Download to read offline




![4
Chapter 3
1. a. false; b. false; c. false; d. true; e. true; f. true; g. false; h. false
2. a. valid
b. valid
c. invalid (p is a pointer variable and x is an int variable. The value of x cannot be assigned to p.)
d. valid
e. valid
f. invalid (*p is an int variable and q is a pointer variable. The value of q cannot be assigned to *p.)
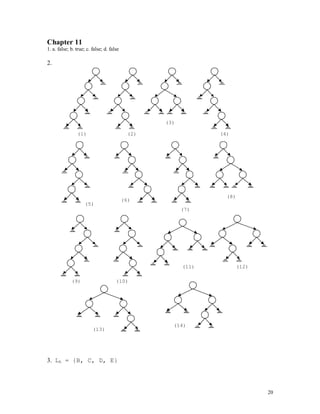
3.
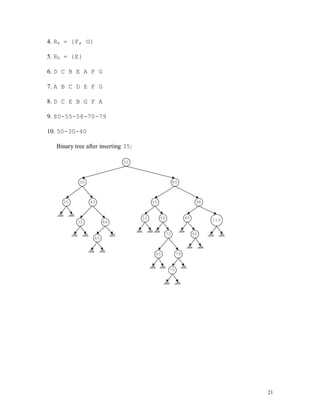
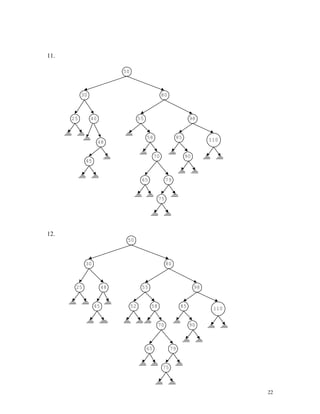
98 98
98 98
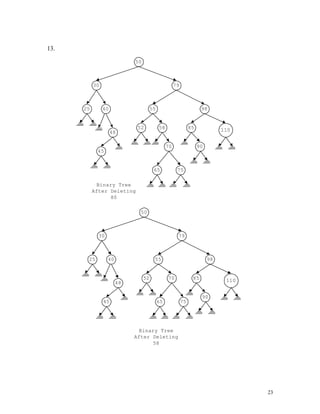
4.
35 78
78 78
5. b and c
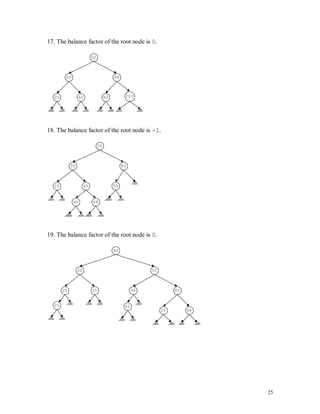
6. 39 39
7. 78 78
The statement in Line 5 copies the value of p into q. After this statement executes, both p and q point
to the same memory location. The statement in Line 7 deallocates the memory space pointed to by q,
which in turn invalidates both p and q. Therefore, the values printed by the statement in Line 8 are
unpredictable.
4 4 5 7 10 14 19 25 32 40
10. 10 15 20 25 30 35 40 45 50 55
11. In a shallow copy of data, two or more pointers points to the same memory space. In a deep copy of
data, each pointer has its own copy of the data.
12. The statement in Line 7 copies the value of p into q. After this statement executes, both p and q point
to the same array. The statement in Line 8 deallocates the memory space, which is an array, pointed to
by p, which in turns invalidates q. Therefore, the values printed by the statement in Line 10 are
unpredictable.
13.
Array p: 5 7 11 17 25
Array q: 25 17 11 7 5
14. The copy constructor makes a copy of the actual parameter data.
15. The copy constructor executes when a variable is passed by value, when a variable is declared and
initialized using another variable, and when the return value of a function is an object.
16. Classes with pointer data members should include the destructor, overload the assignment operator,
and explicitly provide the copy constructor by including it in the class definition and providing its
definition.
