Downloaded 47 times


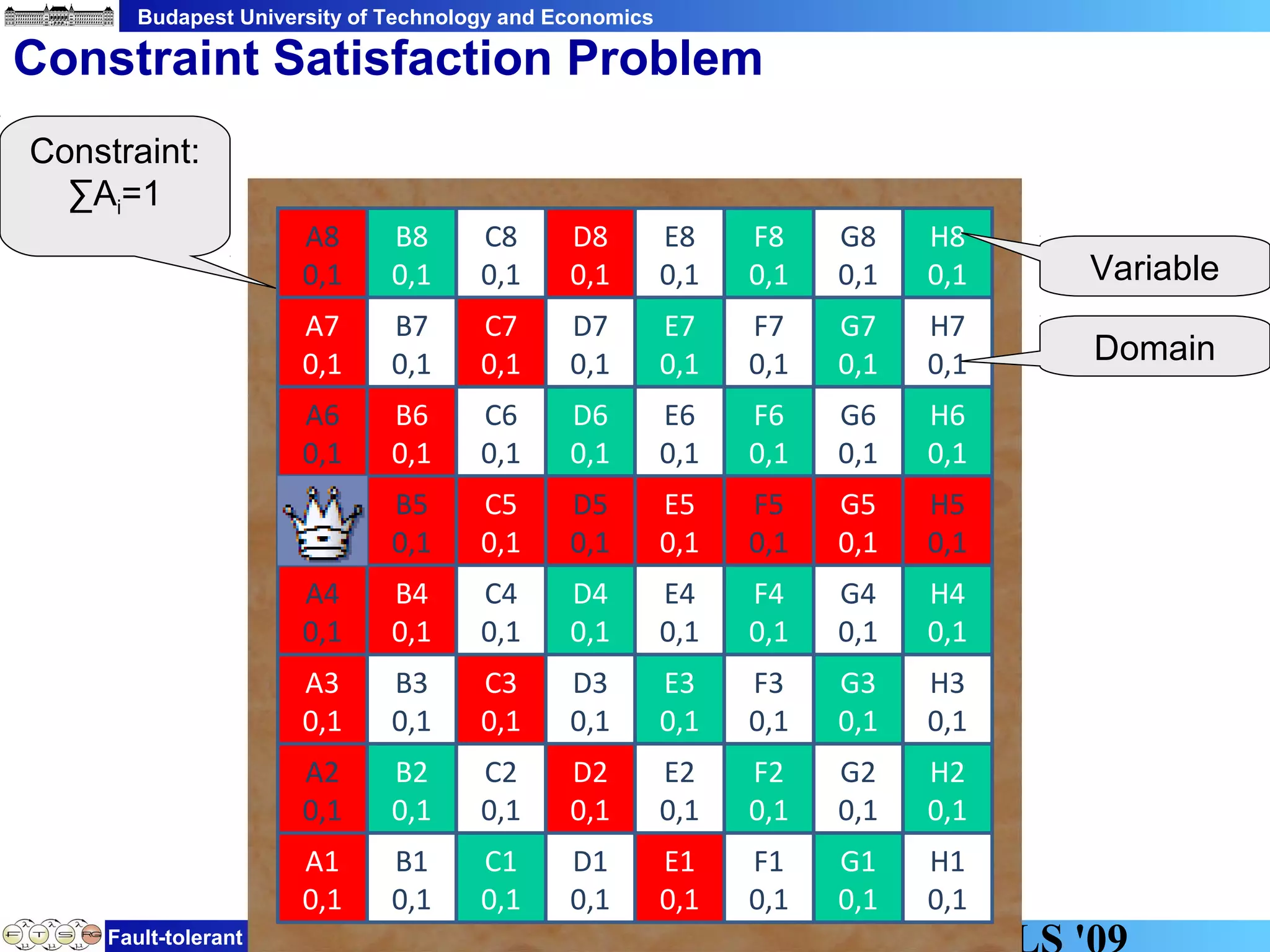
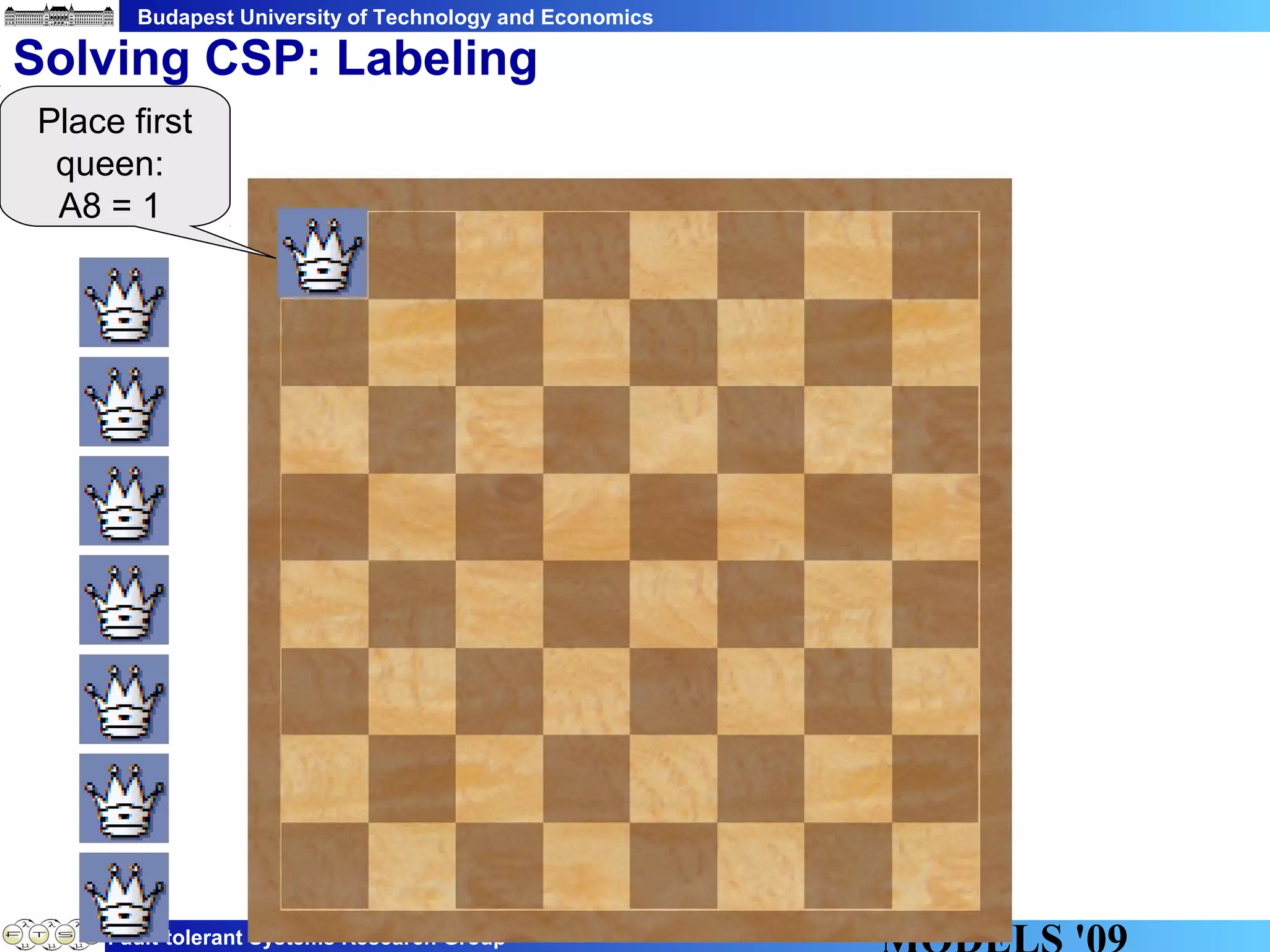

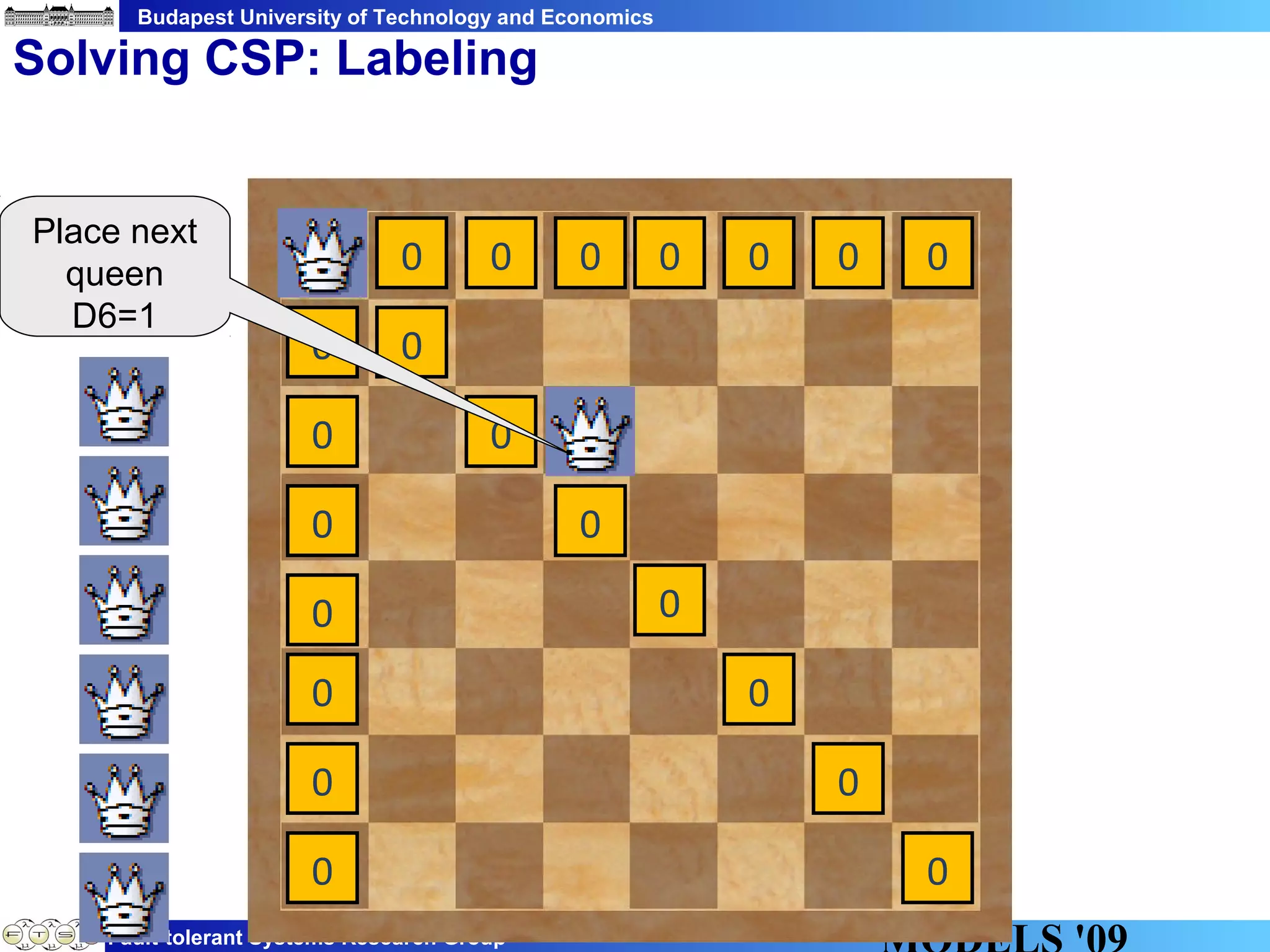

