Download to read offline












![From Voyager to your website: Using Linux Shell scripts and Oracle SQL*Plus to generate web pages.
ExLibris ELUNA 2012 Salt Lake City, UT 35 WRLC & George Washington University
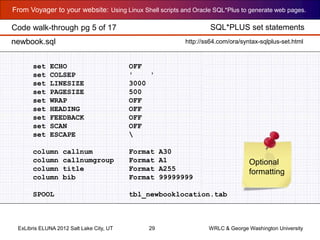
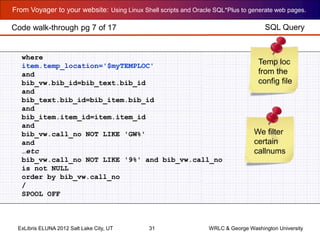
# Set the background color of each row.
if [ "$rowprint" == "0" ]; then
rowcolor=FFFFFF; rowprint=1;
else
rowcolor=E4DFE6; rowprint=0;
fi
# Generate HTML tags around the retrieved data
NEWROW="<TR BGCOLOR=#"$rowcolor" valign=TOP><TD grp="$td2">
"
CALLNUMBER="<A HREF="http://"$myOPAC"/cgi-bin/Pwebrecon.cgi?BBID=
"$td3"">"$td1"</A></TD>";
TITLE="<TD>"$td4"</TD>";
AUTHOR="<TD>"$td5" </TD>";
PUBLISHER="<TD>"$td6"</TD></TR>";
#
# Append each generated HTML line to the output file
echo $NEWROW $CALLNUMBER $TITLE $AUTHOR $PUBLISHER >> callnumberFactory.out
done
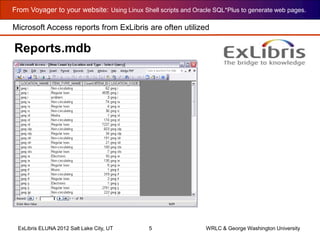
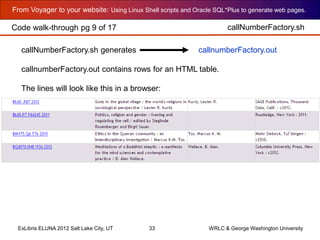
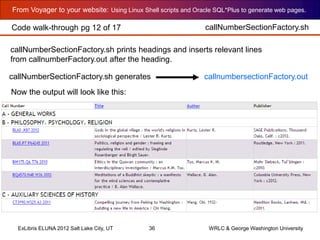
callNumberFactory.sh
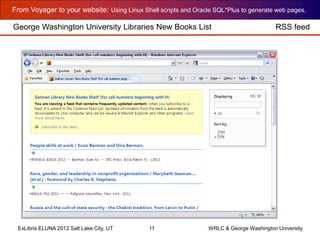
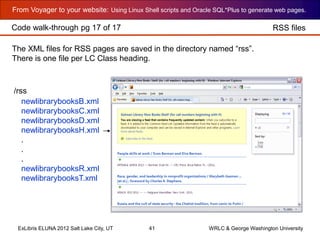
callNumberFactory.sh outputs HTML with field values
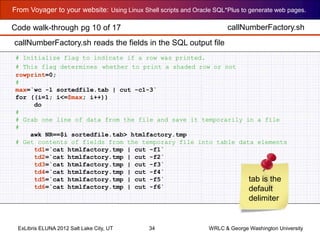
Code walk-through pg 11 of 17](https://image.slidesharecdn.com/cummingsdceluna2012-150420121209-conversion-gate02/85/Cummingsdceluna2012-35-320.jpg)



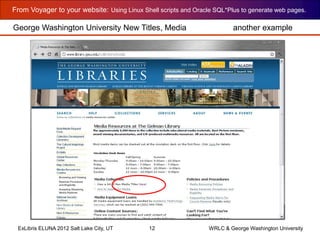
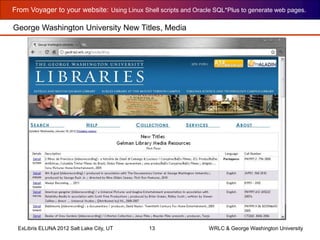
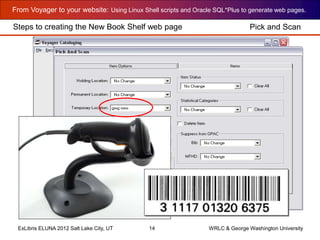
The document outlines the process for generating web pages from Voyager bibliographic data using Linux shell scripts and Oracle SQL*Plus, as presented at the Ex Libris Eluna 2012 conference. It covers installation instructions, including setting up SQL*Plus on Linux and creating a web page for new books using various scripts. Additionally, the document provides a step-by-step walkthrough of the scripting process and examples of the resulting web page structure and content.