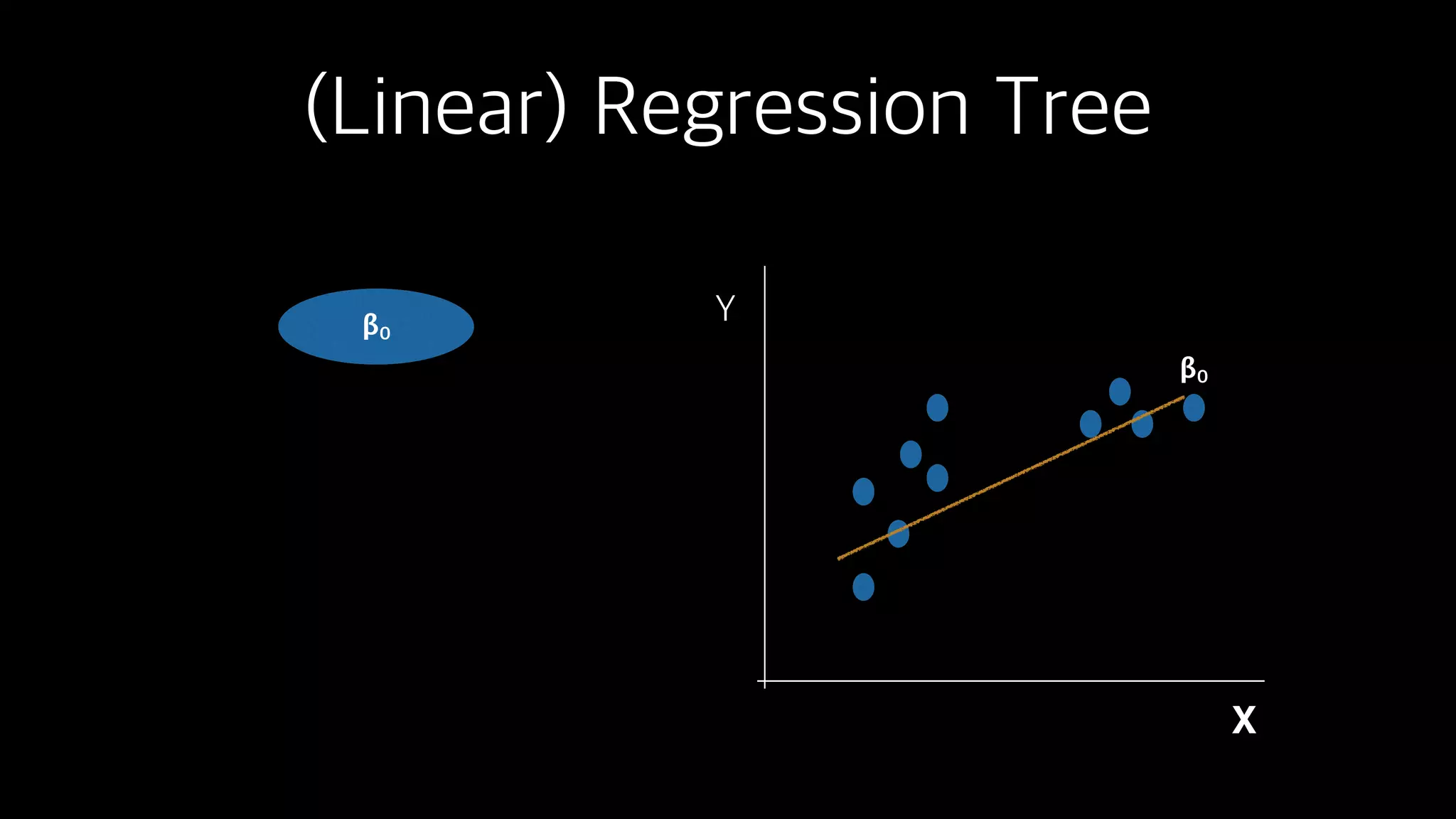
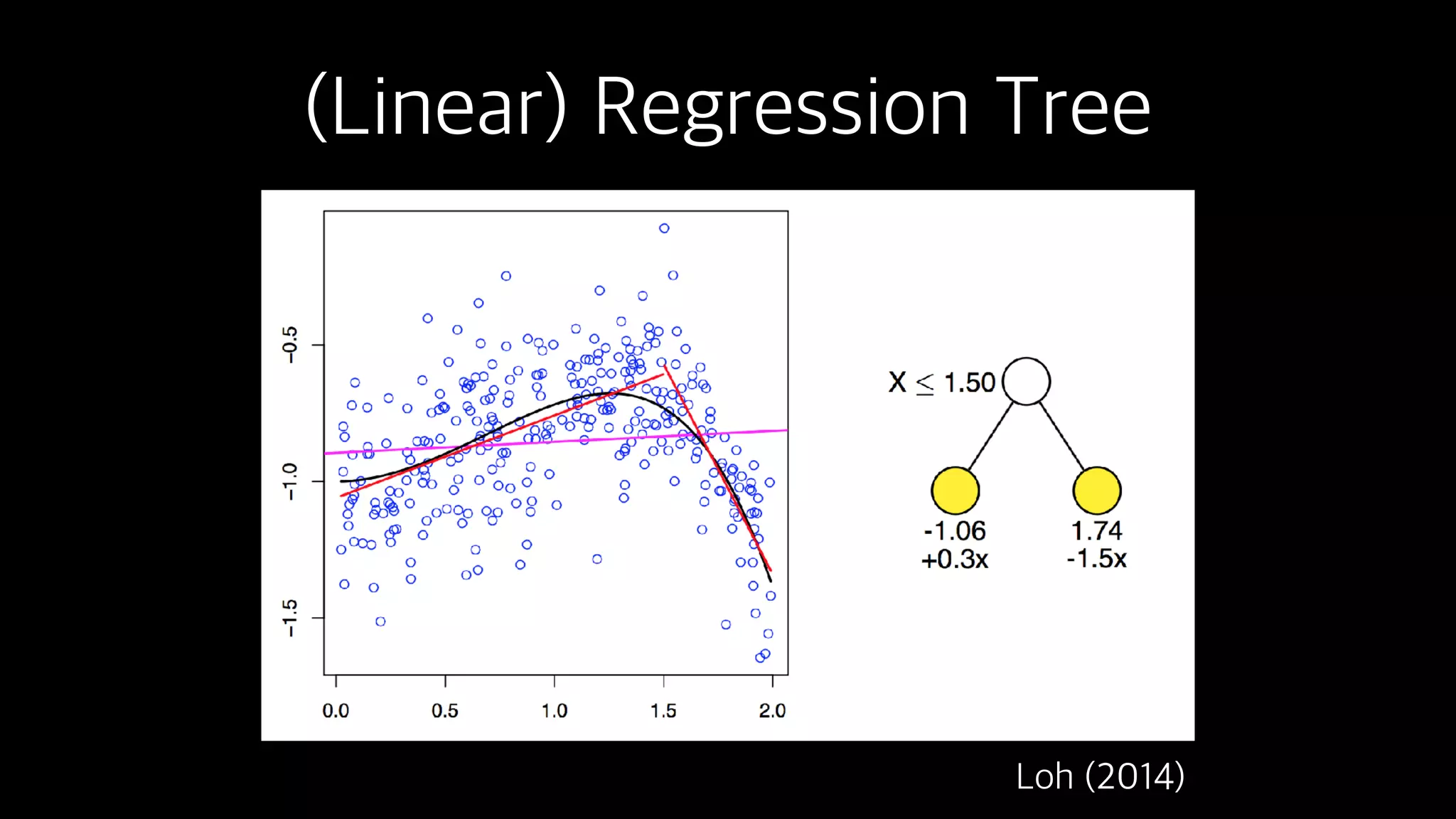
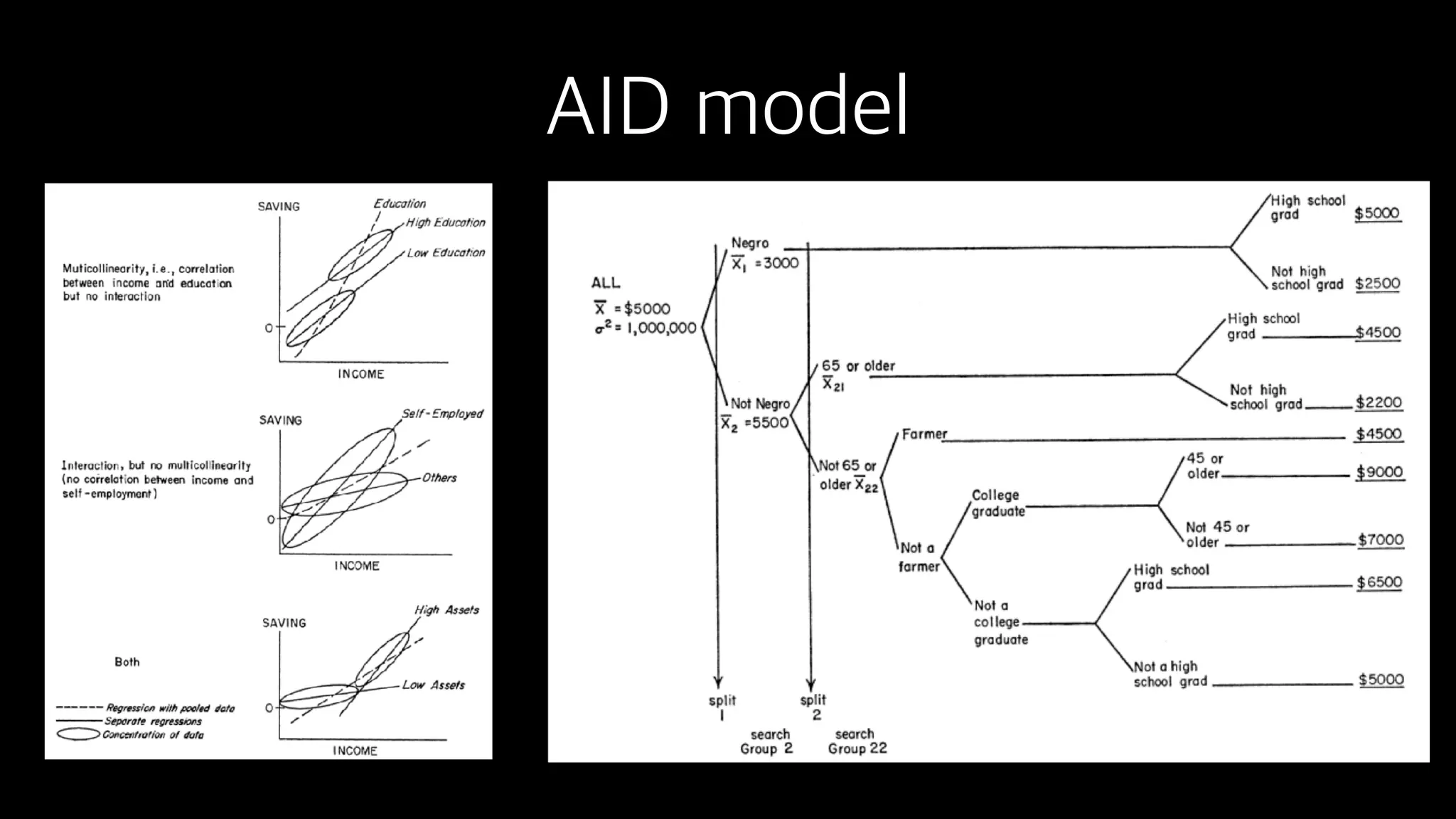
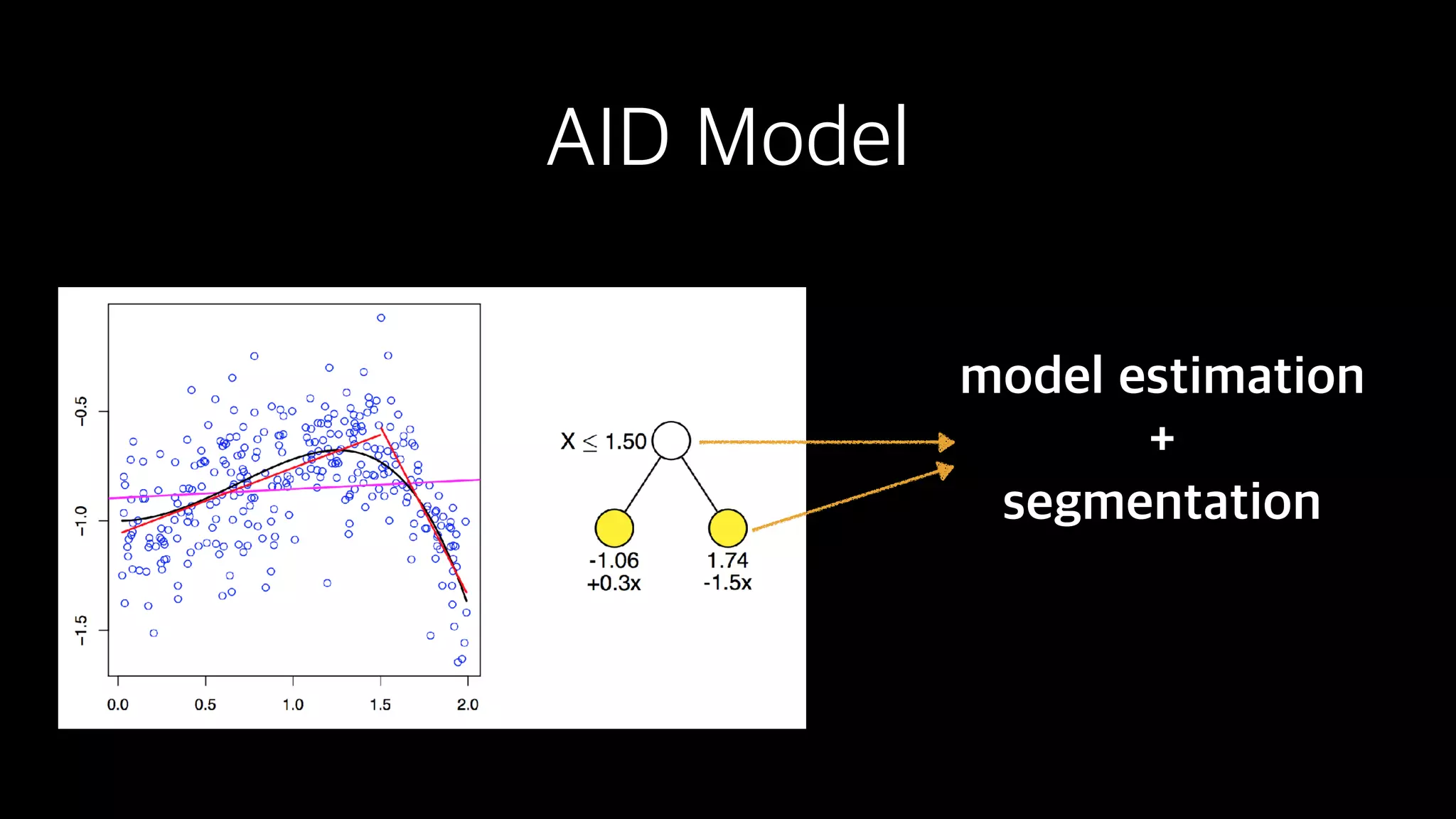