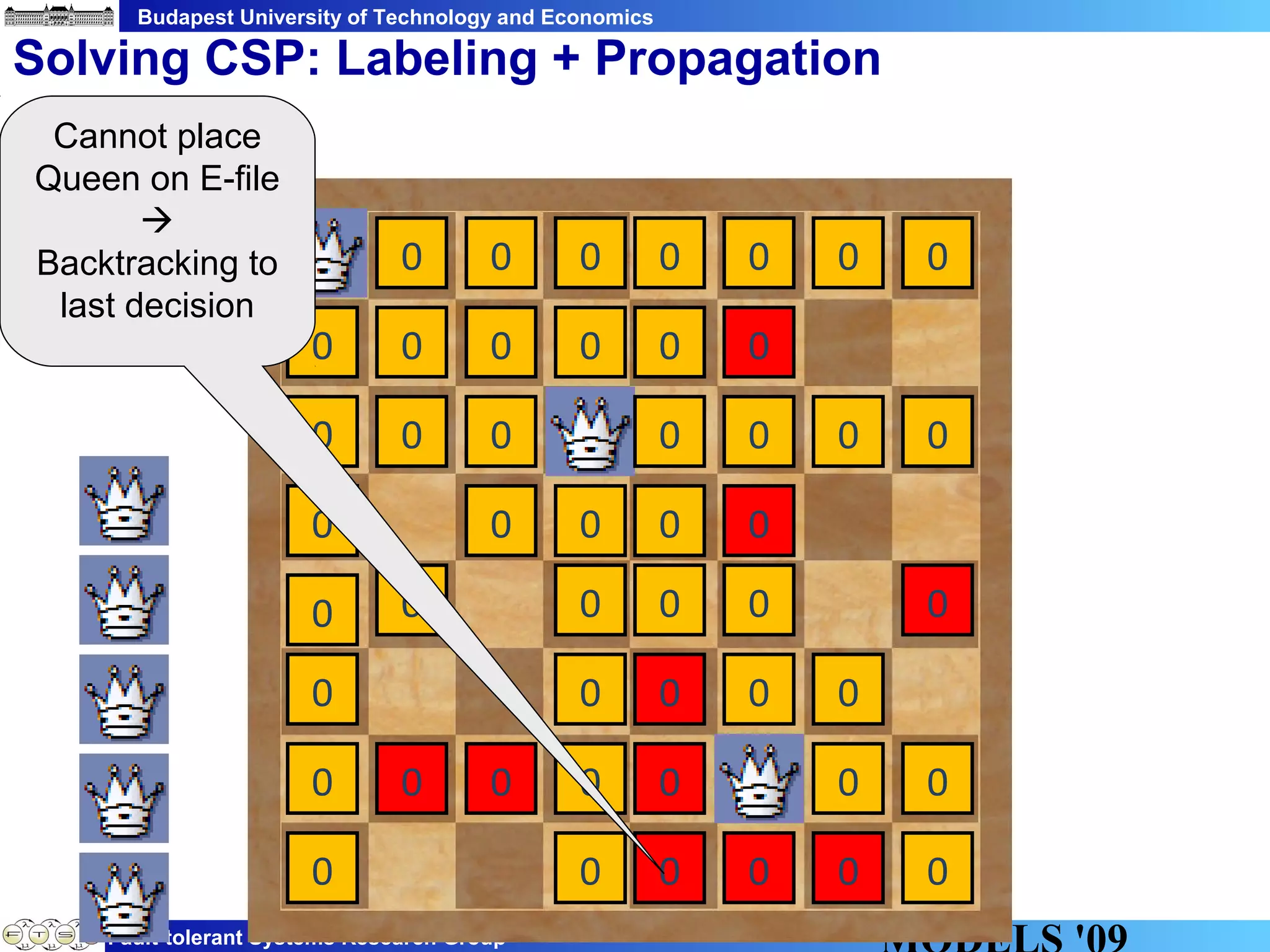










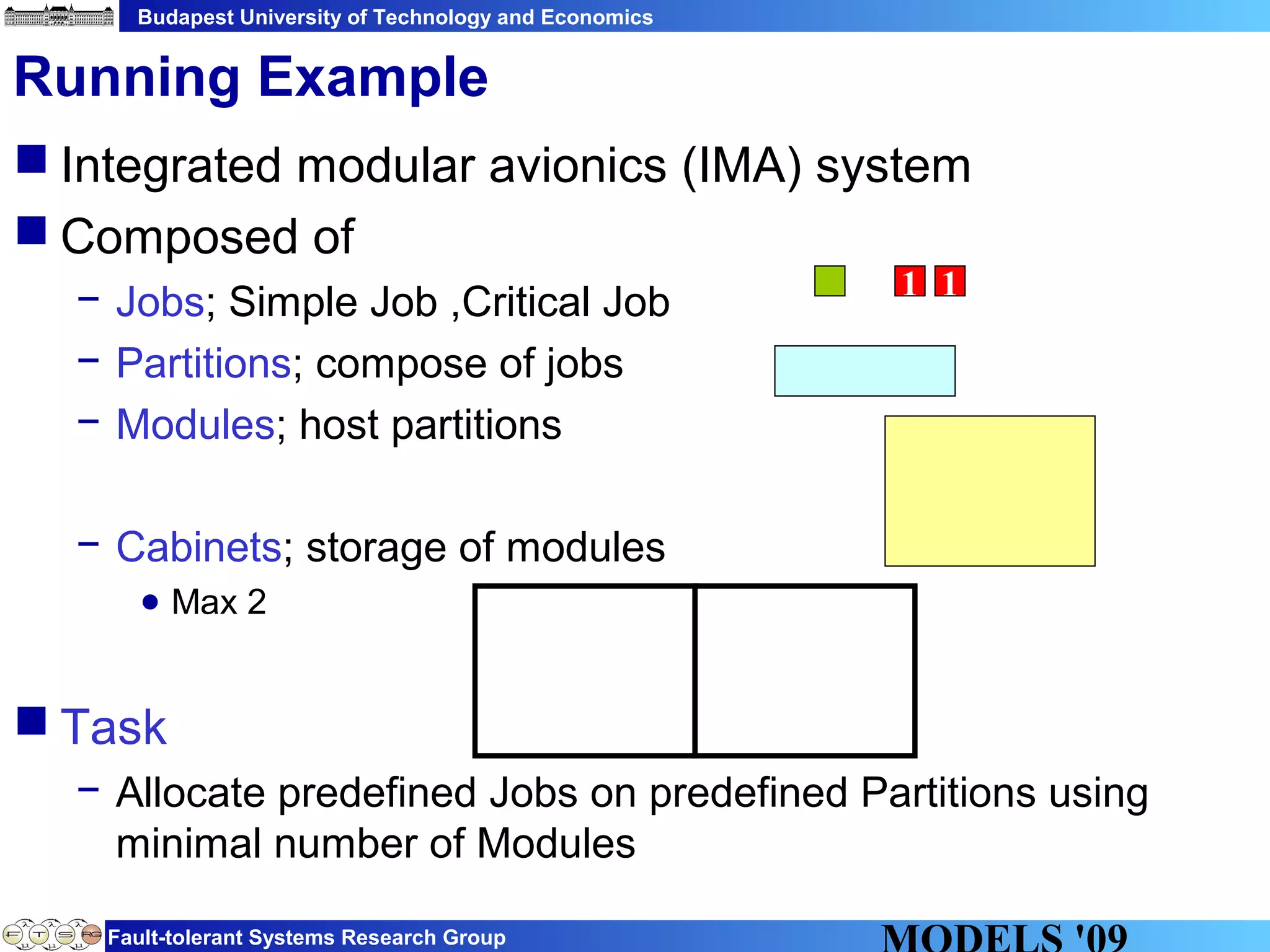

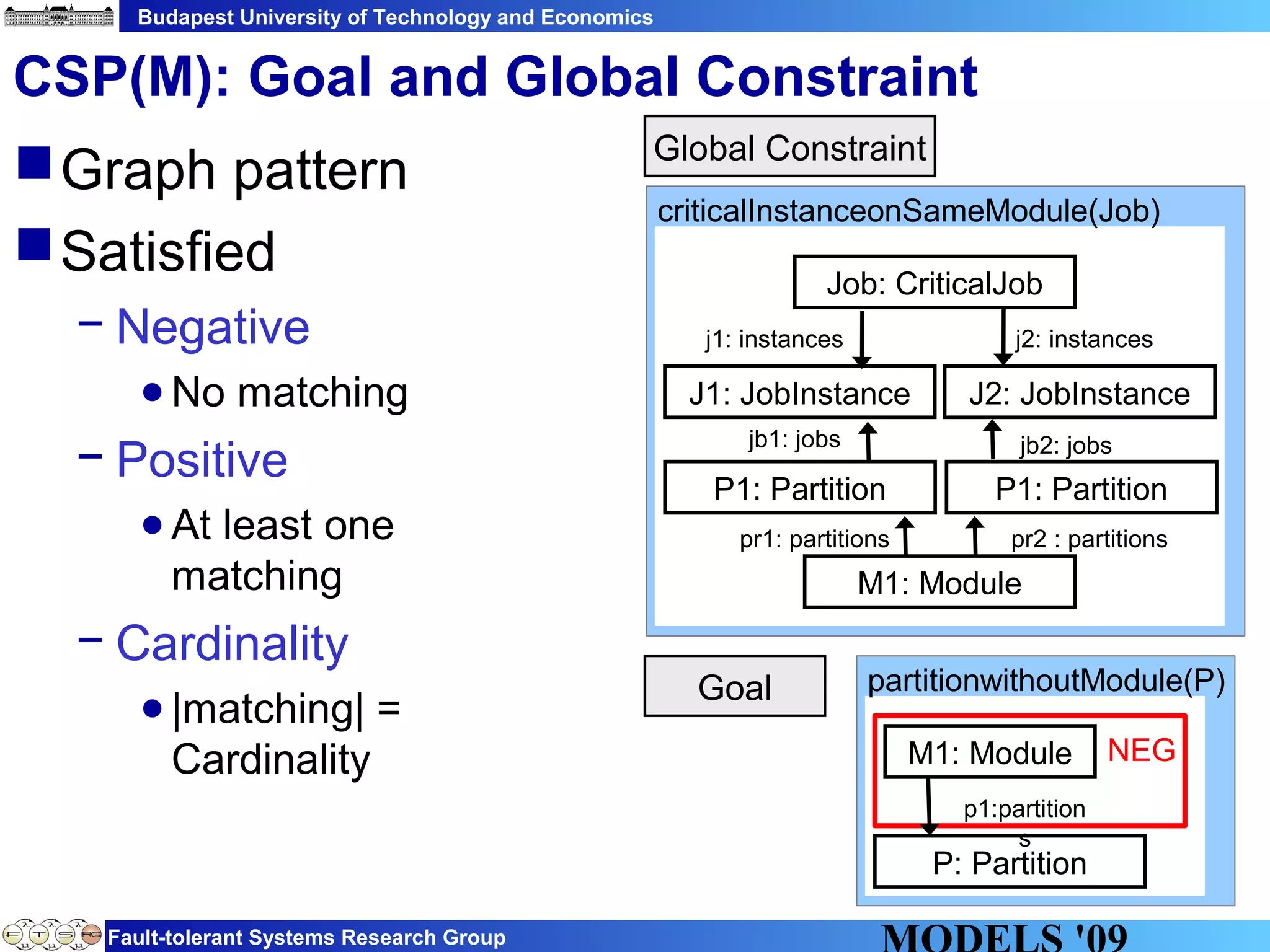
