Download to read offline







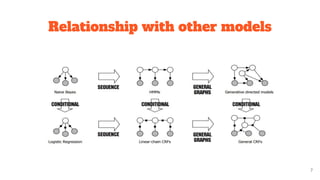










Conditional Random Fields (CRFs) are a probabilistic framework used for structured prediction, particularly in applications such as natural language processing and image recognition. They model the conditional distribution of output labels given input data, leveraging contextual information from previous labels. CRFs allow for highly expressive feature functions without needing to model distribution over irrelevant variables, thus enhancing prediction accuracy.




































