17.
a. (i) Function prototypes to appear in the definition of the class:
newString operator+(const newString& right) const;
newString operator+(char ch) const;
(ii) Definitions of the functions to overload +
newString newString::operator+(const newString& right) const
{
newString temp;
temp.slength = slength + right.slength;
temp.sPtr = new char[temp.slength + 1];](https://image.slidesharecdn.com/solutions-201005022908/85/Data-Structure-and-Algorithm-4-320.jpg)
![5
assert(temp.sPtr != NULL);
strcpy(temp.sPtr, sPtr);
strcat(temp.sPtr, right.sPtr);
return temp;
}
newString newString::operator+(char ch) const
{
newString temp;
char chStr[2];
chStr[0] = ch;
chStr[1] = '0';
temp.slength = slength + 1;
temp.sPtr = new char[temp.slength + 1];
assert(temp.sPtr != NULL);
strcpy(temp.sPtr, sPtr);
strcat(temp.sPtr, chStr);
return temp;
}
b.
(i) Function prototypes to appear in the definition of the class:
const newString& operator+=(const newString& right);
const newString& operator+=(char ch);
(ii) Definitions of the functions to overload +=
const newString& newString::operator+=
(const newString& right)
{
char *temp = sPtr;
slength += right.slength;
sPtr = new char[slength + 1];
assert(sPtr != NULL);
strcpy(sPtr,temp);
strcat(sPtr, right.sPtr);
delete []temp;
return *this;
}](https://image.slidesharecdn.com/solutions-201005022908/85/Data-Structure-and-Algorithm-5-320.jpg)
![6
const newString& newString::operator+=(char ch)
{
char *temp = sPtr;
char chStr[2];
chStr[0] = ch;
chStr[1] = '0';
slength += + 1;
sPtr = new char[slength + 1];
assert(sPtr != 0);
strcpy(sPtr,temp);
strcat(sPtr, chStr);
delete []temp;
return *this;
}
18.
a. The statement creates the arrayListType object intList of size 100. The elements of
intLits are of the type int.
b. The statement creates the arrayListType object stringList of size 1000. The elements
of stringList are of the type string.
c. The statement creates the arrayListType object salesList of size 100. The elements of
salesList are of the type double.
19.
polynomialType
+operator<<(ostream&, const polynomialType&): ostream&
+operator>>(istream&, polynomialType&): istream&
+operator+(const polynomialType&): polynomialType
+operator-(const polynomialType&): polynomialType
+operator*(const polynomialType&): polynomialType
+operator() (double): double
+min(int, int): int
+max(int, int): int
+polynomialType(int = 100)
arrayListType
polynomialType](https://image.slidesharecdn.com/solutions-201005022908/85/Data-Structure-and-Algorithm-6-320.jpg)


![9
Chapter 6
1. a. true; b. true; c. false; d. false; e. false
2. The case in which the solution to the problem is obtained directly.
3. The case in which the solution is defined in terms of smaller versions of itself.
4. A function is called directly recursive if it calls itself.
5. A function that calls another function and eventually results in the original function call is said to be
indirectly recursive.
6. A recursive function in which the last statement executed is the recursive call is called a tail recursive
function.
7. a. The statements in Lines 2 and 3.
b. The statements in Lines 4 and 5.
c. Any nonnegative integer.
d. It is a valid call. The value of mystery(0) is 0.
e. It is a valid call. The value of mystery(5) is 15.
f. It is an invalid call. It will result in an infinite recursion.
8. a. The statements in Lines 2, 3, 4, and 5.
b. The statements in Lines 6 and 7.
c. B
9. a. It does not produce any output.
b. It does not produce any output.
c. 5 6 7 8 9
d. It does not produce any output.