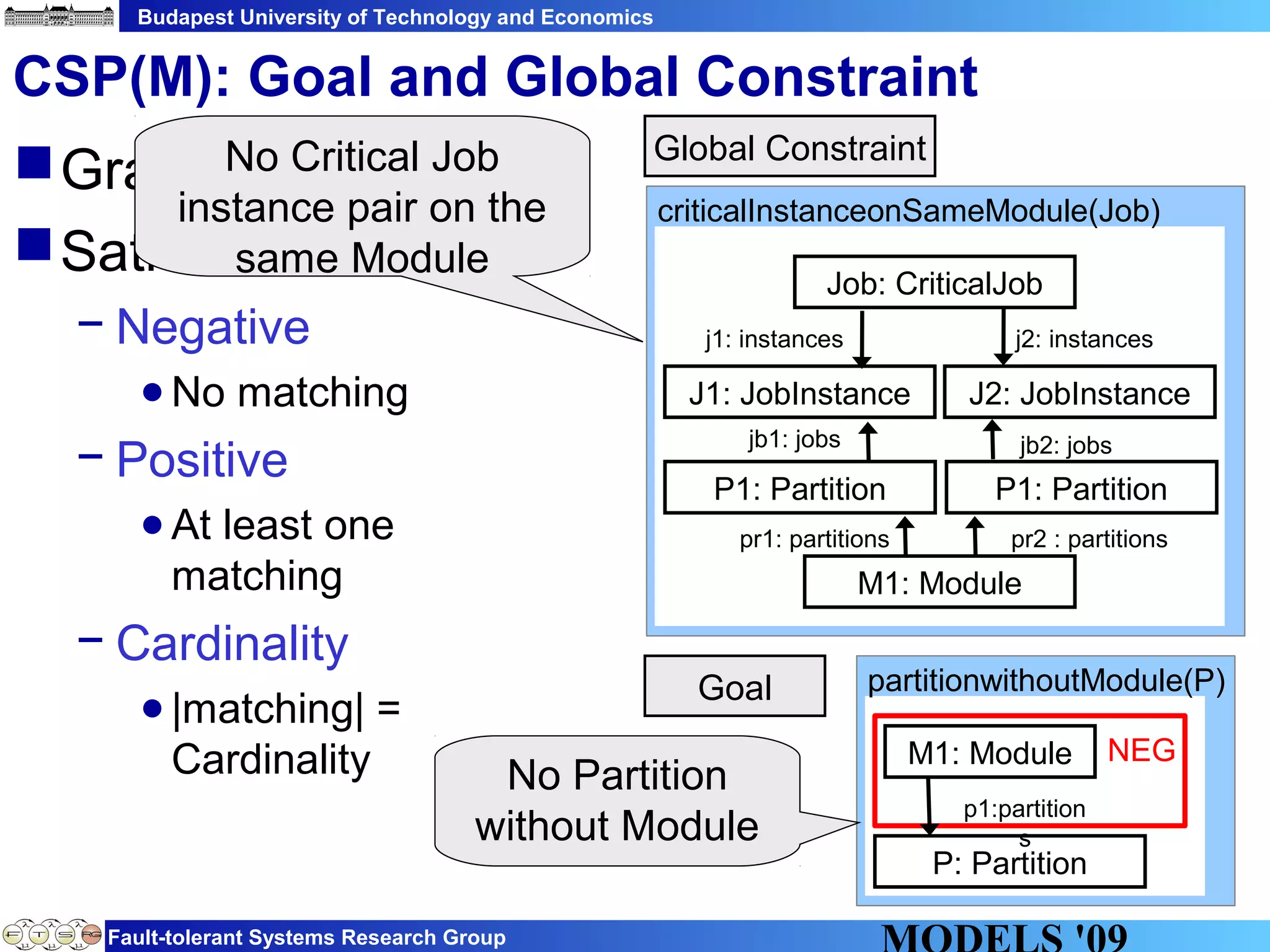
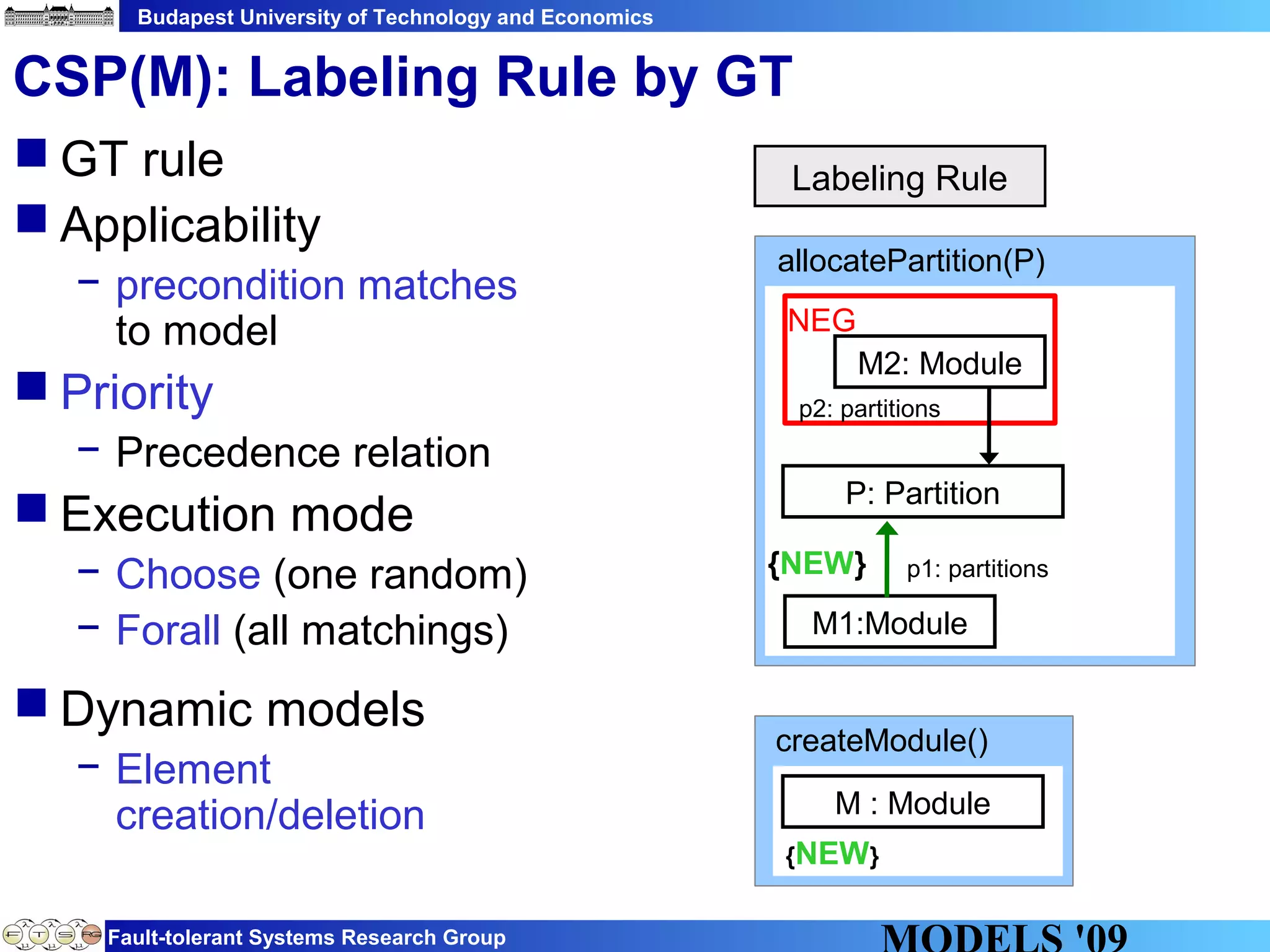


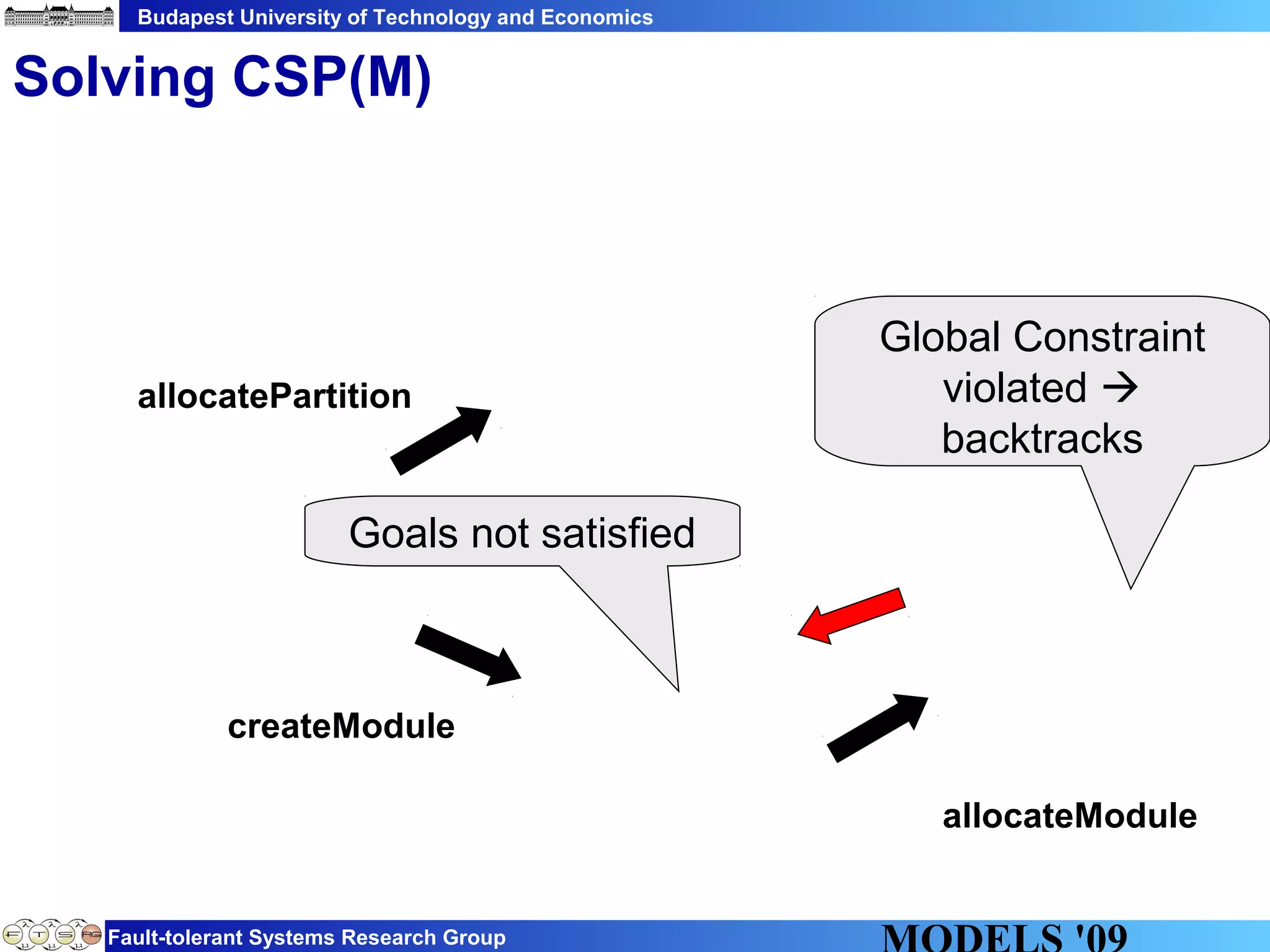





