Downloaded 19 times

![usage:
CSVtoXML
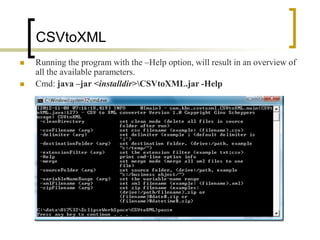
The program is a command-line driven java
program, that can run from within a batch-file or
script-file (like *.cmd, *. bat, …).
Usage:
java -jar <install dir>CSVtoXML.jar [Options]
Example:
java -jar “C:Program FilescsvtoxmlCSVtoXML.jar” -Help
Important !
All command-line-options are case-sensitive !](https://image.slidesharecdn.com/csvtoxmlconverter-130102141708-phpapp01/85/CSV-to-XML-Converter-4-320.jpg)












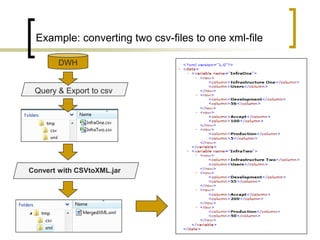
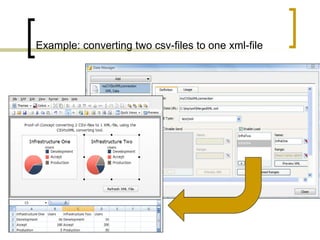
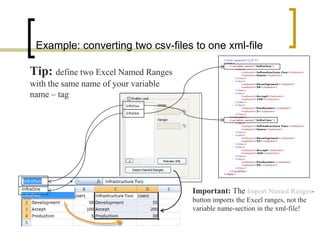
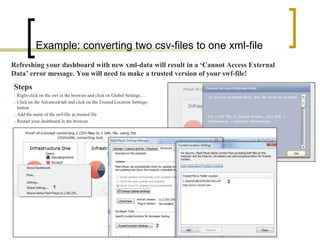


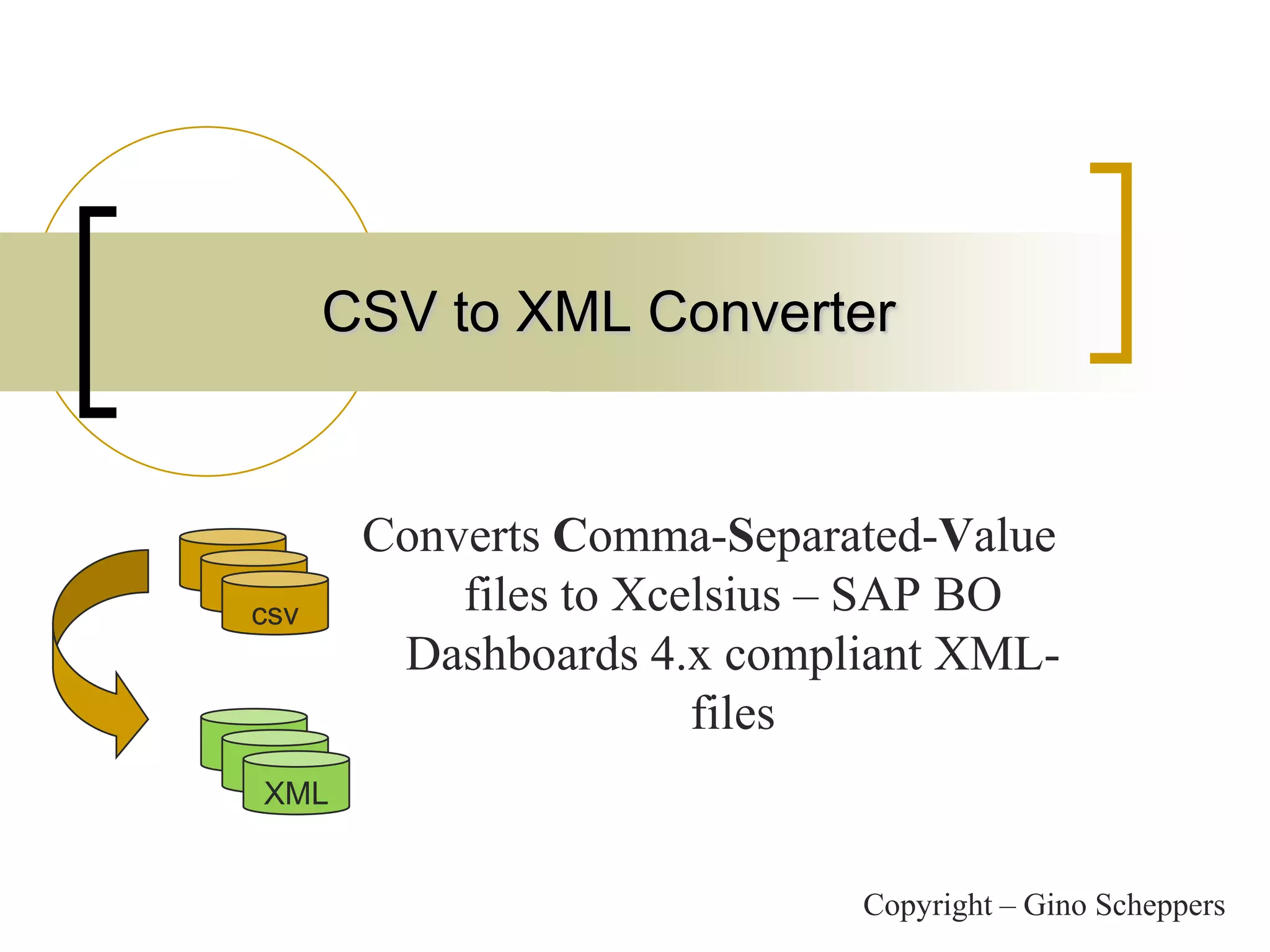
This document summarizes a Java program called CSVtoXML that converts comma-separated value (CSV) files to XML files compliant with SAP BusinessObjects Dashboards 4.x. The program is command-line driven and platform independent. It can convert single or multiple CSV files to single or merged XML files. The document provides details on the program's usage including available parameters to configure the conversion process and output files.
































