A proceduredefinition is a declaration
that associates an identifier with a
statement (procedure body)
When a procedure name appears in an
executable statement, it is called at that
point
Formal parameters are the one that
appear in declaration. Actual
Parameters are the one that appear in
when a procedure is called
Procedure
3.
Each executionof a procedure is an activation of the
procedure.
The lifetime of an activation of a procedure p is the
sequence of steps between the first and last steps in
the execution of the procedure body.
If procedure is recursive, several activations may be
alive at the same time.
• If a and b are activations of two procedures then their lifetime
is either non overlapping or nested
• A procedure is recursive if an activation can begin before an
earlier activation of the same procedure has ended
Activation of a procedure
4.
Control flowssequentially
Execution of a procedure starts at the beginning of body
It returns control to place where procedure was called
from
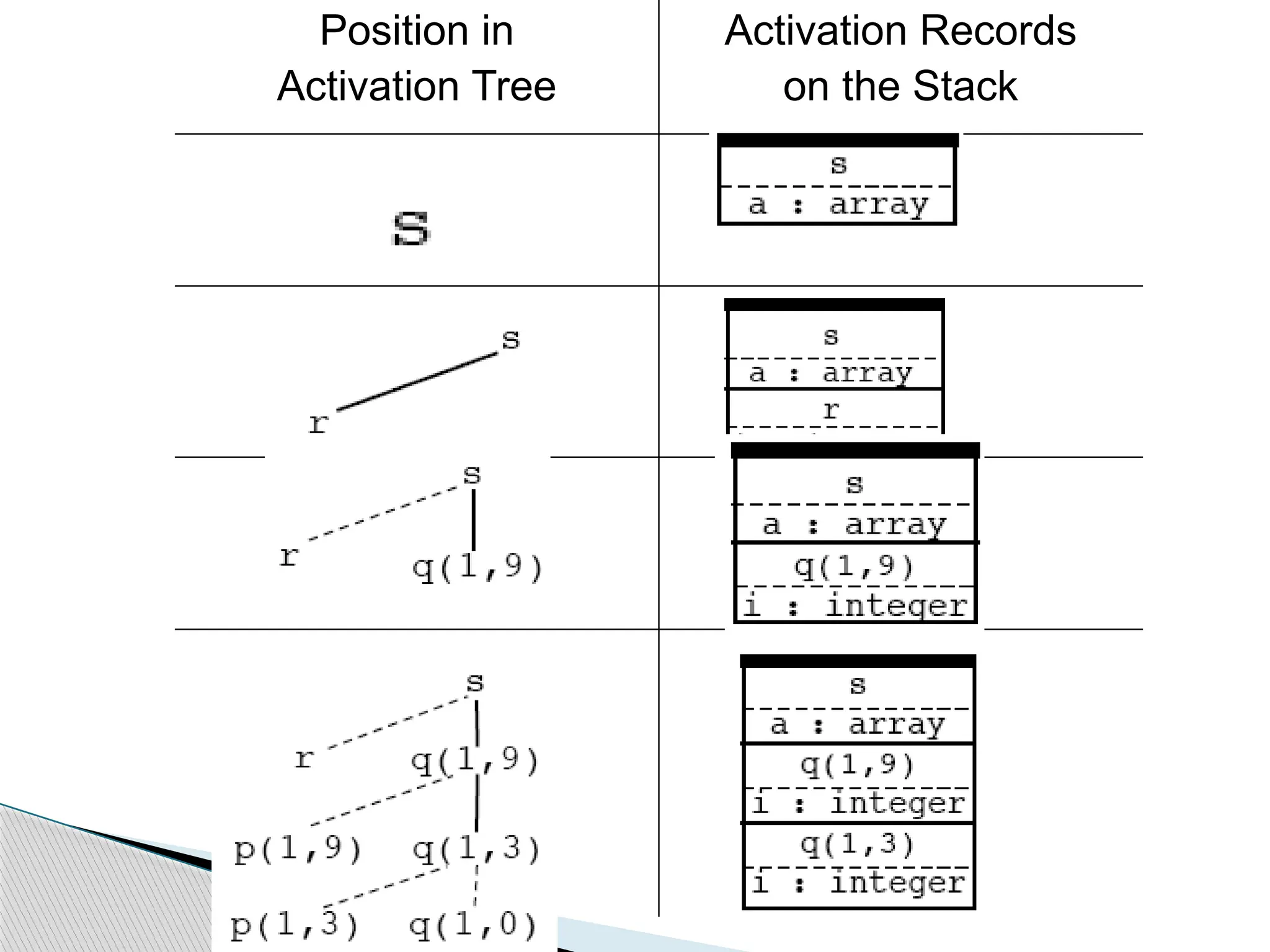
A tree can be used, called an activation tree, to depict the
way control enters and leaves activations
• The root represents the activation of main program
• Each node represents an activation of procedure
• The node a is parent of b if control flows from a to b
• The node a is to the left of node b if lifetime of a occurs
before b
Activation tree
The flowof control of the call quicksort(1,9) would be like
Execution begins ..
enter readarray
exit readarray
enter quicksort(1,9)
enter partition(1,9)
exit partition(1,9)
enter quicksort(1,3)
exit quicksort(1,3)
enter quicksort(5,9)
exit quicksort(5,9)
exit quicksort(1,9)
Execution terminates …
Activation of quicksort(1,9)
Flow ofcontrol in program corresponds to
depth first traversal of activation tree
◦ that starts at the root, visits a node before its
children, and recursively visits children at each node
in a left to right fashion.
Use a stack called control stack to keep track
of live procedure activations
Push the node when activation begins and
pop the node when activation ends
When the node n is at the top of the stack the
stack contains the nodes along the path from
n to the root
Control Stacks
9.