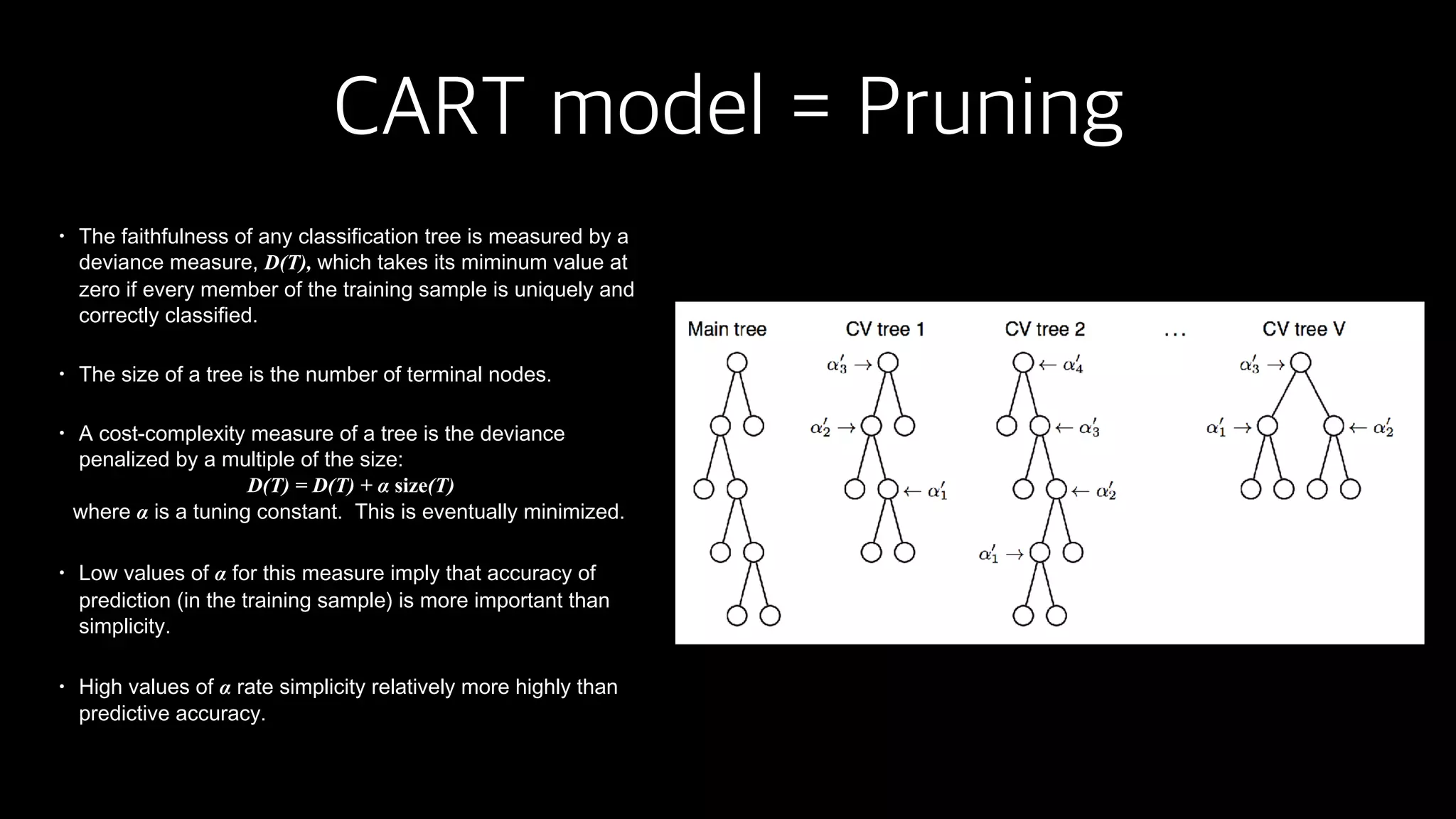
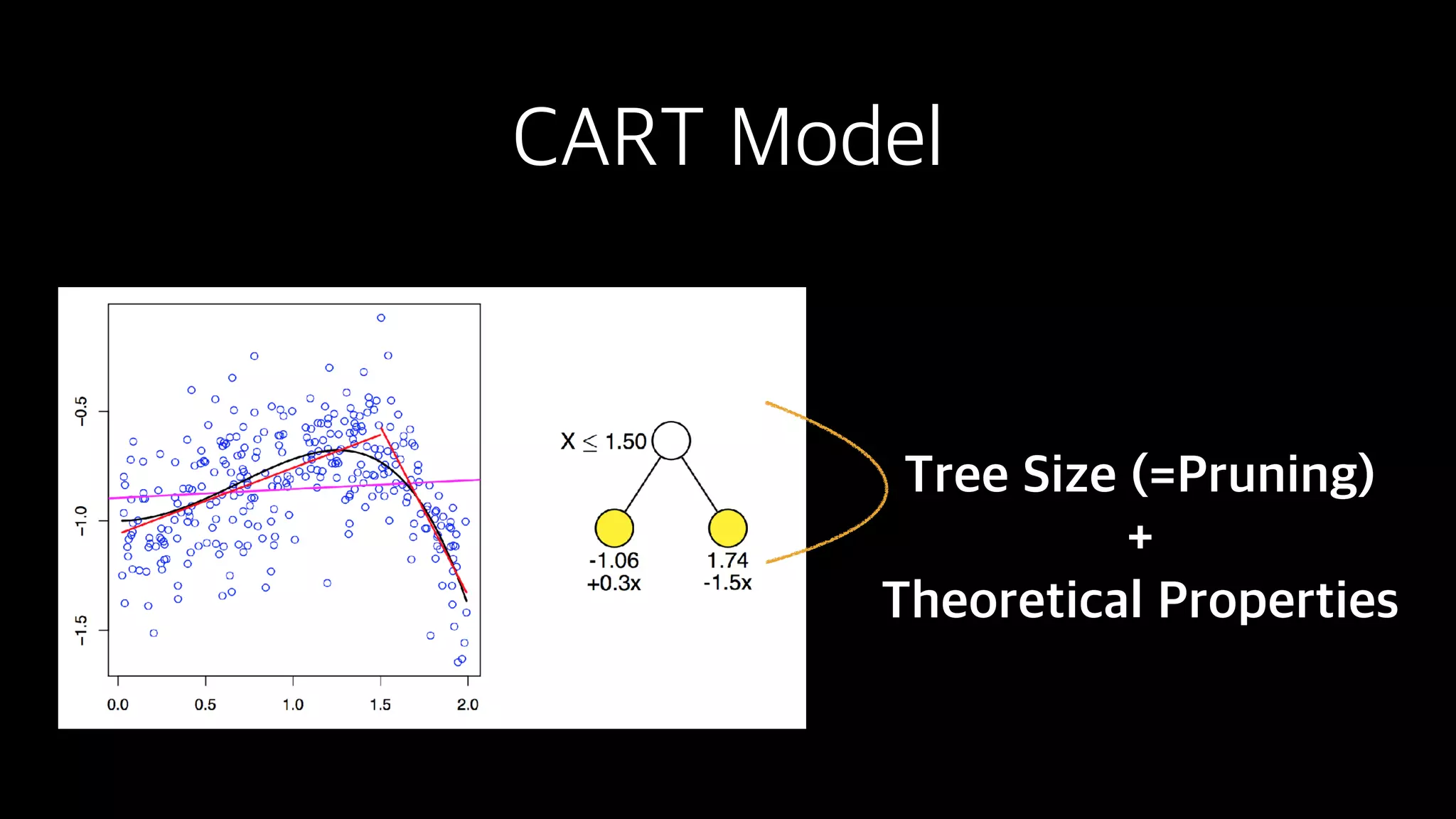
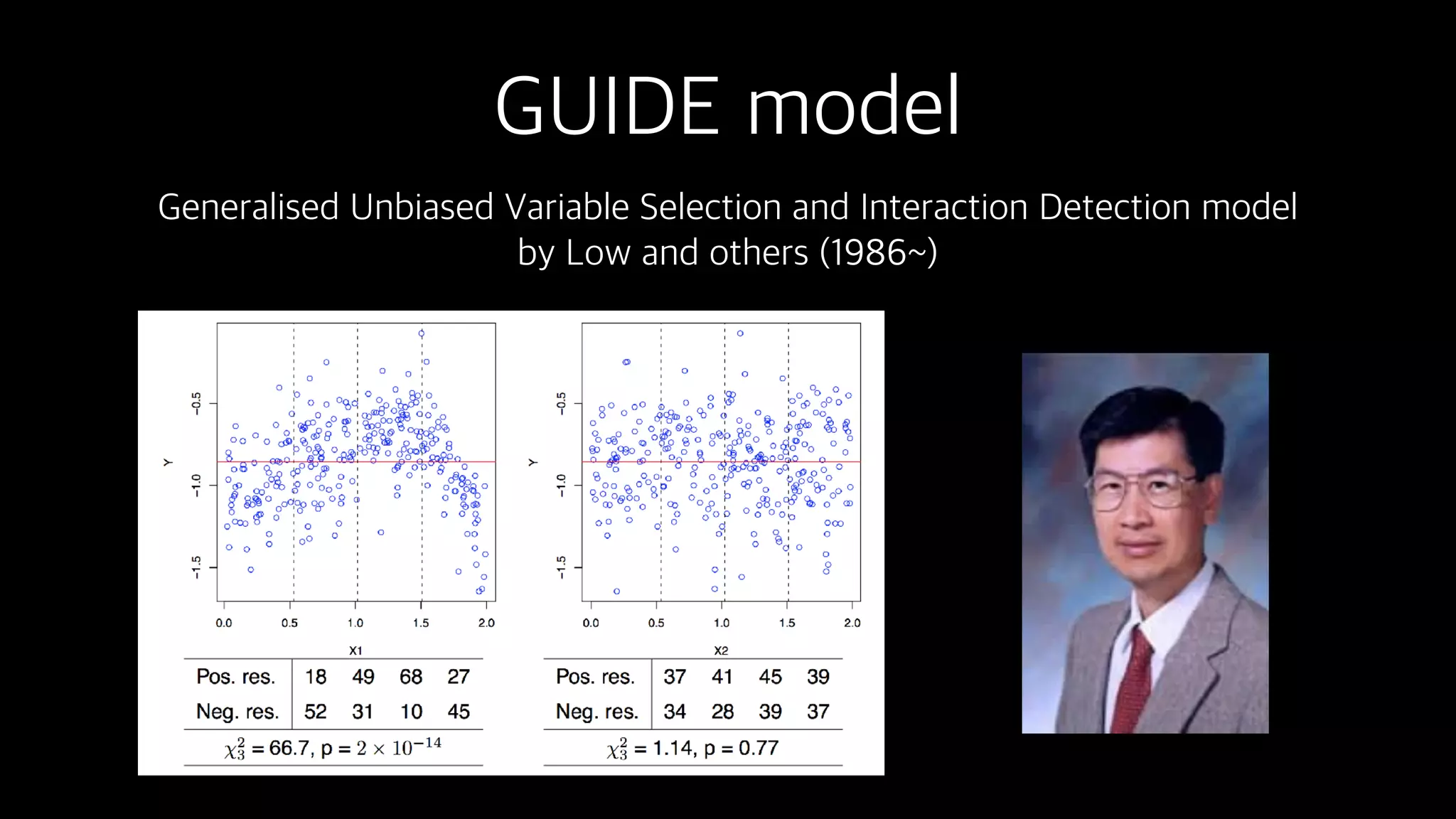
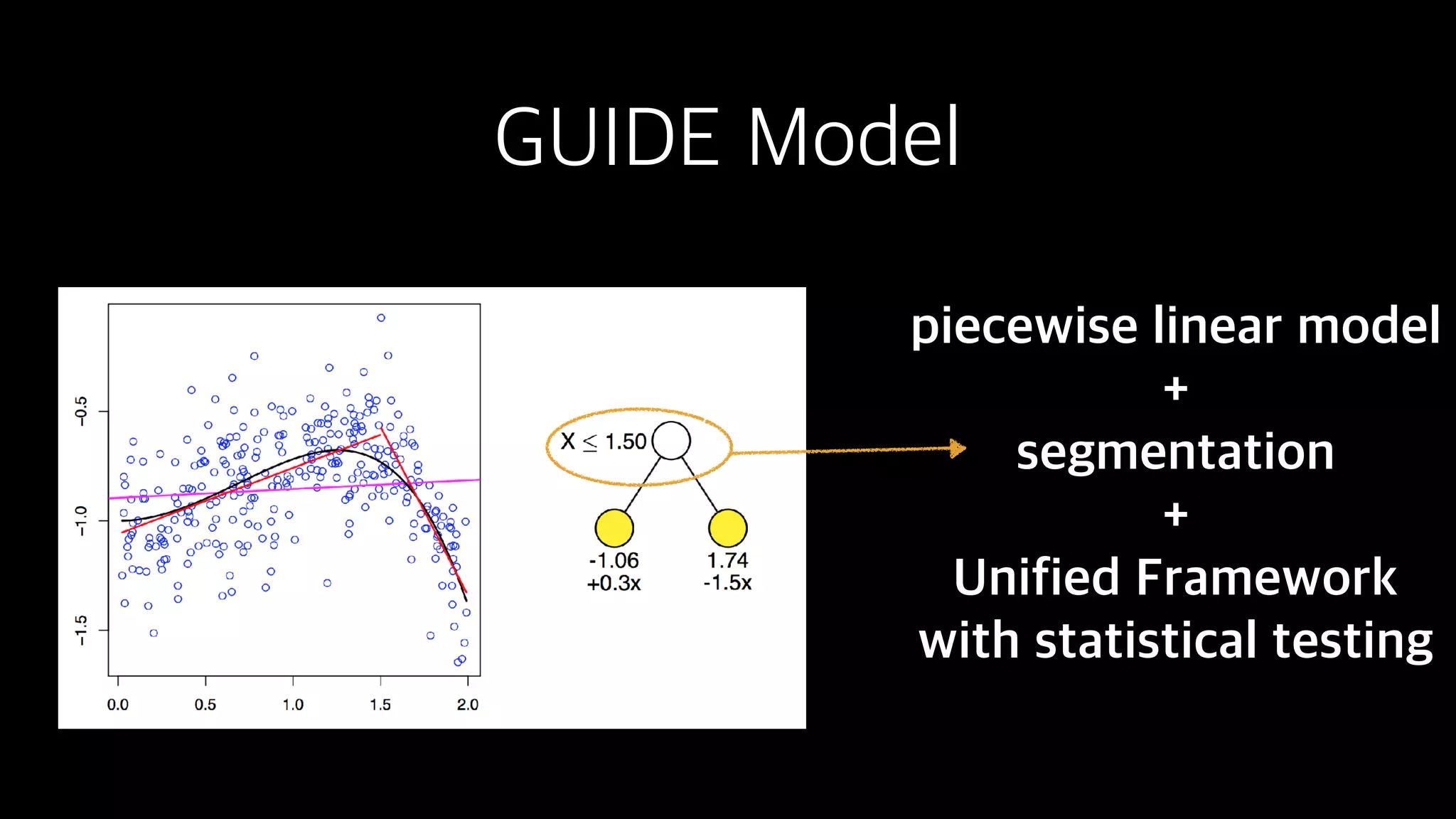