10. a. 15
b. 6
11. a. 2
b. 3
c. 5
d. 21
12. Suppose that low specifies the starting index and high specifies the ending index in the array. The
elements of the array between low and high are to be reversed.
if(low < high)
{
a. swap(list[low], list[high])
b. reverse elements between low + 1 and high - 1)
}
13.
otherwisenmmultiplym
nifm
nif
nmmultiply
)1,(
1
00
),(
14. a.
otherwiserncrnc
rifn
rnorrif
rnc
),1()1,1(
1
01
),(
b. C(5,3) = 10; C(9,4) = 126.](https://image.slidesharecdn.com/solutions-201005022908/85/Data-Structure-and-Algorithm-9-320.jpg)


![12
Chapter 8
1. a. queueFront = 50; queueRear = 0
b. queueFront = 51; queueRear = 99
2. a. queueFront = 99; queueRear = 26
b. queueFront = 0; queueRear = 25
3. a. queueFront = 25; queueRear = 76
b. queueFront = 26; queueRear = 75
4. a. queueFront = 99; queueRear = 26
b. queueFront = 0; queueRear = 25
5. 51
6. a. queueFront = 74; queueRear = 0
b. queueFront = 75; queueRear = 99. The position of the removed element was 75.
7. Queue Elements: 5 9 16 4 2
8. Queue Element = 0
Queue Element = 14
Queue Element = 22
Sorry, the queue is empty
Sorry, the queue is empty
Stack Element = 32
Stack Elements: 64 28 0
Queue Elements: 30
9. 5 16 5
10. The function mystery reverses the elements of a queue and also doubles the values of the queue
elements.
11.
template<class type>
void moveNthFront(queue<type>& q, int n)
{
vector<type> v(q.size());
int count = 1;
int index = 1;
if(1 <= n && n <= q.size())
{
while(count < n)
{
v[index] = q.front();
q.pop();
count++;
index++;
}
v[0] = q.front();](https://image.slidesharecdn.com/solutions-201005022908/85/Data-Structure-and-Algorithm-12-320.jpg)
![13
q.pop();
while(!q.empty())
{
v[index] = q.front();
q.pop();
index++;
}
for(index = 0; index < v.size(); index++)
q.push(v[index]);
}
else
cout<<"The value of n is out of range."<<endl;
}
12.
template <class Type>
void reverseStack(stackType<Type> &s, queueType<Type> &q)
{
Type elem;
while(!s.isEmptyStack())
{
elem = s.top();
s.pop();
q.addQueue(elem);
}
while(!q.isEmptyQueue())
{
elem = q.front();
q.deleteQueue();
s.push(elem);
}
}
13.
template <class Type>
void reverseQueue(queueType<Type> &q, stackType<Type> &s)
{
Type elem;
while(!q.isEmptyQueue())
{
elem = q.front();
q.deleteQueue();
s.push(elem);
}
while(!s.isEmptyStack())
{
elem = s.top();
s.pop();
q.addQueue(elem);](https://image.slidesharecdn.com/solutions-201005022908/85/Data-Structure-and-Algorithm-13-320.jpg)

![15
Chapter 9
1. a. false; b. true; c. false; d. false
2. a. 8; b. 6; c. 1; d. 8
3.
a.
Iteration first last mid list[mid] Number of comparisons
1 0 10 5 55 2
2 0 4 2 17 2
3 0 1 0 2 2
4 1 1 1 10 2
5 2 1 the loop stops unsuccessful search
This is an unsuccessful search. The total number of comparisons is 8.
b.
Iteration first last mid list[mid] Number of comparisons
1 0 10 5 55 2
2 0 4 2 17 2
3 3 4 3 45 2
4 4 4 4 49 1(found is true)
The item is found at location 4 and the total number of comparisons is 7.
c.
Iteration first last mid list[mid] Number of comparisons
1 0 10 5 55 2
2 6 10 8 92 2
3 9 10 9 98 1(found is true)
The item is found at location 9 and the total number of comparisons is 5.
d.
Iteration first last mid list[mid] Number of comparisons
1 0 10 5 55 2
2 6 10 8 92 2
3 9 10 9 98 2
4 10 10 10 110 2
5 11 10 the loop stops
This is an unsuccessful search. The total number of comparisons is 8.
