Download as PDF, PPTX





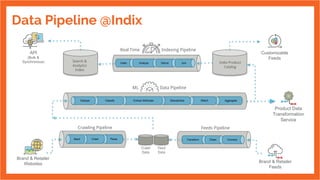















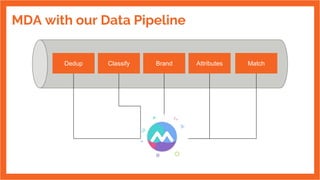
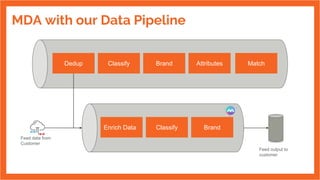
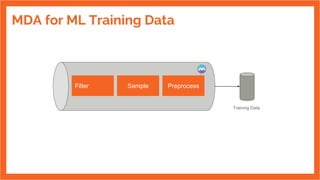

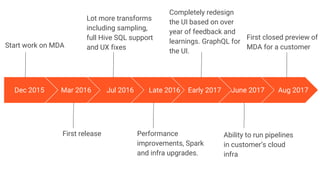



The document discusses the development of an internal data pipeline platform at Indix to democratize access to data. It describes the scale of data at Indix, including over 2.1 billion product URLs and 8 TB of HTML data crawled daily. Previously, the data was not discoverable, schemas changed and were hard to track, and using code limited who could access the data. The goals of the new platform were to enable easy discovery of data, transparent schemas, minimal coding needs, UI-based workflows for anyone to use, and optimized costs. The platform developed was called MDA (Marketplace of Datasets and Algorithms) and enabled SQL-based workflows using Spark. It has continued improving since its first release in 2016














































