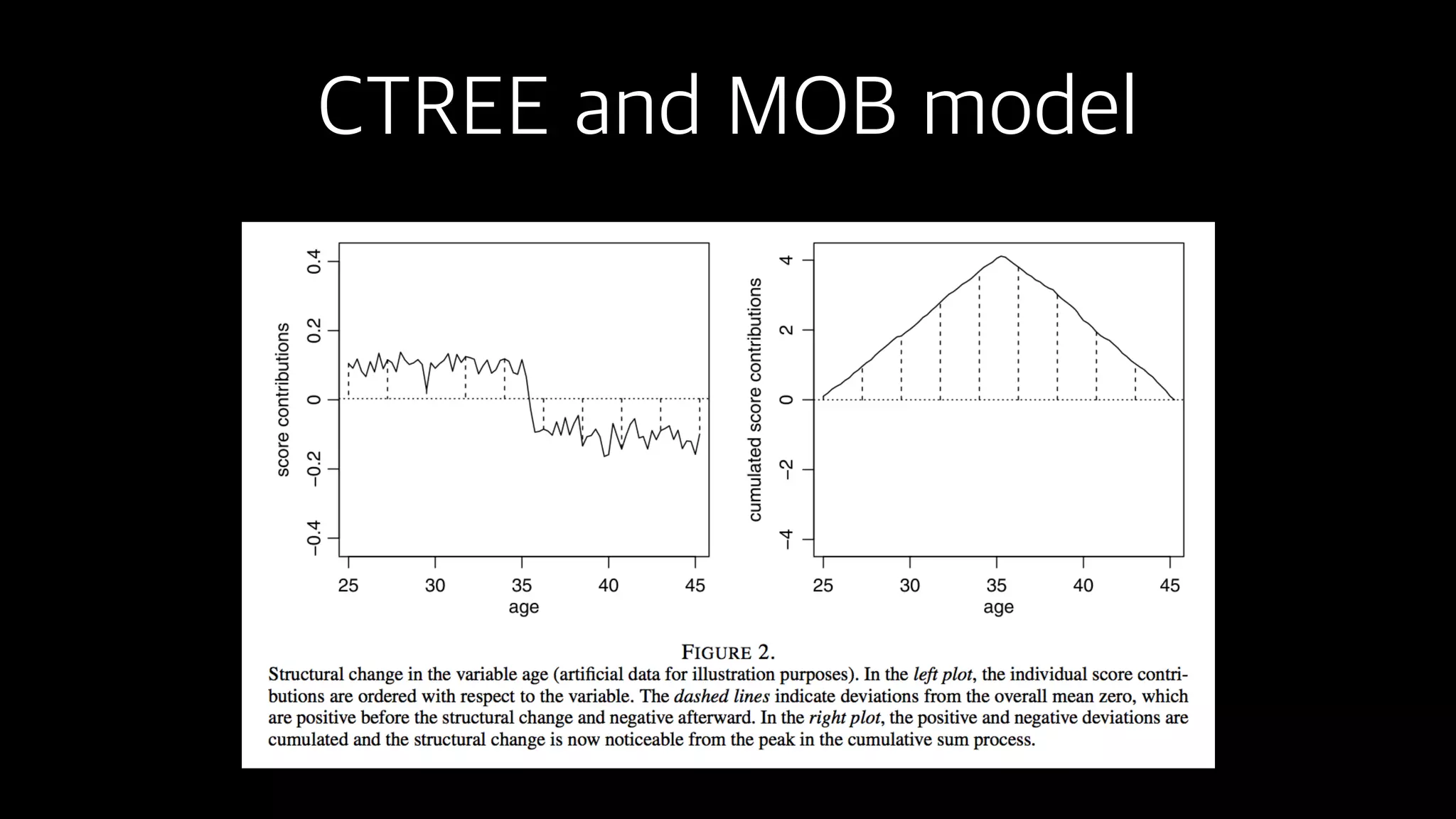
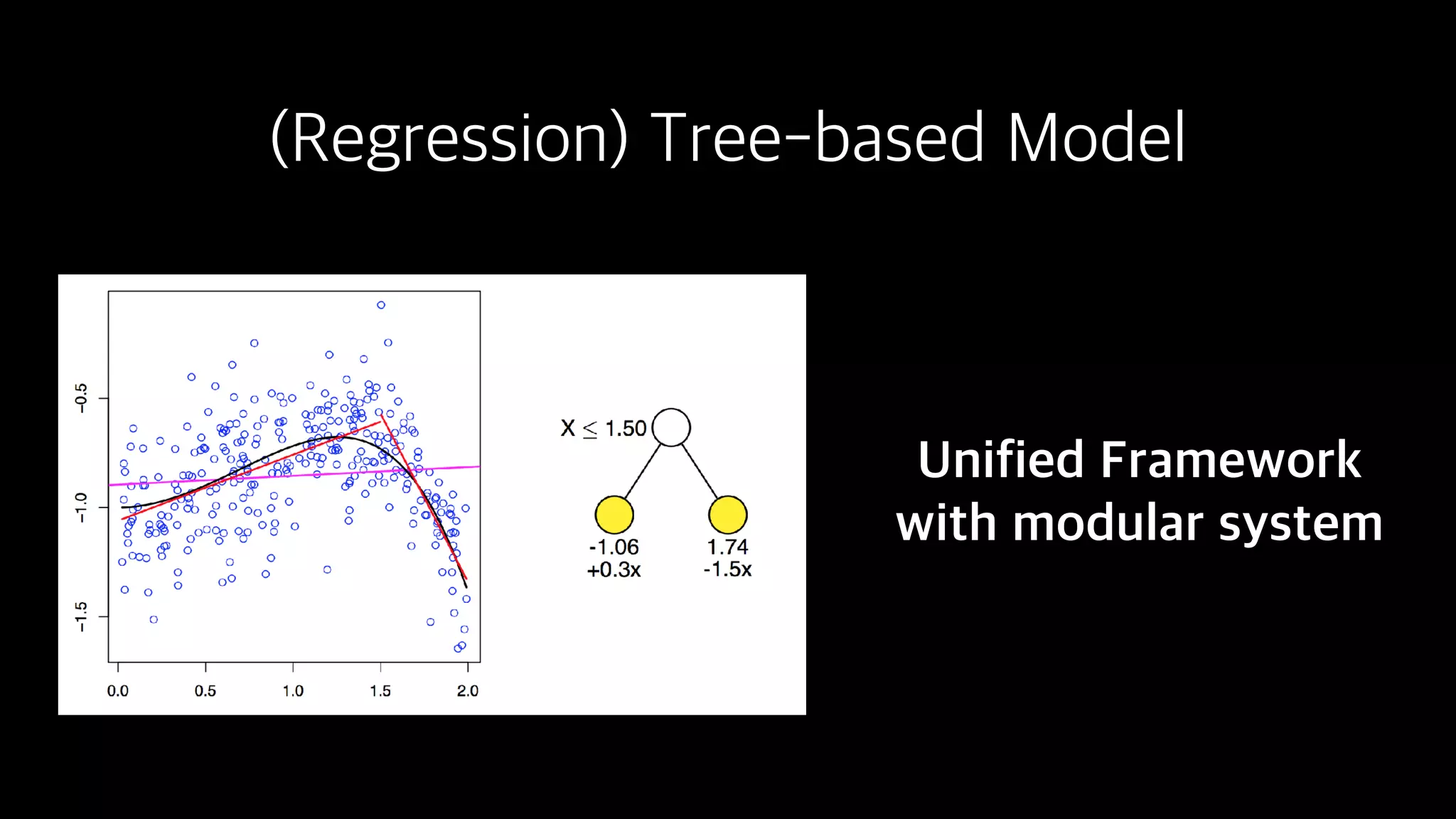
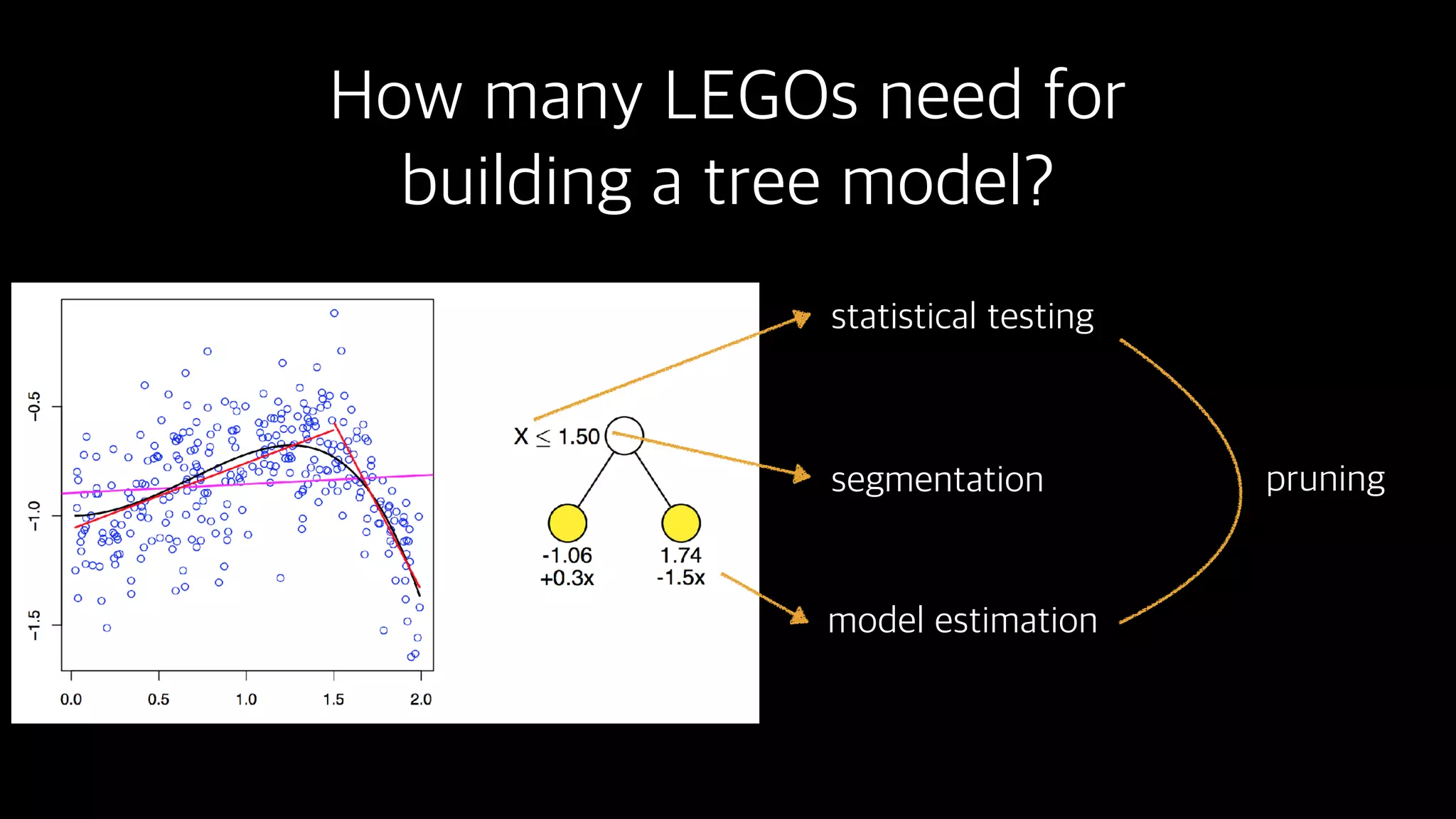
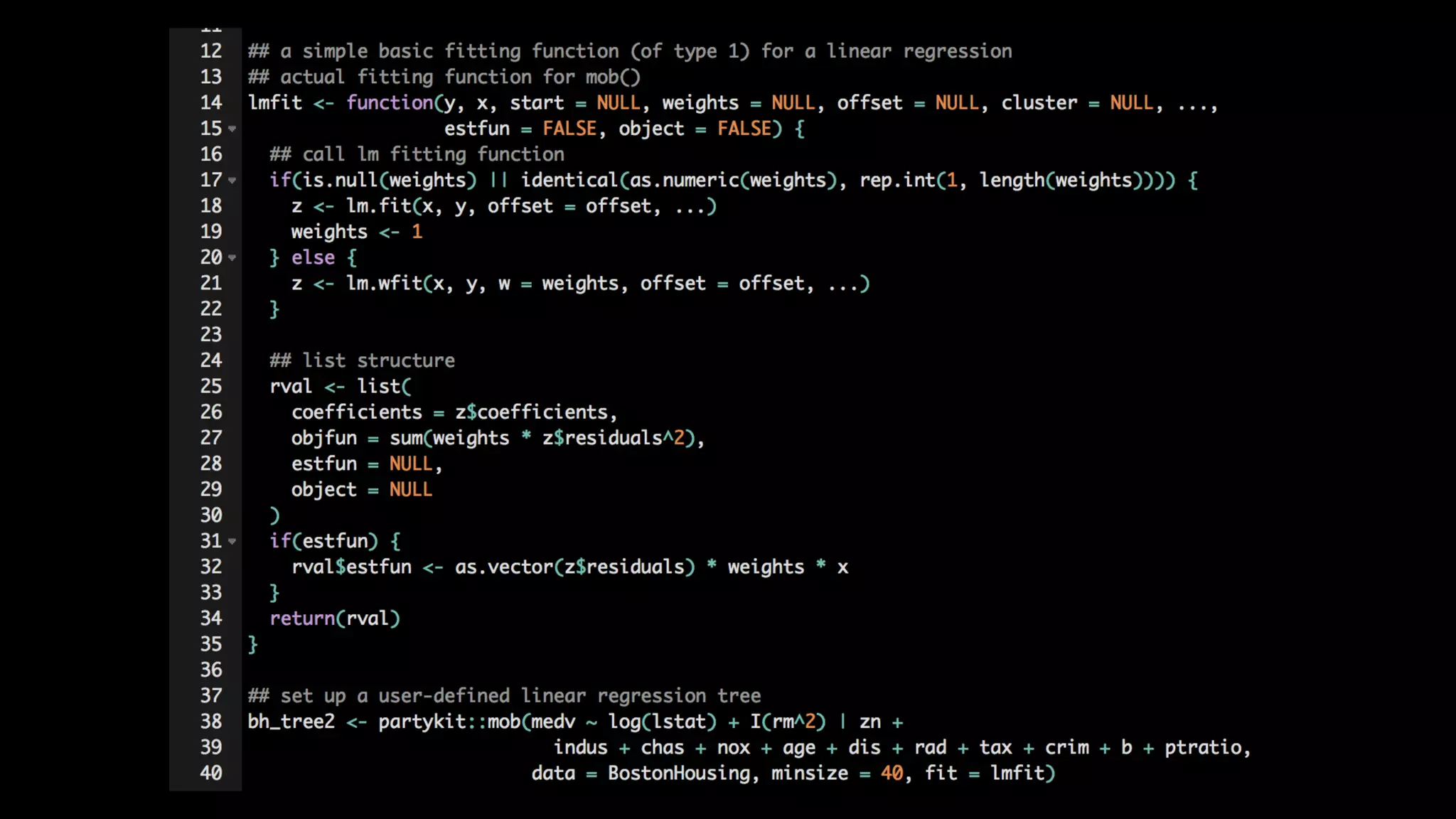