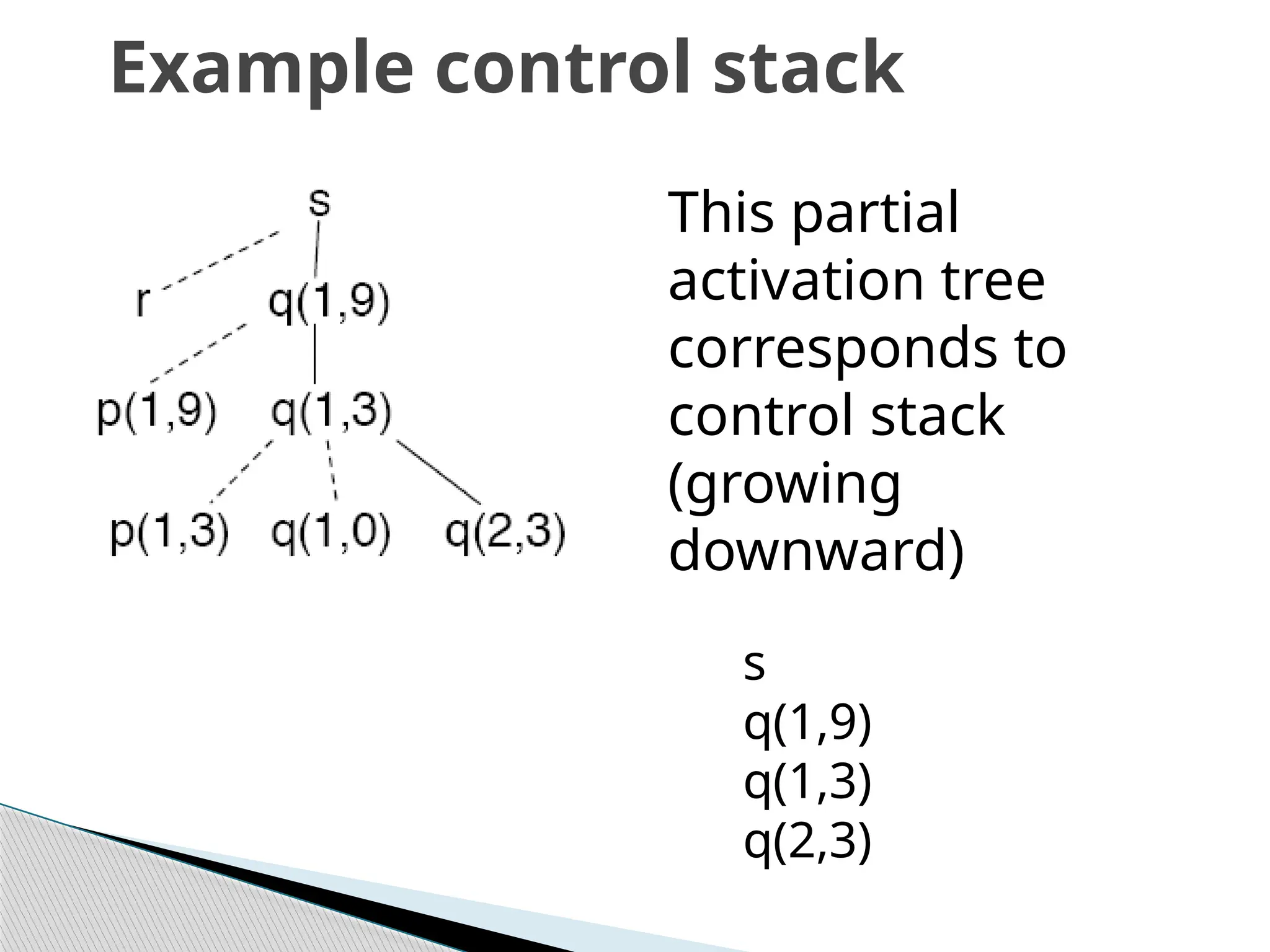
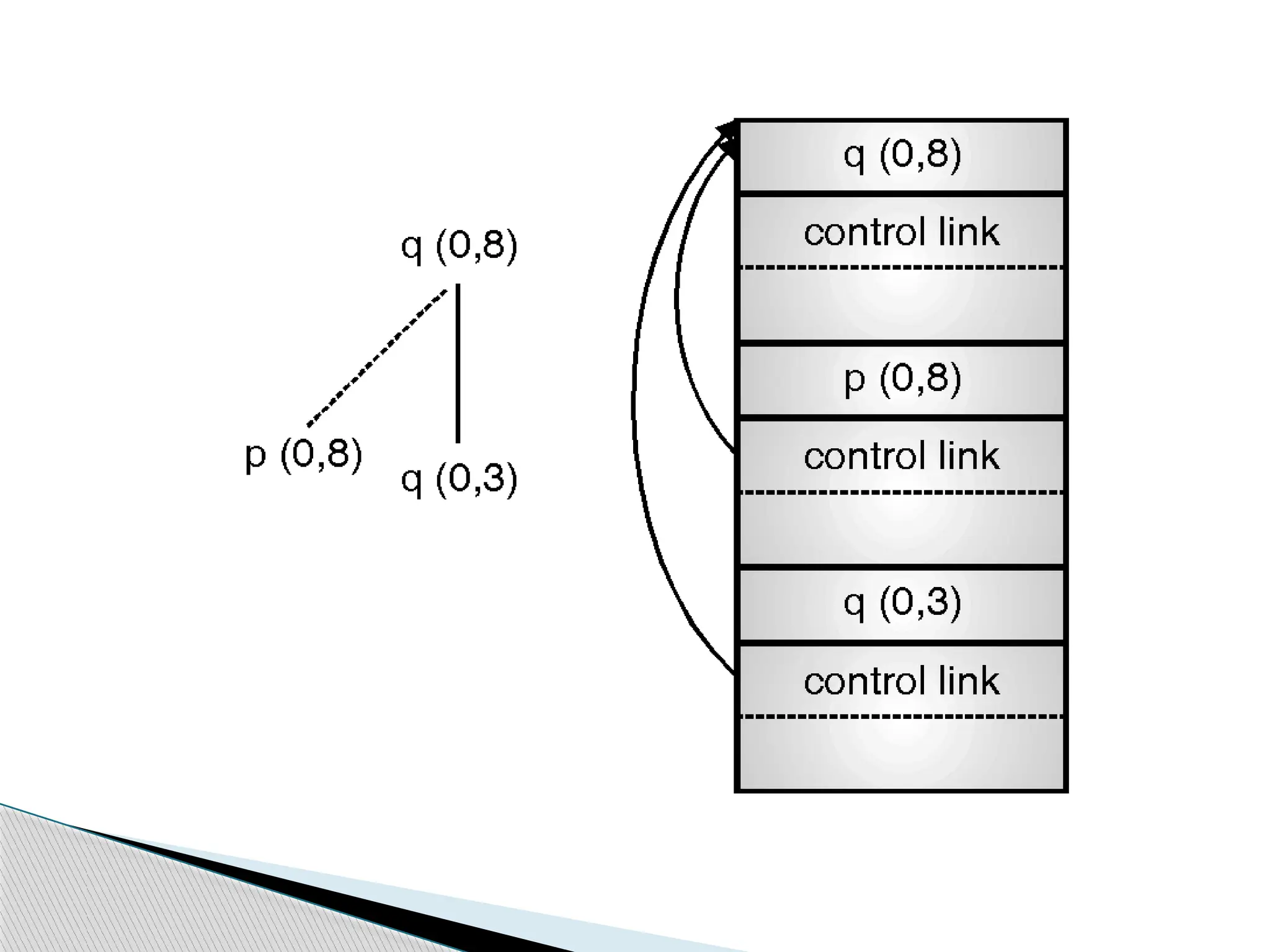
Example control stack
Thispartial
activation tree
corresponds to
control stack
(growing
downward)
s
q(1,9)
q(1,3)
q(2,3)
10.
The SCOPINGRULES of a language determine
where in a program a declaration applies.
The SCOPE of a declaration is the portion of the
program where the declaration applies.
An occurrence of a name in a procedure P is
LOCAL to P if it is in the scope of a declaration
made in P.
If the relevant declaration is not in P, we say the
reference is NON-LOCAL.
During compilation, we use the symbol table to
find the right declaration for a given occurrence
of a name.
The symbol table should return the entry if the
name is in scope, or otherwise return nothing.
The Scope of a Declaration
11.
Environments and states
The ENVIRONMENT is a function mapping
from names to storage locations.
The STATE is a function mapping storage
locations to the values held in those locations.
Environments map names to l-values.
States map l-values to r-values.
12.
Name binding
Whenan environment maps name x to storage
location s, we say “x is BOUND to s”. The
association is a BINDING.
Assignments change the state, but NOT the
environment:
pi := 3.14
changes the value held in the storage location for
pi, but does NOT change the location (the binding)
of pi.
Bindings do change, however, during execution, as
we move from activation to activation.
13.
