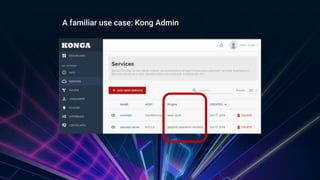
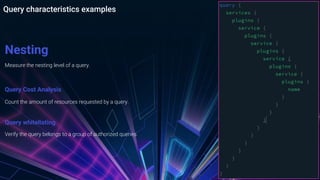
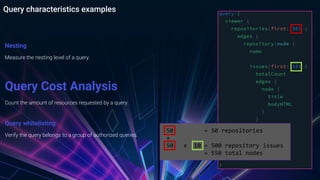
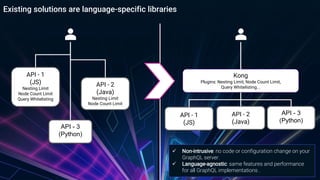
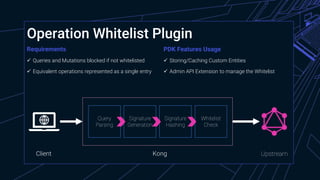
The document provides an overview of managing GraphQL APIs using Kong, highlighting differences between REST and GraphQL, and discussing the key features of GraphQL introduced by Facebook. It covers API management strategies such as query characteristics, nesting limits, and whitelisting, along with practical implementations of Kong plugins developed for enhanced security and efficiency. Additionally, it emphasizes the importance of Kong's extensibility and outlines future steps for improving GraphQL API management.





![Data Fetching with REST
HTTP GET /services
{
"next": null,
"data": [
{
"host": "10.0.2.2",
"created_at": 1560781137,
"connect_timeout": 60000,
"id": "3692da97-e066-46e6-9739-3da47cfe4abd",
"protocol": "http",
"name": "starwars-server",
"read_timeout": 60000,
"port": 8080,
"path": "/graphql",
"updated_at": 1561016983,
"retries": 5,
"write_timeout": 60000,
"tags": null
},
{
"host": "mockbin.org",
"created_at": 1560797940,
"connect_timeout": 60000,
"id": "81c4c6b5-746a-4421-ad0d-cddc0aa3ed87",
"protocol": "http",
"name": "mockbin",
"read_timeout": 60000,
"port": 80,
"path": "/request",
"updated_at": 1561017861,
"retries": 5,
"write_timeout": 60000,
"tags": null
}
]
}
HTTP GET /services/{service-id}/plugins x2
{
"next": null,
"data": [
{
"created_at": 1560860735,
"config": {
"block_introspection_queries": false
},
"id": "e0fcaa8b-167f-4f62-bf22-43dae04e91bf",
"service": {
"id": "3692da97-e066-46e6-9739-3da47cfe4abd"
},
"name": "graphql-operation-whitelist",
"protocols": [
"http",
"https"
],
"enabled": true,
"run_on": "first",
"consumer": null,
"route": null,
"tags": null
}
]
}](https://image.slidesharecdn.com/october2140pmconnectingthedots-kongforgraphqlendpoints-191203134356/85/Connecting-the-Dots-Kong-for-GraphQL-Endpoints-7-320.jpg)
![Data Fetching with REST vs GraphQL
query {
services {
name
host
created_at
plugins {
name
}
}
}
HTTP POST /kong-graphql-admin
HTTP GET /services
{
"next": null,
"data": [
{
"host": "10.0.2.2",
"created_at": 1560781137,
"connect_timeout": 60000,
"id": "3692da97-e066-46e6-9739-3da47cfe4abd",
"protocol": "http",
"name": "starwars-server",
"read_timeout": 60000,
"port": 8080,
"path": "/graphql",
"updated_at": 1561016983,
"retries": 5,
"write_timeout": 60000,
"tags": null
},
{
"host": "mockbin.org",
"created_at": 1560797940,
"connect_timeout": 60000,
"id": "81c4c6b5-746a-4421-ad0d-cddc0aa3ed87",
"protocol": "http",
"name": "mockbin",
"read_timeout": 60000,
"port": 80,
"path": "/request",
"updated_at": 1561017861,
"retries": 5,
"write_timeout": 60000,
"tags": null
}
]
}
HTTP GET /services/{service-id}/plugins x2
{
"next": null,
"data": [
{
"created_at": 1560860735,
"config": {
"block_introspection_queries": false
},
"id": "e0fcaa8b-167f-4f62-bf22-43dae04e91bf",
"service": {
"id": "3692da97-e066-46e6-9739-3da47cfe4abd"
},
"name": "graphql-operation-whitelist",
"protocols": [
"http",
"https"
],
"enabled": true,
"run_on": "first",
"consumer": null,
"route": null,
"tags": null
}
]
}](https://image.slidesharecdn.com/october2140pmconnectingthedots-kongforgraphqlendpoints-191203134356/85/Connecting-the-Dots-Kong-for-GraphQL-Endpoints-8-320.jpg)
![Data Fetching with REST vs GraphQL
query {
services {
name
host
created_at
plugins {
name
}
}
}
HTTP POST /kong-graphql-admin
{
"data": {
"services": [
{
"name": "starwars-server",
"host": "10.0.2.2",
"plugins": [
{
"name": "graphql-operation-whitelist"
}
],
"created_at": 1560781137
},
{
"name": "mockbin",
"host": "mockbin.org",
"plugins": [
{
"name": "basic-auth"
}
],
"created_at": 1560797940
}
]
HTTP GET /services
{
"next": null,
"data": [
{
"host": "10.0.2.2",
"created_at": 1560781137,
"connect_timeout": 60000,
"id": "3692da97-e066-46e6-9739-3da47cfe4abd",
"protocol": "http",
"name": "starwars-server",
"read_timeout": 60000,
"port": 8080,
"path": "/graphql",
"updated_at": 1561016983,
"retries": 5,
"write_timeout": 60000,
"tags": null
},
{
"host": "mockbin.org",
"created_at": 1560797940,
"connect_timeout": 60000,
"id": "81c4c6b5-746a-4421-ad0d-cddc0aa3ed87",
"protocol": "http",
"name": "mockbin",
"read_timeout": 60000,
"port": 80,
"path": "/request",
"updated_at": 1561017861,
"retries": 5,
"write_timeout": 60000,
"tags": null
}
]
}
HTTP GET /services/{service-id}/plugins x2
{
"next": null,
"data": [
{
"created_at": 1560860735,
"config": {
"block_introspection_queries": false
},
"id": "e0fcaa8b-167f-4f62-bf22-43dae04e91bf",
"service": {
"id": "3692da97-e066-46e6-9739-3da47cfe4abd"
},
"name": "graphql-operation-whitelist",
"protocols": [
"http",
"https"
],
"enabled": true,
"run_on": "first",
"consumer": null,
"route": null,
"tags": null
}
]
}](https://image.slidesharecdn.com/october2140pmconnectingthedots-kongforgraphqlendpoints-191203134356/85/Connecting-the-Dots-Kong-for-GraphQL-Endpoints-9-320.jpg)






















![[2018] 오픈스택 5년 운영의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra05-190131073350-thumbnail.jpg?width=640&height=640&fit=bounds)


















