4.
template<class elemType>
class orderedArrayListType: public arrayListType<elemType>
{
public:
int binarySearch(const elemType& item);
orderedArrayListType(int n = 100);
};
5. There are 30 buckets in the hash table and each bucket can hold 5 items.
6. Suppose that an item with key X is to be inserted in HT. We use the hash function to compute the index
h(X) of this item in HT. Suppose that h(X) = t. Then 0 h(X) HTSize – 1. If HT[t] is empty, we store](https://image.slidesharecdn.com/solutions-201005022908/85/Data-Structure-and-Algorithm-15-320.jpg)
![16
this item into this array slot. Suppose that HT[t] is already occupied by another item and so we have a
collision. In linear probing, starting at location t, we search the array sequentially to find the next
available array slot. In linear probing, we assume that the array is circular so that if the lower portion
of the array is full, we can continue the search in the top portion of the array.
7. Suppose that an item with key X is hashed at t, that is, h(X) = t, and 0 t HTSize - 1. Further
suppose that position t is already occupied. In quadratic probing, starting at position t, we linearly
search the array at locations (t + 1) % HTSize, (t + 22
) % HTSize = (t + 4) % HTSize, (t+32
) % HTSize
= (t+9) % HTSize, ..., (t + i2
) % HTSize. That is, the probe sequence is: t, (t + 1) % HTSize, (t + 22
) %
HTSize, (t+32
) % HTSize, ..., (t + i2
) % HTSize.
8. In double hashing, if a collision occurs at h(X), the probe sequence is generated by using the rule:
(h(X) + i * h (X)) % HTSize
where h is the second hash function.
9. 30, 31, 34, 39, 46, and 55
10. a. The item with index 15 is inserted at HT[15]; the item with index 101 is inserted at HT[0]; the
item with index 116 is inserted at HT[16]; the item with index 0 is inserted at HT[1]; and the item with
index 217 is inserted at HT[17].
b. The item with index 15 is inserted at HT[15]; the item with index 101 is inserted at HT[0]; the
item with index 116 is inserted at HT[16]; the item with index 0 is inserted at HT[1]; and the item
with index 217 is inserted at HT[19].
11. 101
12. Suppose that an item, say R, is to be deleted from the hash table, HT. We first must find the index of R
in HT. To find the index of R, we apply the same criteria that was applied to R when R was inserted in
HT. Let us further assume that after inserting R another item, R, was inserted in HT and the home
position of R and R is the same. The probe sequence of R is contained in the probe sequence of R
because R was inserted in the hash table after R. Suppose that we simply delete R by marking the array
slot containing R as empty. If this array position stays empty, then while searching for R and following
its probe sequence, the search terminates at this empty array position. This gives the impression that R
is not in the table, which, of course, is incorrect. The item R cannot simply be deleted by marking its
position as empty from the hash table.
13. In open hashing, the hash table, HT, is an array of pointers. (For each j, 0 j HTSize – 1, HT[j] is a
pointer to a linked list.) Therefore, items are inserted into and deleted from a linked list, and so item
insertion and deletion are simple and straightforward. If the hash function is efficient, few keys are
hashed to the same home position. Thus, an average linked list is short, which results in a shorter
search length.
14. Suppose there are 1000 items, each requiring 1 word of storage. Chaining then requires a total of 3000
words of storage. On the other hand, with quadratic probing, if the hash table size is twice the number
of items, only 2000 words are required for the hash table. Also, if the table size is three times the
number of items, then in quadratic probing the keys are reasonably spread out. This results in fewer
collisions and so the search is fast.
15. Suppose there are 1000 items and each item requires 10 words of storage. Further suppose that each
pointer requires 1 word of storage. We then need 1000 words for the hash table, 10000 words for the
items, and 1000 words for the link in each node. A total of 12000 words of storage space, therefore, is
required to implement the chaining. On the other hand, if we use quadratic probing, if the hash table
size is twice the number of items, we need 20000 words of storage.](https://image.slidesharecdn.com/solutions-201005022908/85/Data-Structure-and-Algorithm-16-320.jpg)






This document contains solutions to exercises from chapters 1-8 of an algorithms textbook. The solutions include code snippets, explanations, and test cases. Key points addressed include asymptotic analysis of algorithms, data structures like linked lists and stacks/queues, and recursion.















