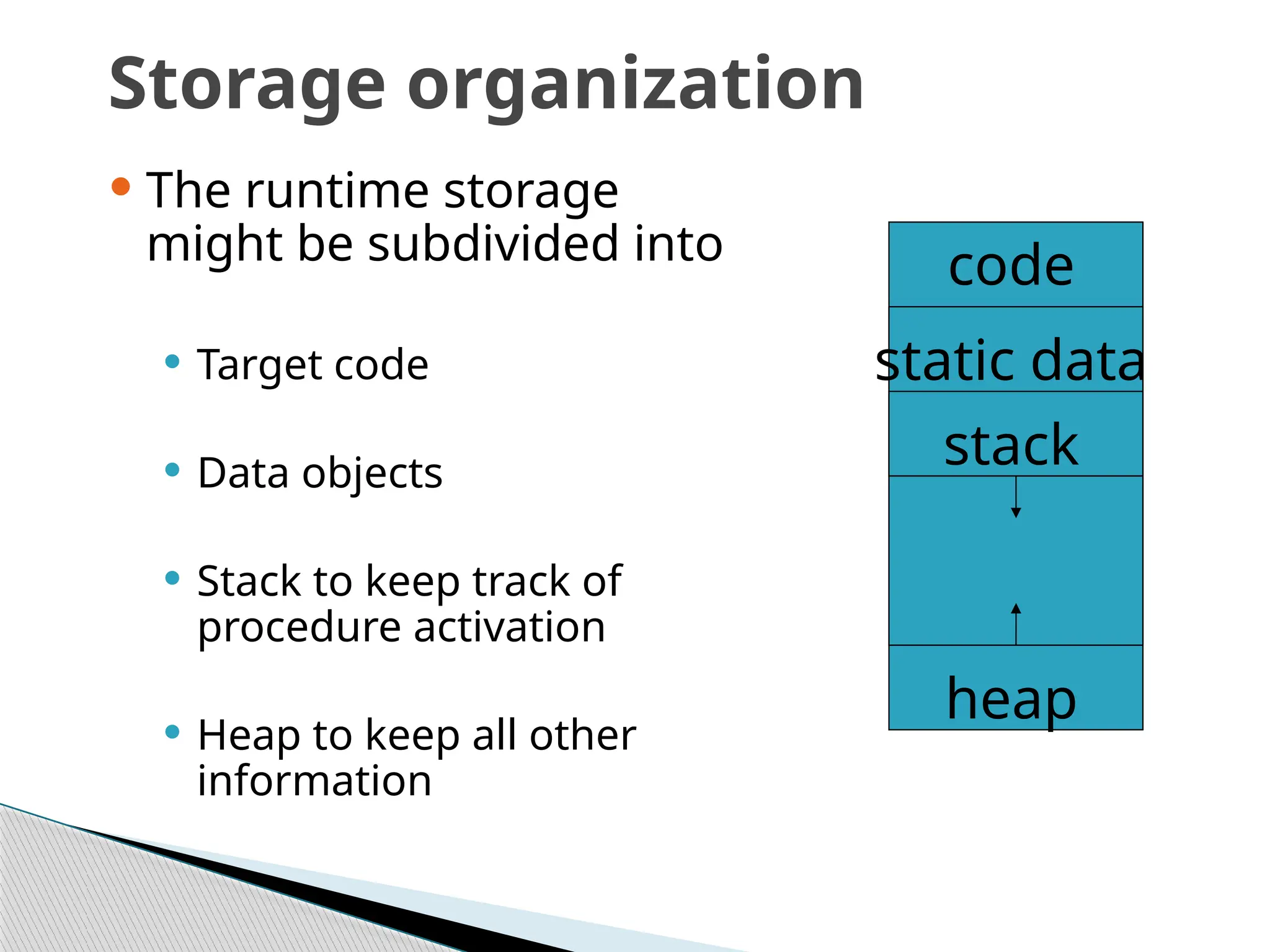
Storage organization
Theruntime storage
might be subdivided into
Target code
Data objects
Stack to keep track of
procedure activation
Heap to keep all other
information
code
static data
stack
heap
14.
This kindof organization of run-time storage is used
for languages such as Fortran, Pascal and C. The
size of the generated target code, as well as that of
some of the data objects, is known at compile time.
Thus, these can be stored in statically determined
areas in the memory.
Pascal and C use the stack for procedure activations.
Whenever a procedure is called, execution of an
activation gets interrupted, and information about
the machine state (like register values) is stored on
the stack. When the called procedure returns, the
interrupted activation can be restarted after
restoring the saved machine state.
Storage organization
15.
The heapmay be used to store dynamically