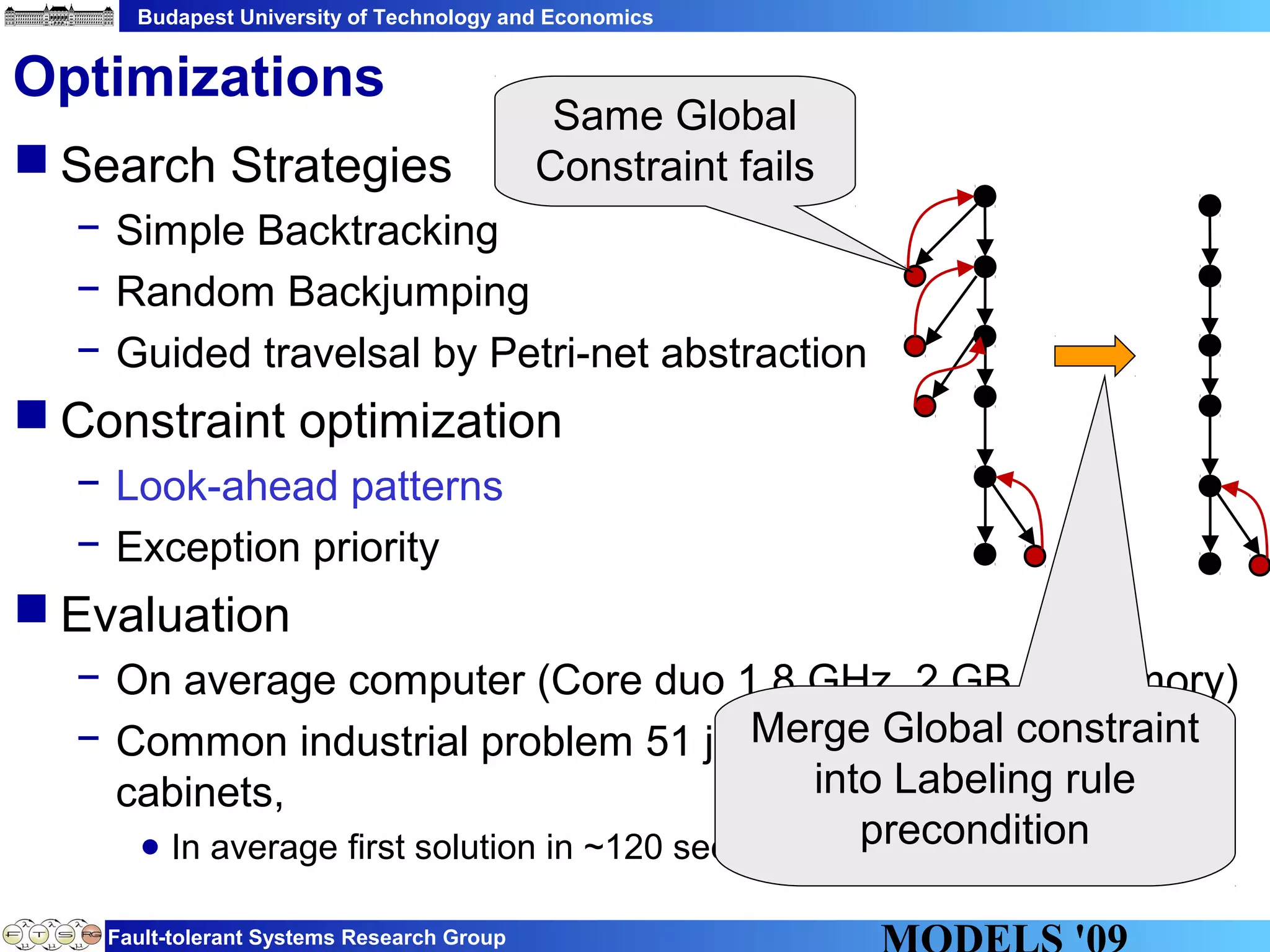



This document discusses constraint satisfaction problems over models (CSP(M)). It defines CSP(M) as being described by an initial model, a set of global constraints, goals, and labeling rules. It presents an example of allocating jobs to partitions in an integrated modular avionics system. Constraints and goals are defined as graph patterns. Labeling rules are defined using graph transformation rules. Solving CSP(M) involves applying labeling rules to reach a state satisfying all constraints and goals, backtracking if needed. The document outlines an implementation over VIATRA2 and discusses optimizations and future work.


































































