Downloaded 69 times

































![11/20/09CLA TSS Seminar, Farmington37with links to the following expression information:*Language of expression: English *Content type: Textand one manifestation:*Edition statement: 1st trade edition *Place of publication: New York *Publisher’s name: Delacorte Press *Date of publication: 1987 *Extent of text: 300 pages *Identifier for the manifestation: [ISBN]0385295901](https://image.slidesharecdn.com/connlibassn-091120212238-phpapp01/85/Crisis-or-Opportunity-37-320.jpg)

![11/20/09CLA TSS Seminar, Farmington39Translated to RDA/XML (with links below):<frbrManifestation ID="rda.basic/09”> <editionStatement>1st Trade Edition</> <placeOfPublication>New York<placeOfPublication> <publishersName>Delacorte Press</publishersName> <dateOfPublication>1987</dateOfPublication> <extentOfText>300 pages</extentOfText> <identifierForTheManifestation>[ISBN]0385295901</></frbrManifestation><frbrManifestatiion ID="rda.basic/09”><editionStatement>1st Trade Edition</><placeOfPublication>http://www.getty.edu/tgn/7007567</> <publishersName>http://onixpub.info/2039987</> <dateOfPublication>1987</dateOfPublication> <extentOfText>300 pages</extentOfText> <identifierForTheManifestation>urn:ISBN:0385295901</></frbrManifestation>](https://image.slidesharecdn.com/connlibassn-091120212238-phpapp01/85/Crisis-or-Opportunity-39-320.jpg)

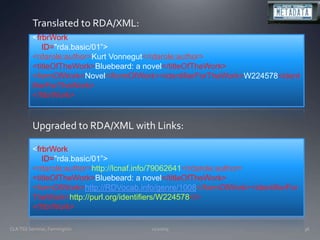
![11/20/09CLA TSS Seminar, Farmington41Jane begins her description by linking to the existing Work entity. She then creates an expression description:*Content type: text*Language of expression: Latvian*Translator:Grigulis, ArvīdsShe creates an authority record for the translator since none yet existed. She continues by creating a fuller description for the new manifestation, linking to the authority record for the Latvian publisher (what luck, it already existed!).*Title: [in Latvian]*Place of publication: Riga*Publisher’s name: Liesma*Date of publication: 1997*Extent of Text: 315 pages](https://image.slidesharecdn.com/connlibassn-091120212238-phpapp01/85/Crisis-or-Opportunity-41-320.jpg)

![11/20/09CLA TSS Seminar, Farmington43Translated to RDA/XML (with links below):<frbrManifestation ID="rda.basic/09”> <title>[in Latvian]</> <placeOfPublication>Riga<placeOfPublication> <publishersName>Liesma</publishersName> <dateOfPublication>1997</dateOfPublication> <extentOfText>315 pages</extentOfText></frbrManifestation><frbrManifestatiion ID="rda.basic/09”><placeOfPublication>http://www.getty.edu/tgn/7006484</> <publishersName>http://onixpub.info/6770094</> <dateOfPublication>1997</dateOfPublication> <extentOfText>315 pages</extentOfText></frbrManifestation>](https://image.slidesharecdn.com/connlibassn-091120212238-phpapp01/85/Crisis-or-Opportunity-43-320.jpg)
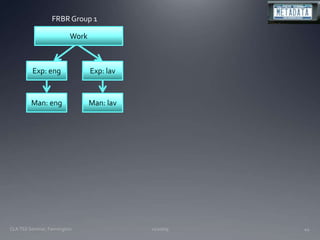
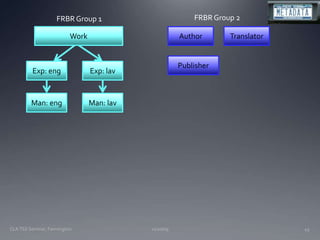
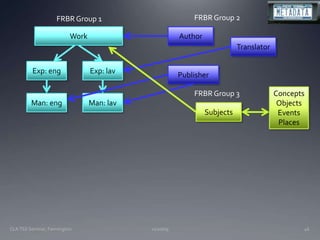
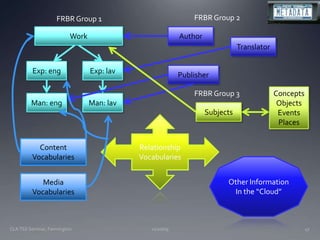

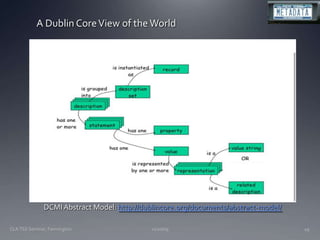
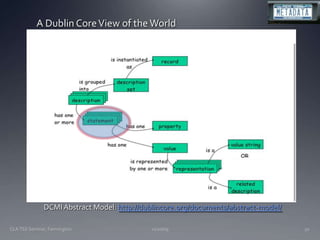
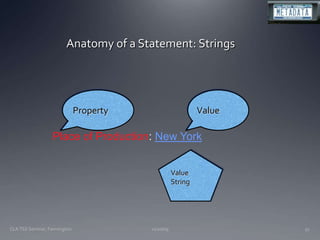




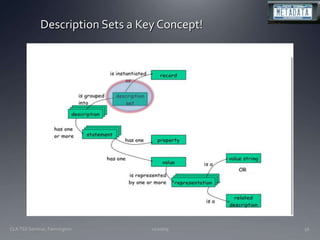

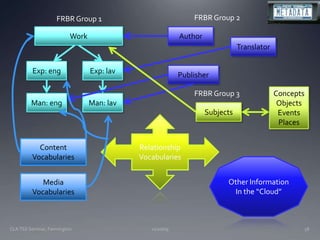
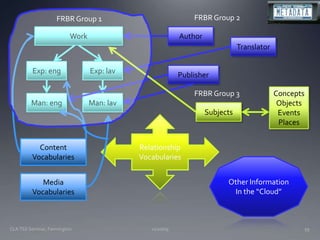
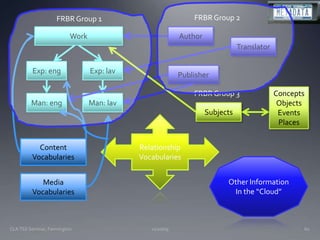
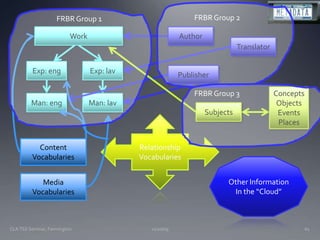


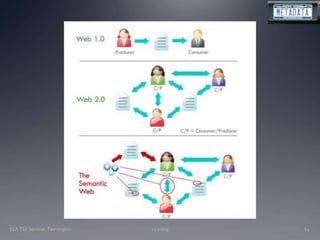




















The document discusses the challenges and opportunities facing catalogers and libraries as they transition to new standards like RDA that are designed to integrate library data with the semantic web. It provides an overview of RDA, how it differs from AACR2 and is better suited for the digital environment, and the technical requirements and changes needed for libraries to fully implement RDA and linked data. Catalogers will need to learn new skills and data modeling approaches as their role shifts to managing more abstract metadata and integrating user-contributed information.































































