allocated data objects, and also other stuff
such as activation information (in the case of
languages where an activation tree cannot be
used to represent lifetimes).
Both the stack and the heap change in size
during program execution, so they cannot be
allocated a fixed amount of space. Generally
they start from opposite ends of the memory
and can grow as required, towards each
other, until the space available has filled up.
Storage organization
16.
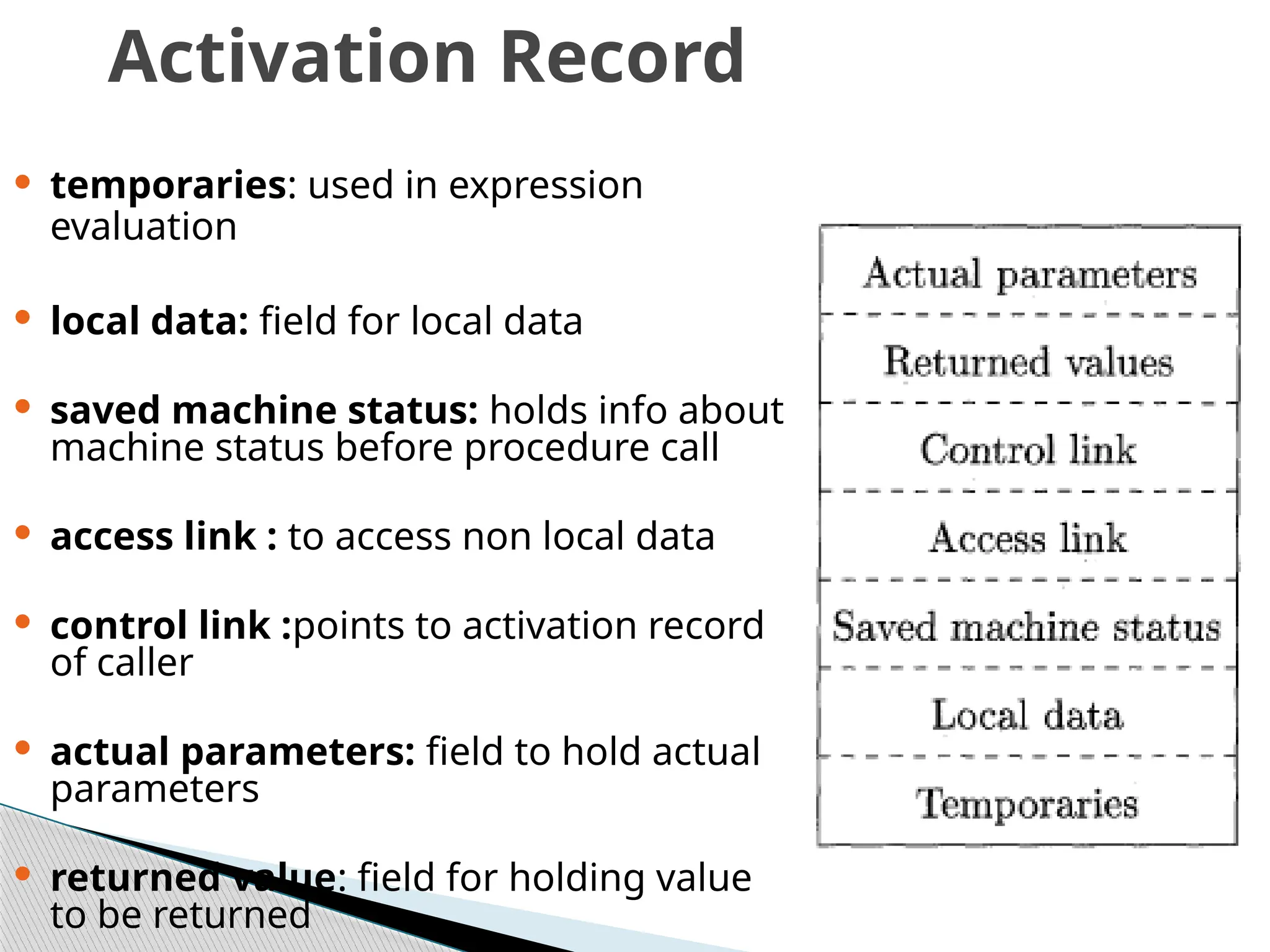
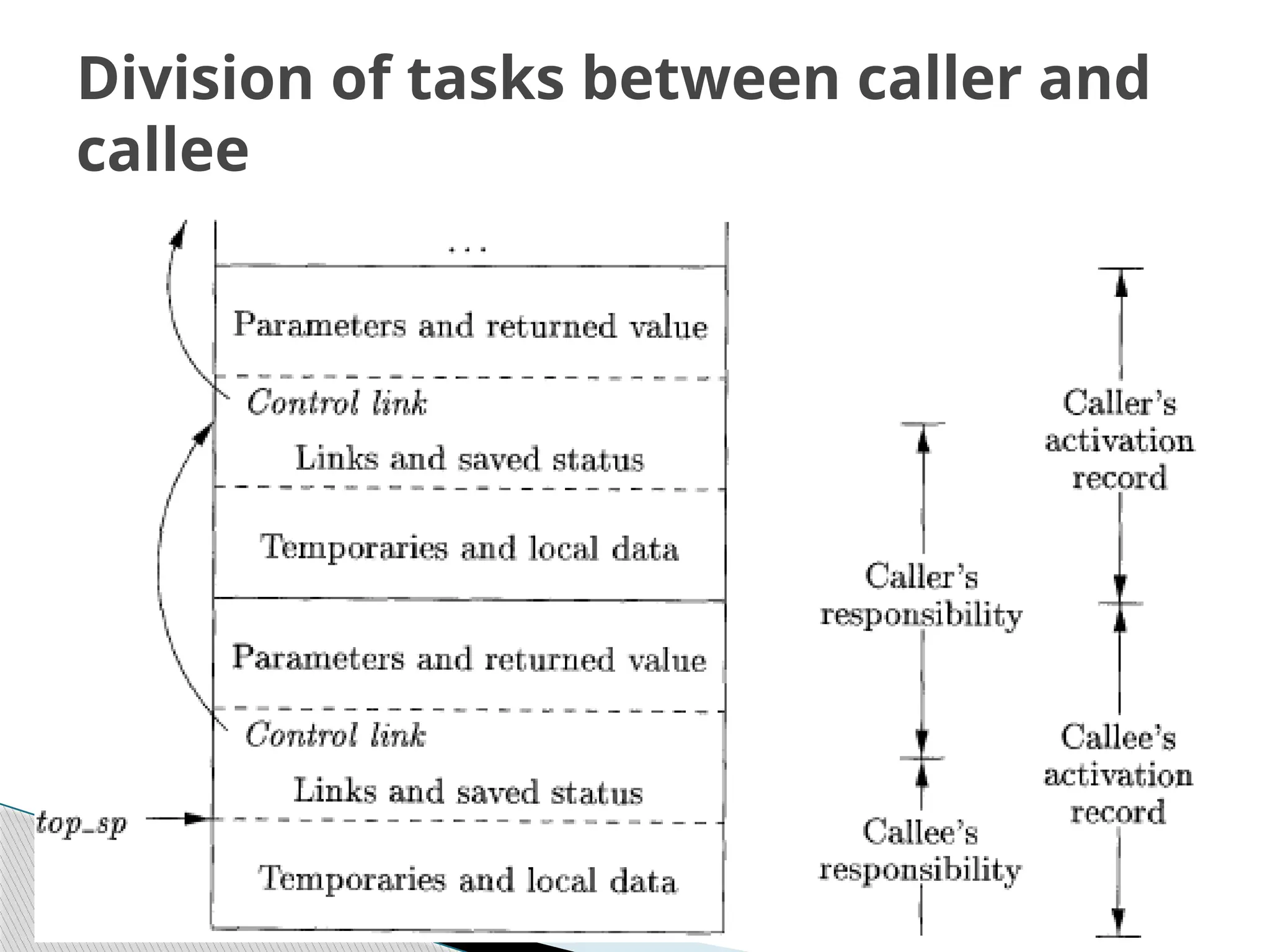
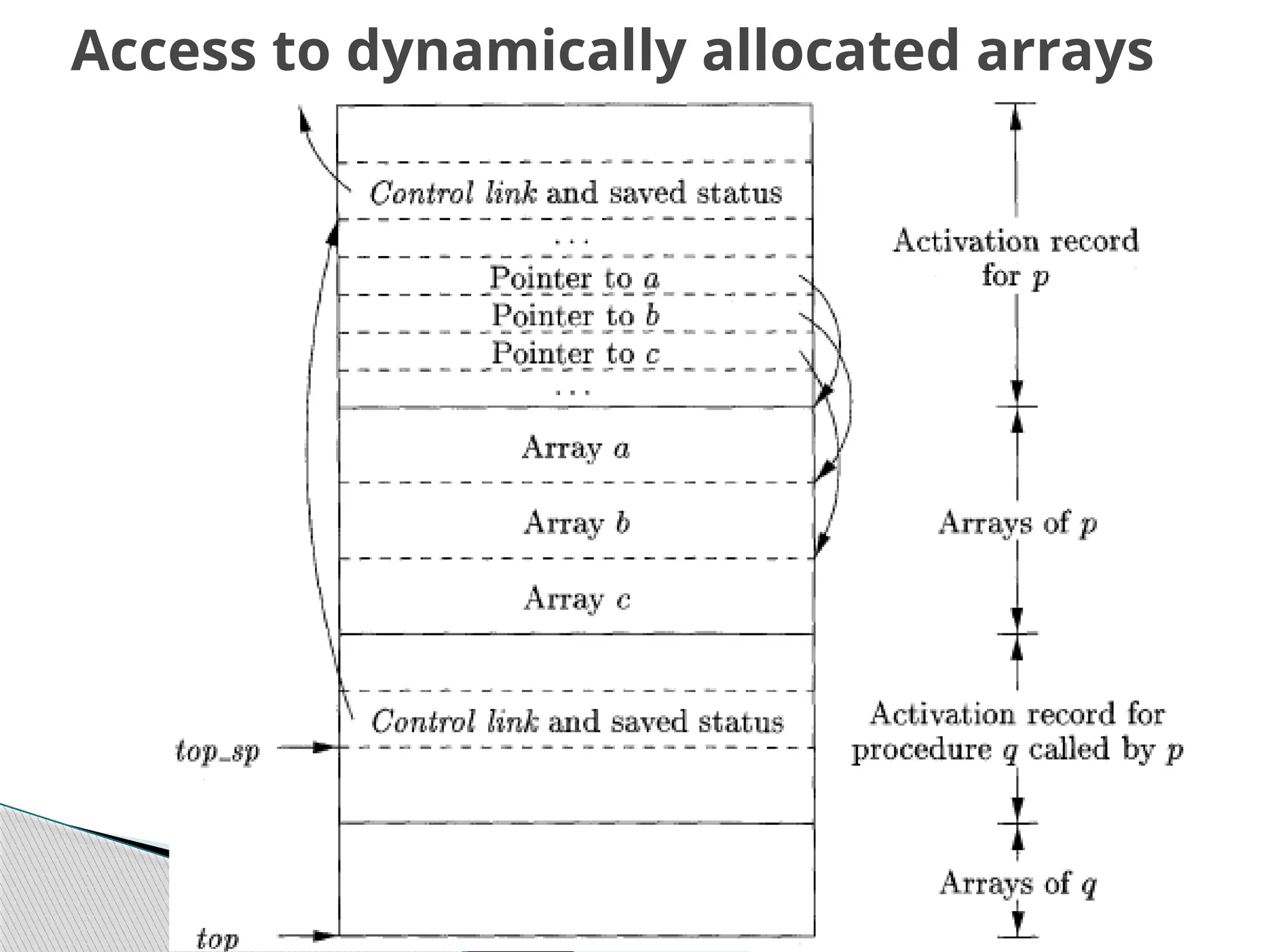
Activation Record
temporaries:used in expression
evaluation
local data: field for local data
saved machine status: holds info about
machine status before procedure call
access link : to access non local data
control link :points to activation record
of caller
actual parameters: field to hold actual
parameters
returned value: field for holding value
to be returned
17.