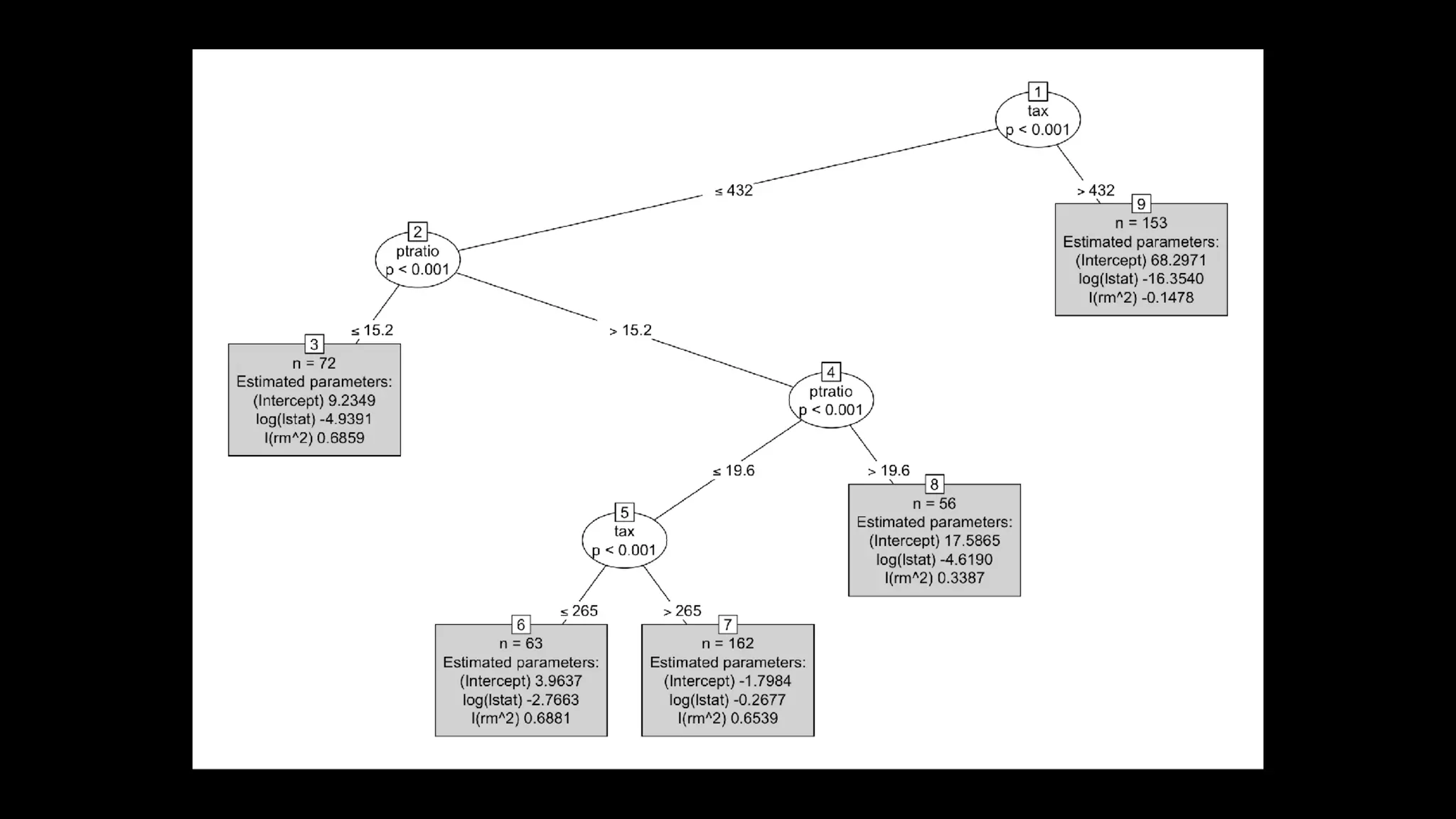
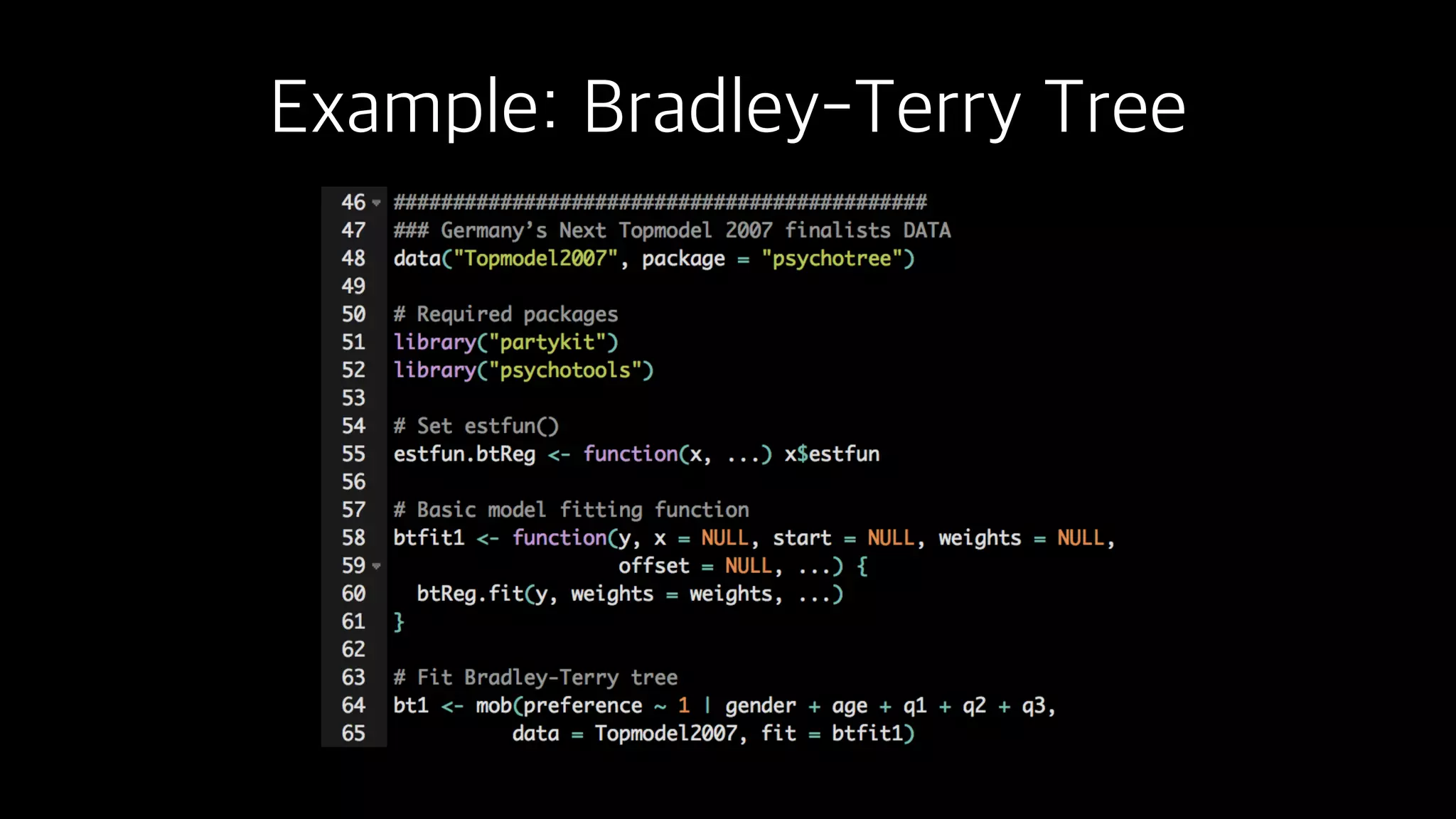
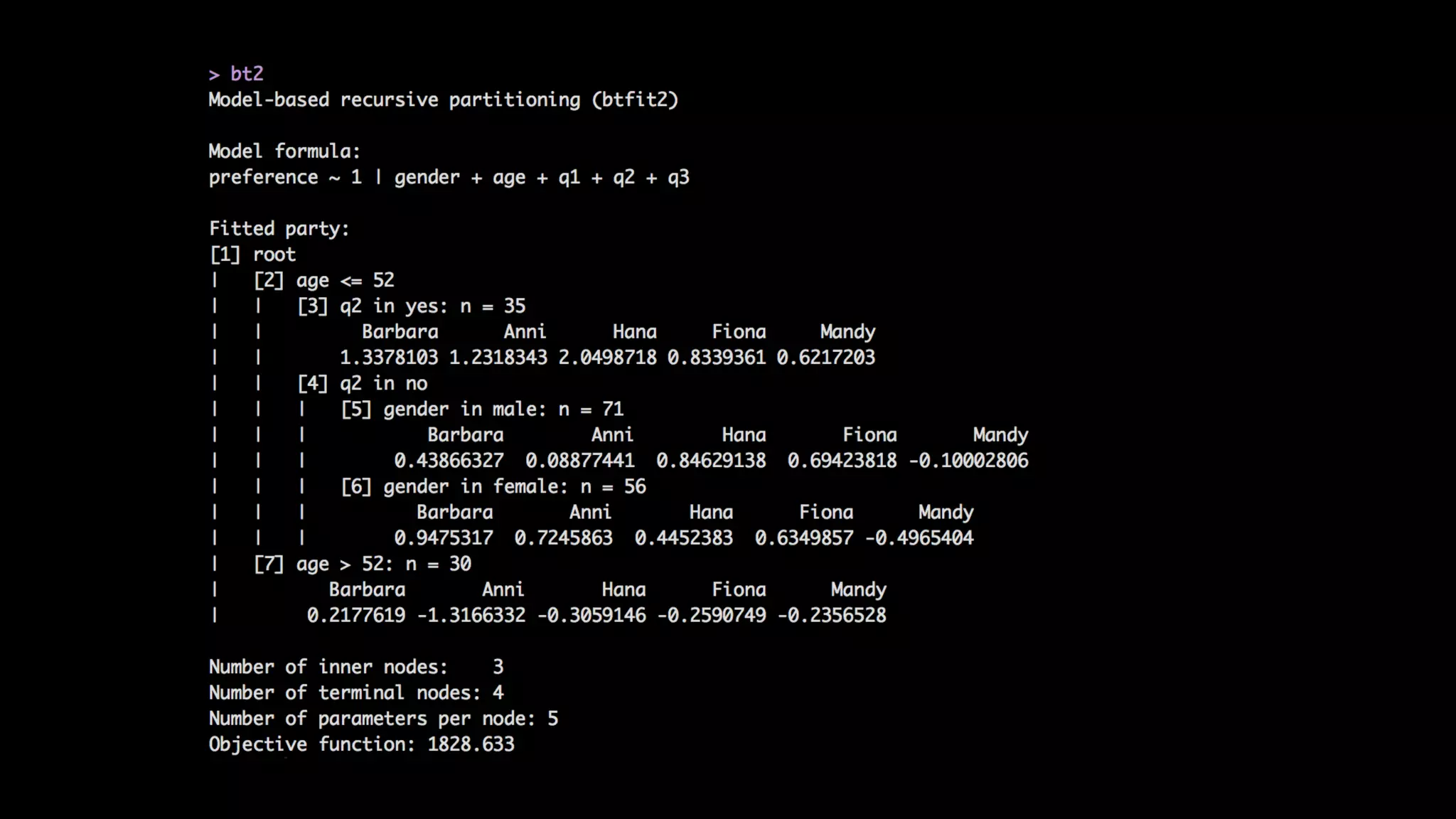
