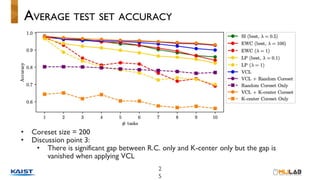
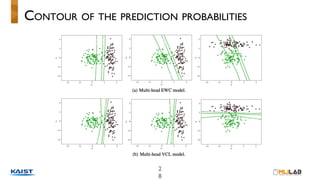
This document discusses variational continual learning for deep discriminative models. It covers continual learning backgrounds, variational inference for continual learning, the variational continual learning algorithm using a coreset, experiments comparing it to related methods, and discussion points. The variational continual learning algorithm uses a coreset to balance plasticity and stability when learning new tasks incrementally while avoiding catastrophic forgetting of old tasks. Experiments show it outperforms regularization-based methods on split MNIST and analyses the effect of coreset size and predictive uncertainty.
































![[Paper Review] Continual learning with deep generative replay](https://cdn.slidesharecdn.com/ss_thumbnails/continuallearningwithdeepgenerativereplay-170529100241-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Autonomous Reinforcement Learning: Formalism and Benchmarking](https://cdn.slidesharecdn.com/ss_thumbnails/20220311arlfinal-220314025127-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Variational Autoencoder with Arbitrary Conditioning](https://cdn.slidesharecdn.com/ss_thumbnails/190412nonakadlhacksv2-190422075347-thumbnail.jpg?width=640&height=640&fit=bounds)














