Not allthe fields shown in the figure may be
needed for all languages. The record structure can
be modified as per the language/compiler
requirements.
For Pascal and C, the activation record is generally
stored on the run-time stack during the period
when the procedure is executing.
Of the fields shown in the figure, access link and
control link are optional (e.g. Fortran doesn’t need
access links). Also, actual parameters and return
values are often stored in registers instead of the
activation record, for greater efficiency.
The activation record for a procedure call is
generated by the compiler.
Activation Record
18.
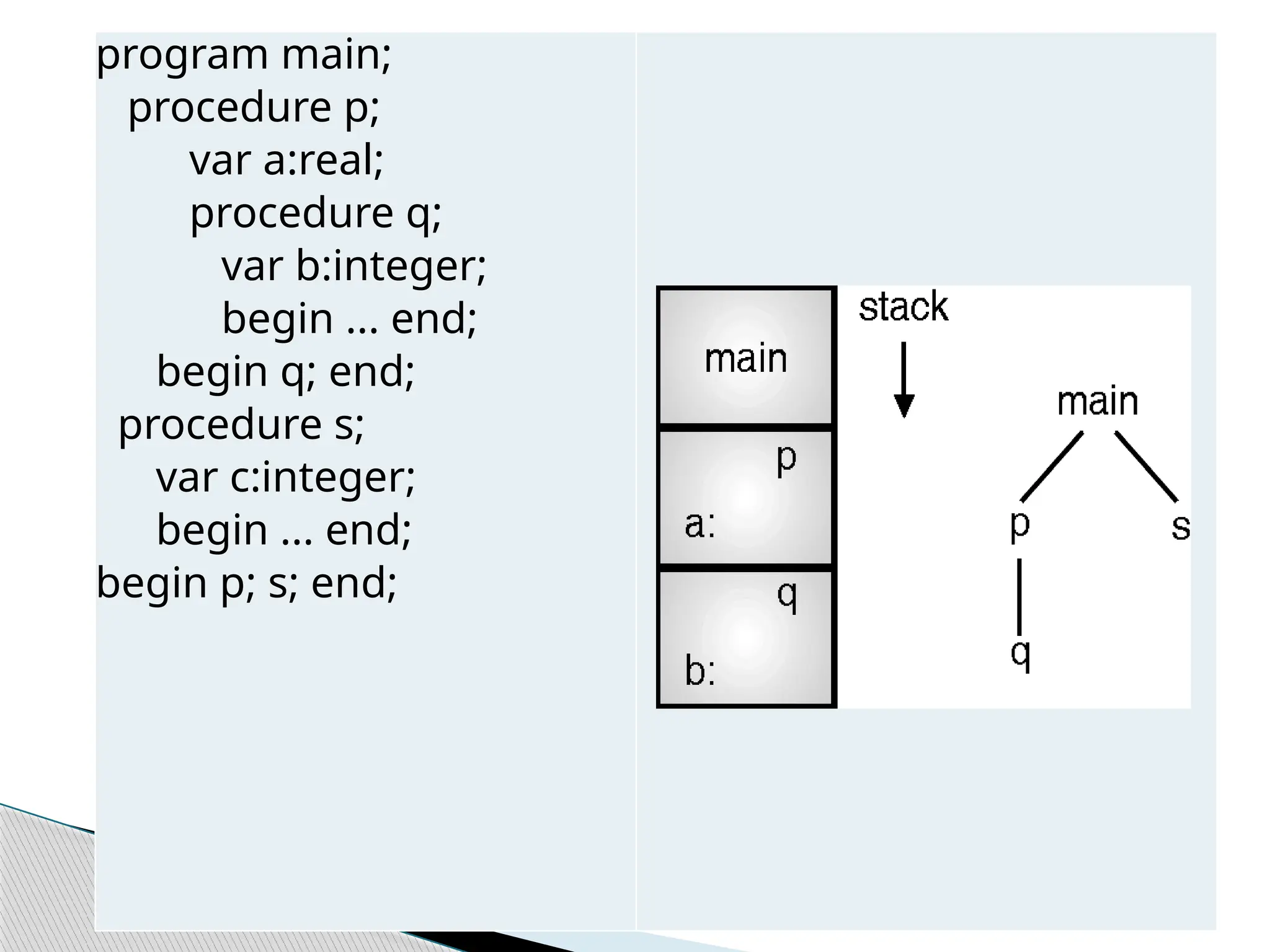
program main;
procedure p;
vara:real;
procedure q;
var b:integer;
begin ... end;
begin q; end;
procedure s;
var c:integer;
begin ... end;
begin p; s; end;
Storage Allocation Strategies
Static allocation: lays out storage at compile
time for all data objects
Stack allocation: manages the runtime storage
as a stack
Heap allocation :allocates and de-allocates
storage as needed at runtime from heap
21.
Static allocation
Namesare bound to storage as the
program is compiled
No runtime support is required
Bindings do not change at run time
On every invocation of procedure names
are bound to the same storage
Values of local names are retained across
activations of a procedure
22.
For example,suppose we had the following
code, written in a language using static
allocation:
function F( )
{
int a;
print(a);
a = 10;
}
After calling F( ) once, if it was called a second
time, the value of a would initially be 10, and
this is what would get printed.
Static allocation
23.
Type ofa name determines the amount of storage to be
set aside
Address of a storage consists of an offset from the end of
an activation record
Compiler decides location of each activation
All the addresses can be filled at compile time
Constraints
◦ Size of all data objects must be known at compile time
◦ Recursive procedures are not allowed
◦ Data structures cannot be created dynamically
24.
Stack-dynamic allocation
Storageis organized as a stack.
Activation records are pushed and popped.
Locals and parameters are contained in the
activation records for the call.
This means locals are bound to fresh storage
on every call.
We just need a stack_top pointer.
To allocate a new activation record, we just
increase stack_top.
To deallocate an existing activation record, we
just decrease stack_top.
25.
program sort;
var a: array[0..10] of integer;
procedure readarray;
var i :integer;
:
function partition (y, z
:integer) :integer;
var i, j ,x, v :integer;
procedure quicksort (m, n
:integer);
var i :integer;
:
i:= partition (m,n);
quicksort (m,i-1);
quicksort(i+1, n);
:
begin{main}
readarray;
quicksort(1,9)
end.
The callerevaluates the actual parameters
The caller stores a return address and the old
value of top-sp into the callee's activation
record.
The callee saves the register values and other
status information.
The callee initializes its local data and begins
execution.
calling sequence
29.
The calleeplaces the return value next to the
parameters
Using information in the machine-status field,
the callee restores top-sp and other registers,
and then branches to the return address that
the caller placed in the status field.
Although top-sp has been decremented, the
caller knows where the return value is, relative
to the current value of top-sp; the caller
therefore may use that value.
corresponding return sequence
30.