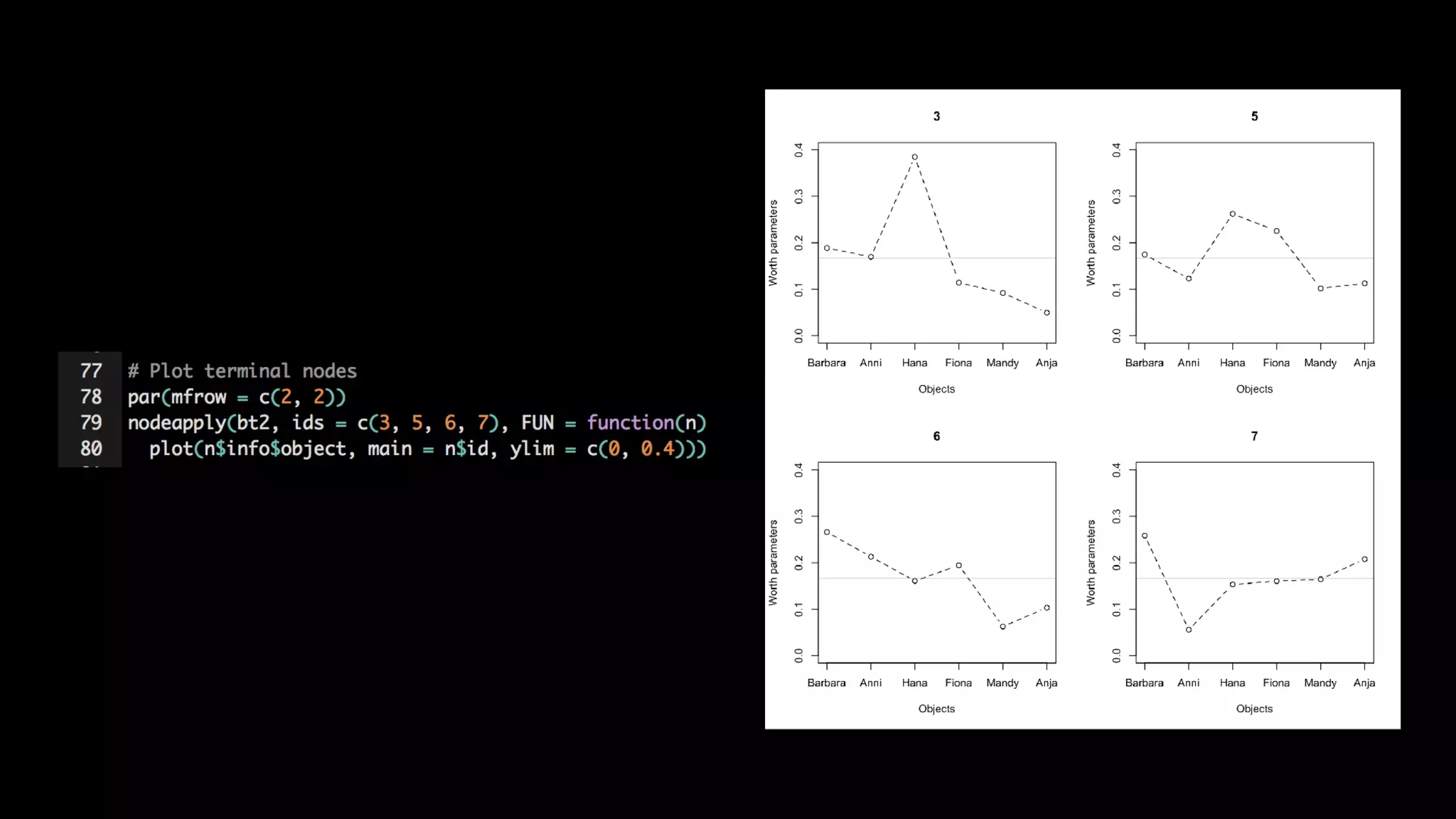
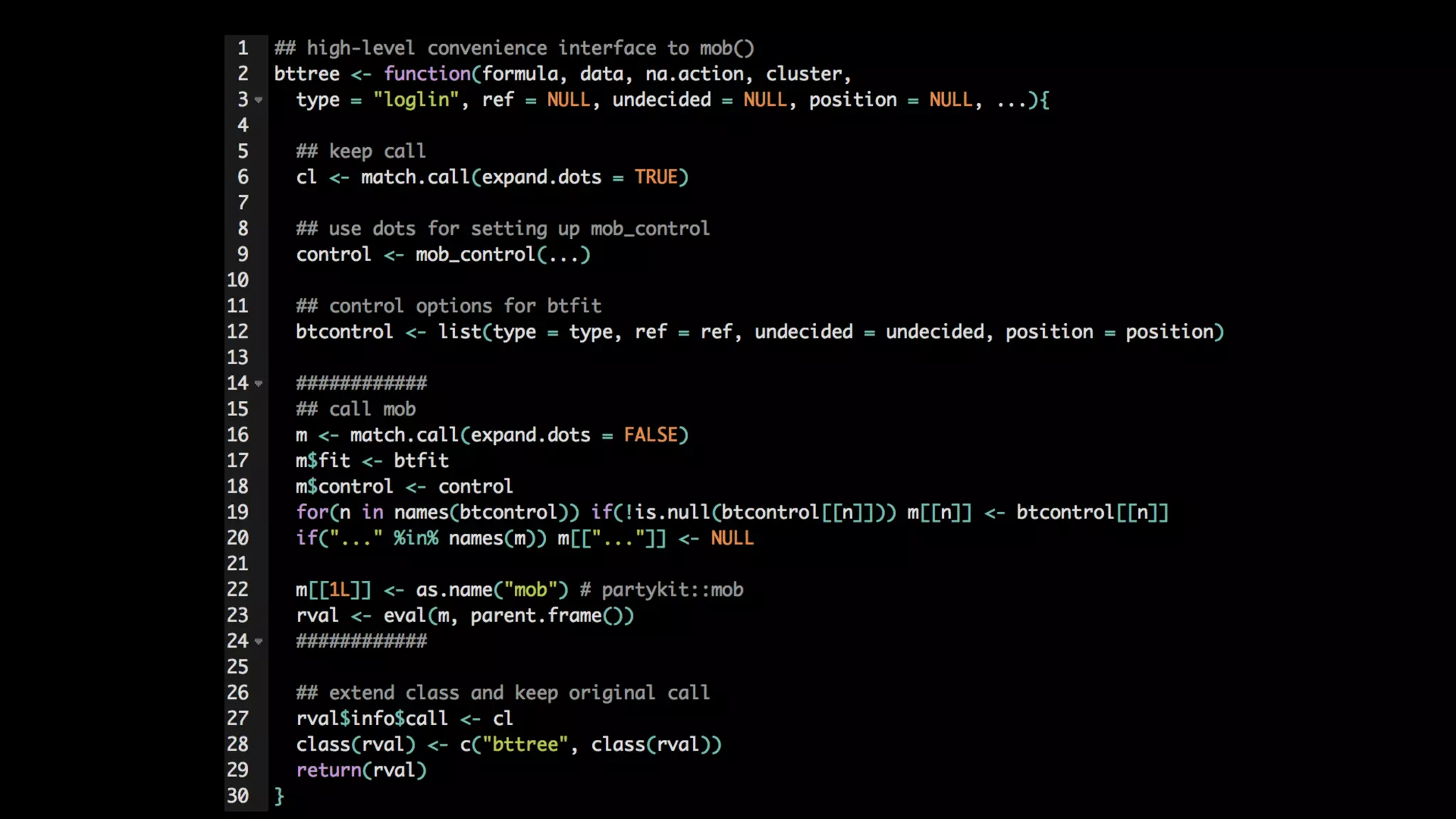
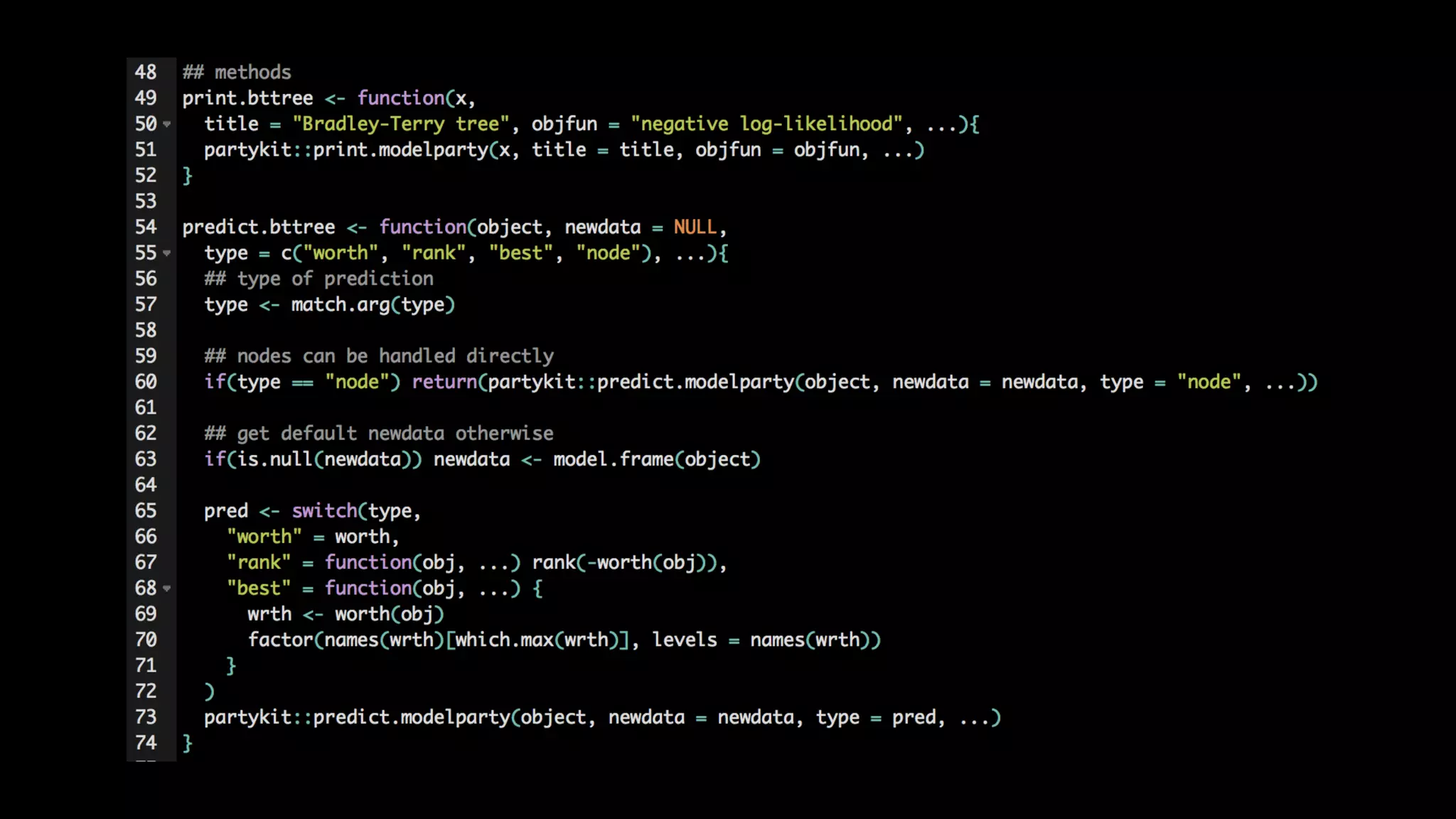
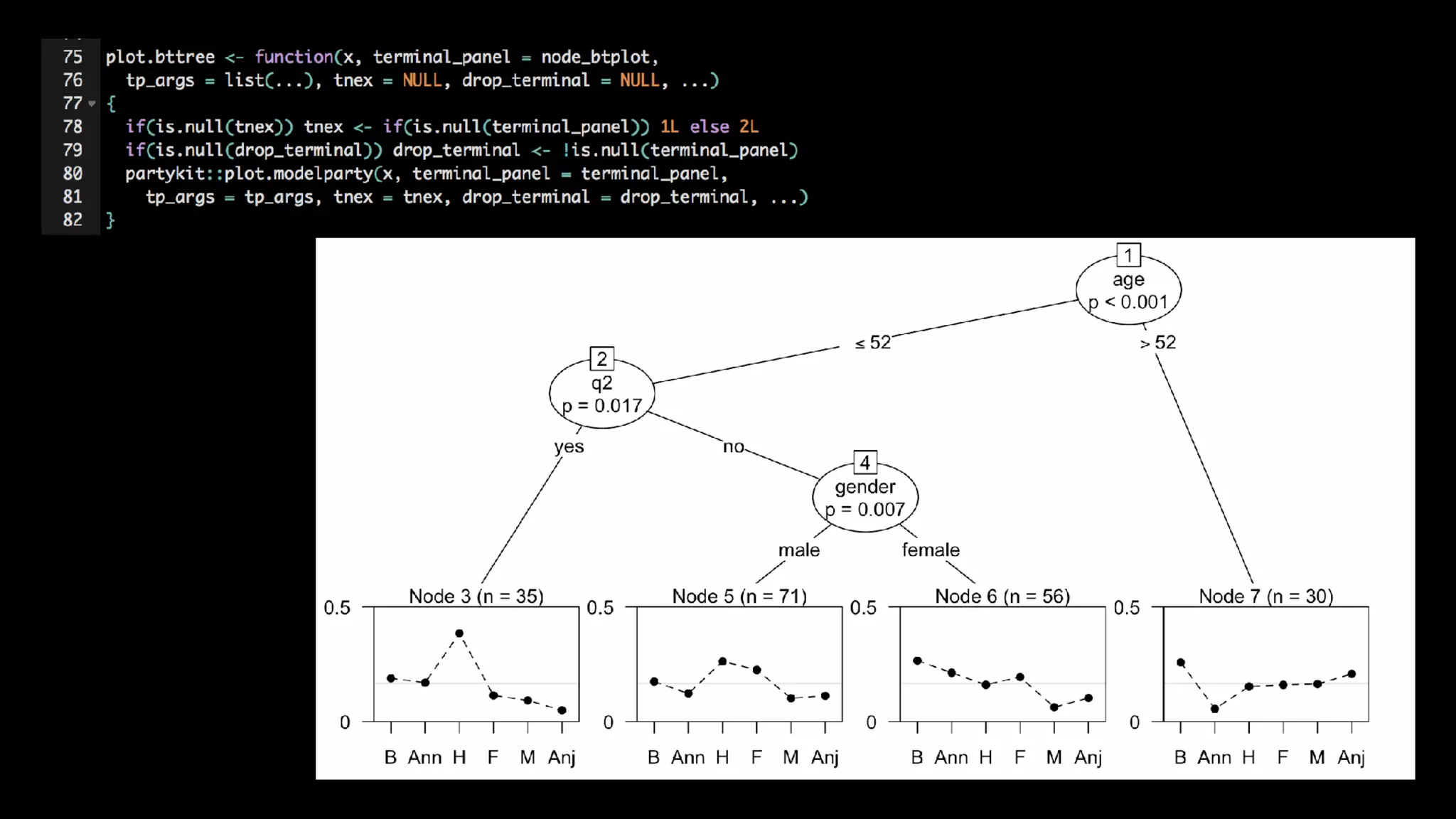
