Download as PDF, PPTX

































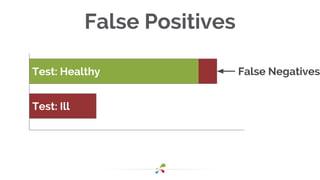





















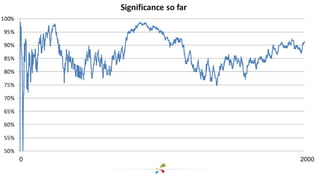
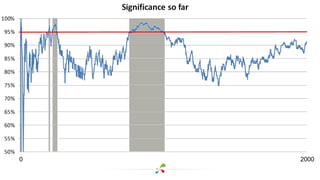


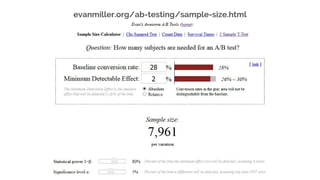


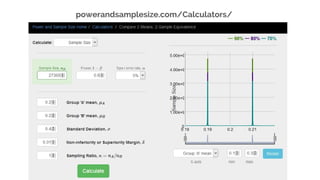







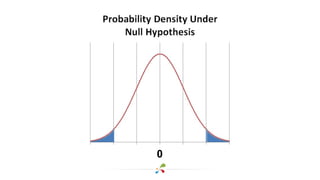
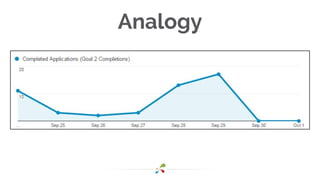











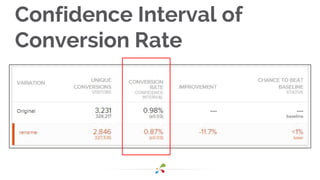



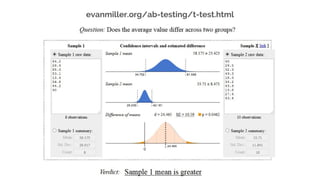























This document discusses best practices for interpreting A/B test results and making decisions based on those results. It cautions against relying solely on significance values and p-values, noting that these only indicate the likelihood of the data given the null hypothesis, not the likelihood of the null hypothesis being true. It emphasizes considering confidence intervals, choosing the right metrics like profit or revenue, and weighing the risks of false positives versus missed opportunities when deciding whether to roll out a change. The key takeaways are to incorporate risk into test design, focus on the real goal of increasing profit, and recognize that the stakes are generally lower for online experiments than medical trials.
























