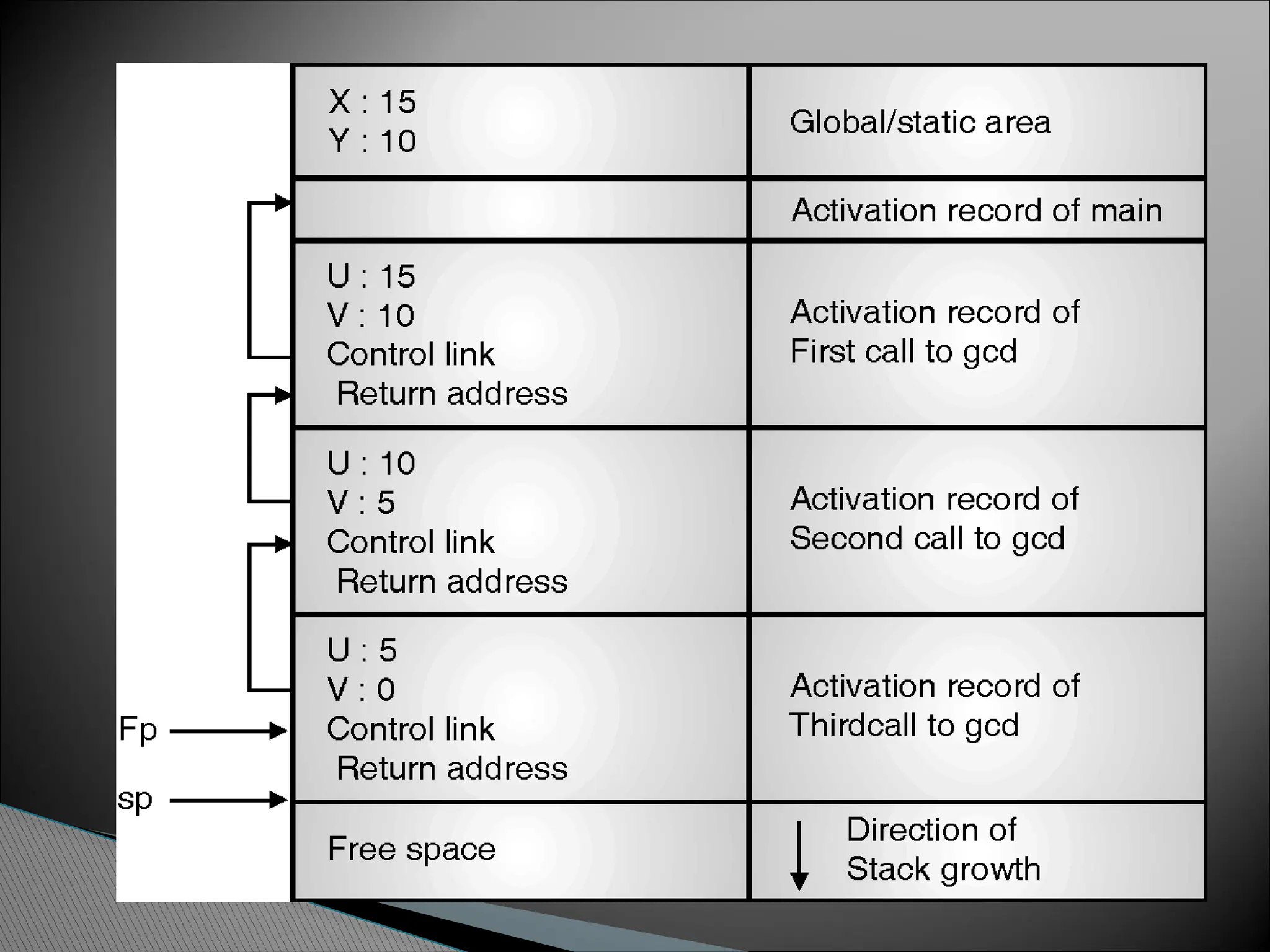
#include <stdio.h>
int x,y;
intgcd(int u,int v)
{
if (v == 0) return u;
else return gcd(v, u
%v);
}
main()
{
scanf(“%d%d”, &x,
&y);
printf(“%dn”,
gcd(x,y));
return 0;
}
Suppose the user inputs
the values 15 and 10 to
this program
End
0
5
0
5
10
5
10
15
u%v
v
u
32.
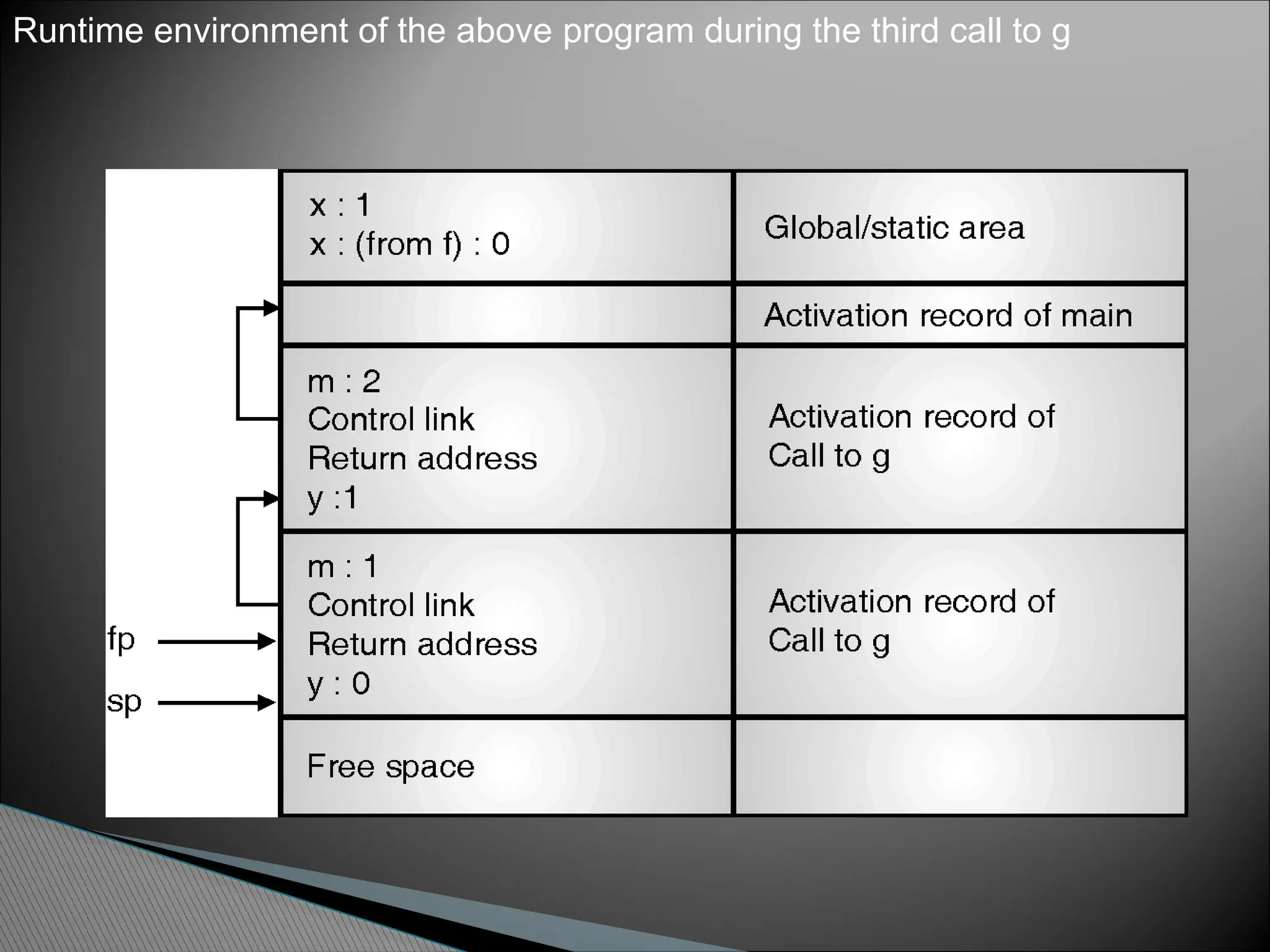
int x=2;
void g(int);/*prototype*/
voidf(int n)
{static int x=1;
g(n);
x--; }
void g(int m)
{int y=m-1;
if (y>0)
{ f(y);
x--;
g(y);
} }
main( )
{
g(x);
return 0; }
The problemof dangling references arises,
whenever storage is de-allocated.
A dangling reference occurs when there is a
reference to storage that has been de-allocated.
It is a logical error to use dangling references,
since the value of de-allocated storage is undefined
according to the semantics of most languages.
