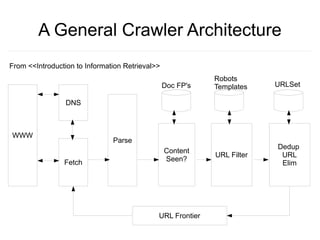
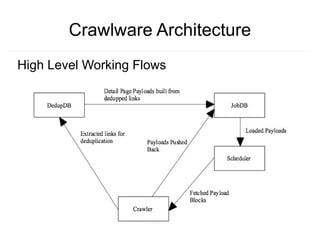
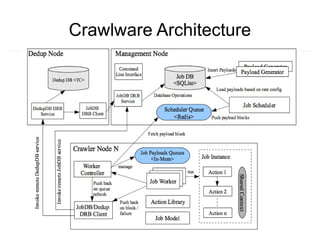
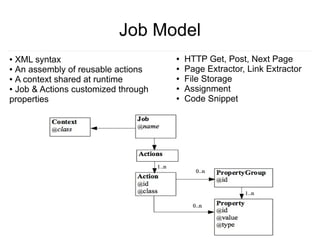
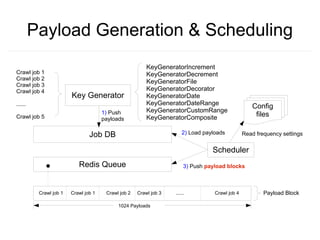
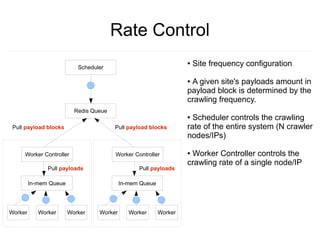
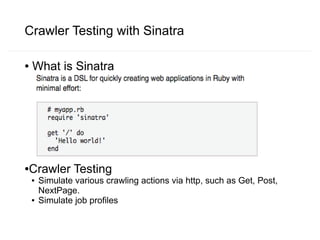
Crawlware is a distributed deep web crawling system that enables scalable and efficient crawls across multiple machines. It uses a job model with reusable actions to customize crawls and extracts data through complex queries. Key components include a payload generator that schedules crawls in parallel across sites, rate control to regulate the crawl rate, and auto-deduplication of extracted links. Testing is done through a Sinatra simulation and problems like changing site loads, data freshness, and JavaScript rendering still need to be addressed.


















![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