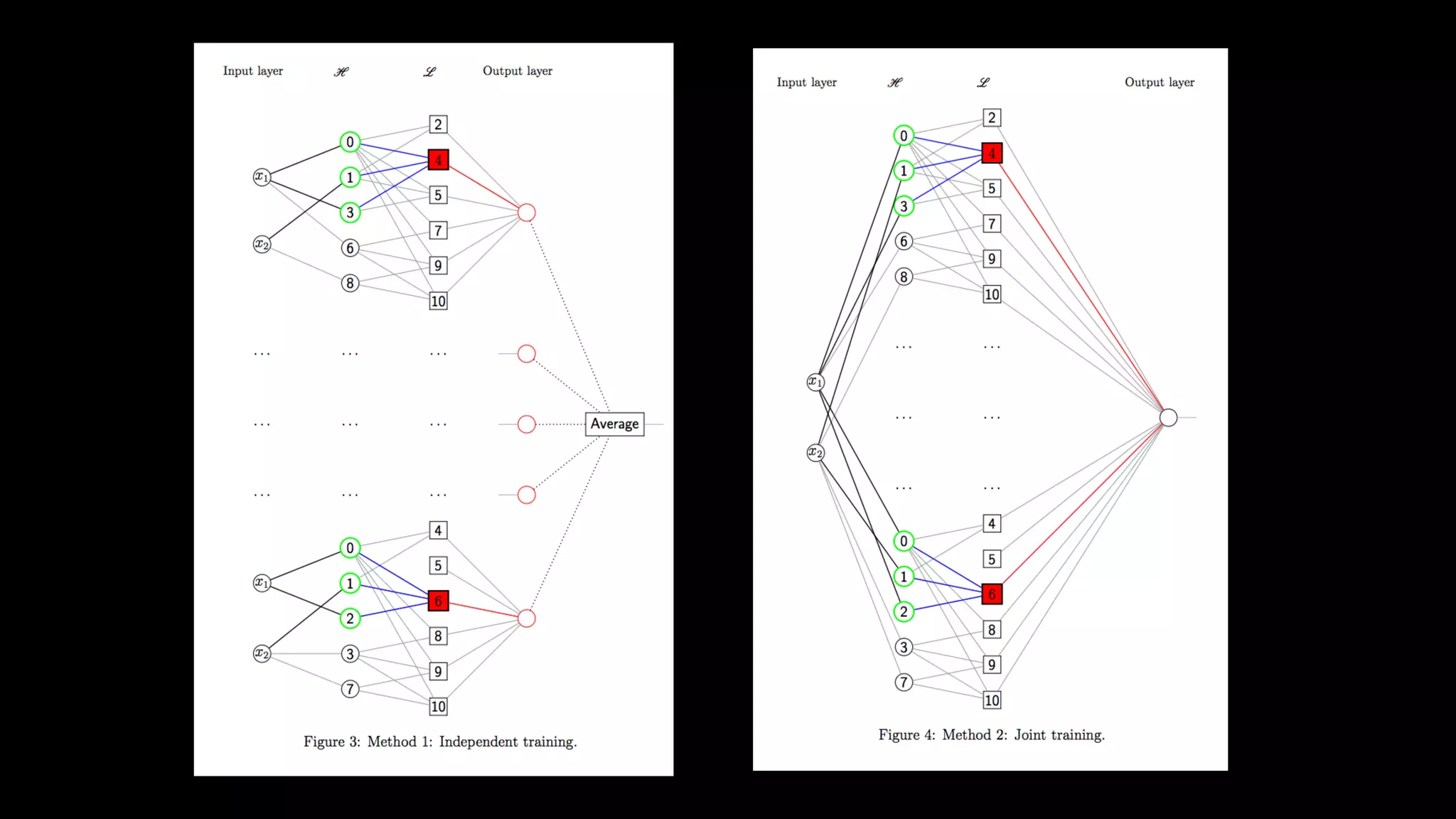
This document discusses the history and implementation of regression tree models. It begins by covering early tree models from the 1960s-1980s like CART and GUIDE. It then discusses more modern unified frameworks using modular packages in R like partykit and mob models. The document provides an example using a Bradley-Terry tree to model preferences from paired comparisons. It concludes by discussing potential extensions to deep learning methods.