Since that storage may later be allocated to
another datum, mysterious bugs can appear in the
programs with dangling references.
Dangling references
37.
Dangling references
Referring tolocations which have been deallocated
main()
{int *p;
p = dangle(); /* dangling reference */
}
int *dangle();
{
int i=23;
return &i;
}
38.
Pieces maybe de-allocated in any order
Over time the heap will consist of alternate areas
that are free and in use
Heap manager is supposed to make use of the
free space
For efficiency reasons it may be helpful to handle
small activations as a special case
For each size of interest keep a linked list of free
blocks of that size
Heap Allocation …
39.
Fill arequest of size s with block of size s′
where s′ is the smallest size greater than or
equal to s
For large blocks of storage use heap
manager
For large amount of storage computation
may take some time to use up memory so
that time taken by the manager may be
negligible compared to the computation
time
Heap Allocation …
41.
Scope rulesdetermine the treatment of non-local
names
A common rule is lexical scoping or static scoping
(most languages use lexical scoping)
1. Static or Lexical scoping: It determines the
declaration that applies to a name by examining
the program text alone. E.g., Pascal, C and ADA.
2. Dynamic Scoping: It determines the declaration
applicable to a name at run time, by considering
the current activations. E.g., Lisp
Access to nonlocal names
42.
Block
A blockstatement contains its own data declarations
Blocks can be nested and their starting and ends are
marked by a delimiter.
They ensure that either block is independent of other
or nested in another block.
That is, it is not possible for two blocks B1 and B2 to
overlap in such a way that first block B1 begins, then
B2, but B1 end before B2.
The property is referred to as block structured
43.
Scope ofthe declaration is given by most
closely nested rule
◦ The scope of a declaration in block B
includes B
◦ If a name X is not declared in B
then an occurrence of X is in the scope of
declaration of X in B′ such that
B′ has a declaration of X
B′ is most closely nested around B
Block
44.
Example
main()
{ BEGINNING ofB0
int a=0
int b=0
{ BEGINNING of B1
int b=1
{ BEGINNING of B2
int a=2
print a, b
} END of B2
{ BEGINNING of B3
int b=3
print a, b
} END of B3
print a, b
} END of B1
print a, b
} END of B0
Scope B0, B1, B3
Scope B0
Scope B1, B2
Scope B2
Scope B3
45.
The scopeof the variables will be as follows:
Declaration Scope
int a=0 B0 not including B2
int b=0 B0 not including B1
int b=1 B1 not including B3
int a =2 B2 only
int b =3 B3 only
The outcome of the print statement will be,
therefore:
2 1
0 3
0 1
0 0
46.
Blocks …
Blocksare simpler to handle than
procedures
Blocks can be treated as parameter
less procedures
Use stack for memory allocation
Allocate space for complete
procedure body at one time
a0
b0
b1
a2,b
3
47.
Lexical scope withoutnested procedures
A procedure definition cannot occur within another
Therefore, all non local references are global and can be
allocated at compile time
Any name non-local to one procedure is non-local to all
procedures
In absence of nested procedures use stack allocation
Storage for non locals is allocated statically
A non local name must be local to the top of the stack
Stack allocation of non local has advantage:
Non locals have static allocations
Procedures can be passed/returned as parameters
48.
1) Program pass(input,ouput);
2)var m : integer;
3) function f(n:integer):integer;
4) begin f = m+ n end {f};
5) function g(n:integer):integer;
6) begin g = m* n end {g};
7) procedure b(function h(n:integer):integer);
8) begin write(h(2)) end {b};
9) begin
10) m=0;
11) b(f); b(g); writeln
12) end
Pascal program with nonlocal
occurrence of m
49.
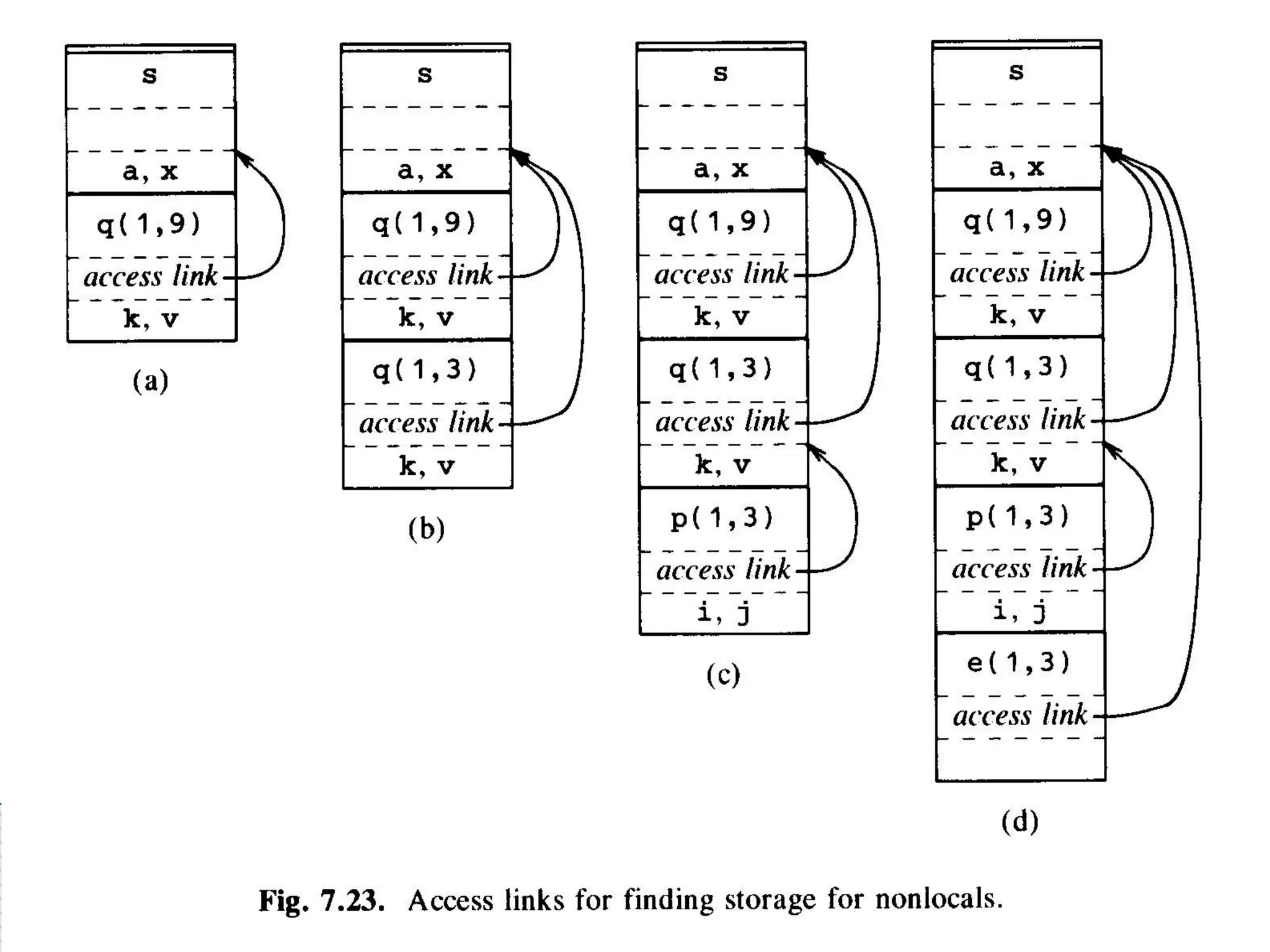
Nesting Depth
Mainprocedure is at depth 1
Add 1 to depth as we go from enclosing to
enclosed procedure
Access to non-local names
• Include a field ‘access link’ in the activation
record
• If p is nested in q then access link of p points
to the access link in most recent activation of
q
Lexical scope with nested
procedures
53.
