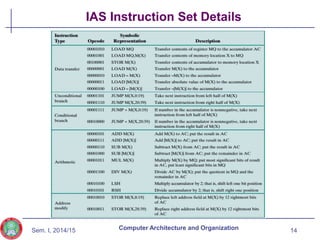
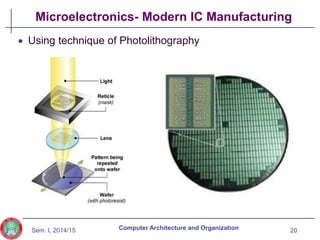
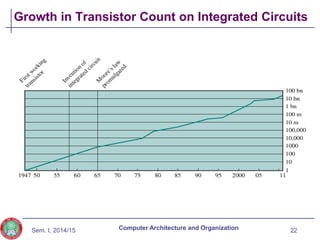
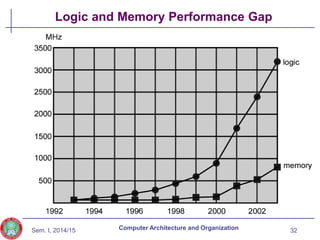
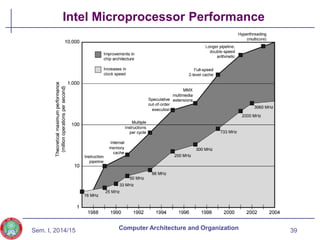
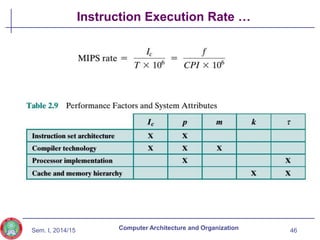
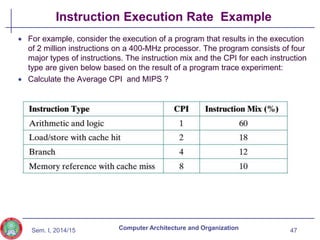
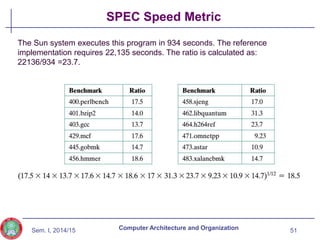
The document discusses the evolution of computer technology from the 1940s onwards. It begins with early computers like ENIAC which used vacuum tubes and were large, power-hungry machines. The stored program concept was developed by von Neumann. Transistors replaced vacuum tubes leading to smaller, cheaper computers. Integrated circuits allowed more components to be placed on chips according to Moore's Law. Microprocessors placed all CPU components on a single chip. Caches and parallel processing helped address the processor-memory speed gap. Multi-core processors improved performance through parallelism.









































![Sem. I, 2014/15
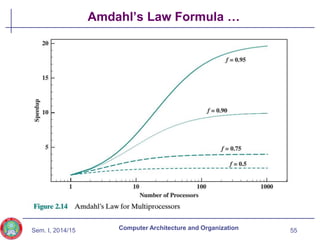
Amdahl’s Law
Gene Amdahl [AMDA67]
Speedup in one aspect of the technology or design does
not result in a corresponding improvement in performance
Potential speed up of program using multiple processors
Concluded that:
Code needs to be parallelizable
Speed up is bound, giving diminishing returns for more processors
Task dependent
Servers gain by maintaining multiple connections on multiple
processors
Databases can be split into parallel tasks
53
Computer Architecture and Organization](https://image.slidesharecdn.com/computerarchitectureoeceg316302computerevolutionperformance-240131184508-19df1f29/85/Computer_Architecture-O_ECEG_3163_02_computer_evolution_performance-pptx-53-320.jpg)























![CH01-COA10 computer_Stallings_(1)[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ch01-coa10estallings11-240330171942-a31169d8-thumbnail.jpg?width=640&height=640&fit=bounds)

























