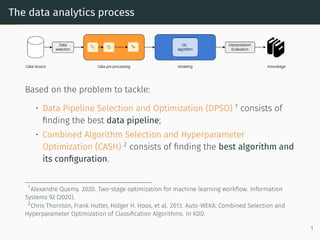
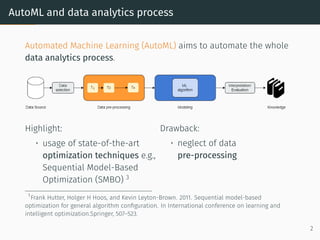
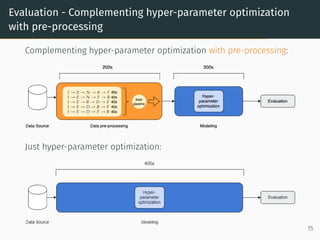
The document discusses effective data pre-processing techniques for automated machine learning (AutoML), emphasizing the importance of optimized data pipelines and algorithm configurations. It presents a framework for selecting data transformations, evaluates the effectiveness of these prototypes, and highlights that pre-processing optimization can significantly enhance predictive accuracy while being cost-effective. Future work aims to explore datasets that are less responsive to pre-processing and to integrate a meta-learning module into the approach.