The nesting ofprocedure definitions in the Pascal
program is indicated by the following indentation.
sort
readarray
exchange
quicksort
partition
55.
Access to nonlocal names …
Suppose procedure p at depth np refers to
a non-local a at depth na, then storage for
a can be found as
follow (np-na) access links from the record at the
top of the stack
after following (np-na) links we reach procedure
for which a is local
Therefore, address of a non local a in
procedure p can be stored in symbol table
as
(np-na, offset of a in record of activation
having a )
56.
How to setupaccess links?
suppose procedure p at depth np calls procedure x
at depth nx.
The code for setting up access links depends upon
whether the called procedure is nested within the
caller.
np < nx
Called procedure is nested more deeply than p.
Therefore, x must be declared in p. The access
link in the called procedure must point to the
access link of the activation just below it
np nx
≥
From scoping rules enclosing procedure at the
depth 1,2,… ,nx-1 must be same. Follow np-(nx-
1) links from the caller, we reach the most recent
activation of the procedure that encloses both
called and calling procedure
57.
An alternativeto access link ( a faster method to
access nonlocals ).
Using an array d of pointers to activation
records, the array is called a display.
Referencing nonlocal variables always requires
only two memory references.
Suppose control is in a procedure p at nesting
depth j, then the first j-1 elements of the display
point to the most recent activation of the
procedures that lexically enclose procedure p,
and d[j] points to the activation of p.
Displays
59.
Justification for Displays
Suppose procedure at depth j calls procedure at
depth i
Case j < i then i = j + 1
called procedure is nested within the caller
first j elements of display need not be changed
set d[i] to the new activation record
Case j i
≥
enclosing procedure at depthes 1…i-1 are same and are
left un-disturbed
old value of d[i] is saved and d[i] points to the new record
display is correct as first i-1 records are not disturbed
60.
Binding ofnon local names to storage do
not change when new activation is set up
A non local name a in the called activation
refers to same storage that it did in the
calling activation
Dynamic Scope
61.
Consider thefollowing program
program dynamic (input, output);
var r: real;
procedure show;
begin write(r) end;
procedure small;
var r: real;
begin r := 0.125; show end;
begin
r := 0.25;
show; small; writeln;
show; small; writeln;
end.
Dynamic Scoping: Example
62.
Output underlexical scoping
0.2500.250
0.2500.250
Output under dynamic scoping
0.2500.125
0.2500.125
Example …
63.
Deep Access
◦Dispense with access links
◦ use control links to search into the stack
◦ term deep access comes from the fact that
search may go deep into the stack
Shallow Access
◦ hold current value of each name in static
memory
◦ when a new activation of p occurs a local name
n in p takes over the storage for n
◦ previous value of n is saved in the activation
record of p
Implementing Dynamic Scope
64.
Call byvalue
◦ actual parameters are evaluated and their
rvalues are passed to the called procedure
◦ used in Pascal and C
◦ formal is treated just like a local name
◦ caller evaluates the actual parameters and
places rvalue in the storage for formals
◦ call has no effect on the activation record of
caller
Parameter Passing
65.
(1) program reference(input,output);
(2)var a, b: integer;
(3) procedure swap(var x, y: integer);
(4) var temp : integer;
(5) begin
(6) temp := x;
(7) x := y
(8) y := temp
(9) end;
(10) begin
(11) a := 1; b := 2;
(12) swap(a,b);
(13) writeln(‘a =’, a); writeln(‘b =’, b)
(14) end.
Pascal program with procedure swap.
66.
(1) swap(x.y)
(2) int*x, *y;
(3) { int temp;
(4) temp = *x; *x = *y; *y = temp;
(5) }
(6) main( )
(7) { int a = 1, b = 2;
(8) swapt (&a, &b );
(9) printf("a is now %d, b is now %dn",a,b);
(10) }
C program using pointers in a procedure called by value.
The output of this pro
gram is
a is now 2, b is now 1
67.
Call byreference (call by address)
◦ the caller passes a pointer to each location of
actual parameters
◦ if actual parameter is a name then lvalue is passed
◦ if actual parameter is an expression then it is
evaluated in a new location and the address of
that location is passed
Parameter Passing …
68.
void p(int x,int y)
{ ++x;
++y;
}
main( )
{ int a=1;
p(a, a);
return 0;
}
If pass by reference is used, a has value 3 after p is
called
69.
Copy restore(copy-in copy-out, call by value
result)
◦ actual parameters are evaluated, rvalues are
passed by call by value, lvalues are determined
before the call
◦ when control returns, the current rvalues of the
formals are copied into lvalues of the locals
Parameter Passing …
70.
void p(int x,int y)
{ ++x;
++y;
}
main( )
{ int a=1;
p(a, a);
return 0;
}
a has value 2 after p is called
71.
Call byname (used in Algol)
◦ names are copied
◦ local names are different from names of calling
procedure
swap(i,a[i])
temp = i
i = a[i]
a[i] = temp
Parameter Passing …
Symbol tableis an essential data structure used by the
compilers to remember information about identifiers
appearing in the source language program.
A symbol table contains nearly all the information needed
by different phases of compilers. Usually the phases—
lexical analyzer and parser fill up the entries in the table,
while the later phases like code generator and optimizer
make use of the information available in the table.
Thus, it acts as a common interface between the phases
of a compiler. The types of symbols that are stored in the
symbol table include variables, procedures, functions,
defined constants, labels, structures, file identifications
and computer generated temporaries.
Symbol Table
74.
name—the nameof the identifier. The name may be stored directly
in the table or the table entry may point to another character
string, possibly stored in an associated string table. The second
indirect approach is particularly suitable, if the names can be
arbitrarily long and widely varying in length.
type—the type of the identifier. It defines, whether or not the
identifier is a variable, a label, a procedure name, etc. For variables,
it will further identify the type—the basic types like integer, real,
character, or derived types like arrays, records, pointers and so on.
location—This is generally an offset within the program where the
identifier is defined.
scope—The scope identifies the region of the program in which the
current definition of the symbol is valid.
other attributes—Some other information may be stored
depending upon the type of the identifier—like array limits, fields of
records, parameters and return values for functions etc.
Information in Symbol table
75.
Semantic analysis: Tocheck the correct semantic
usage of the language constructs.
Code generation: All program variables and
temporaries need to be allocated some memory
locations. A symbol table provides information
regarding the size of the memory required for the
identifiers through their types.
Error detection: It is a very common error to leave
variables undefined in the program. If a particular
variable is undefined, every reference to it will result
in an error message, informing that it is undefined
Usage of Symbol Table Information
76.
Optimization: Toreduce the total number of
variables used in a program, we need to reuse
the temporaries generated by the compiler. We
can merge two or more temporaries into one,
only if their types are same (to keep the
memory allocated same in both cases). Thus,
the information stored in the symbol table
regarding types of temporaries may be utilized
by the optimizer to reuse the same memory.
Usage of Symbol Table Information
77.
1. Lookup:This operation is used to check whether
identifier is defined or not. If it is defined, then the relevant
information may be retrieved. On the other hand, if it is
undefined, then need to create an entry into the symbol
table.
2. Insert: This is used for adding new names in symbol
table. This is mostly used in the lexical and syntax analysis.
3. Modify: Sometimes, when a name is defined all the
information about it is not available. Later on, when the
information becomes available, appropriate entries of the
table may be updated.
4. Delete : Though not very frequent, sometimes we
need to delete entries from the symbol table. For example,
while a procedure body ends, the variables defined inside
may not be available any more to the later part of the
program. Thus, all such variables may be deleted from the
symbol table.
Operations performed on
symbol table
78.
Format ofsymbol table entries : The symbol table may have various
formats from linear array to list to tree structure and so on. We will
deal with various structures in next section. Often the structures
depict the procedures for accessing the tables.
2. Access methodology :The following access methods are used
depending on the structure of the table.
1. Linear search
2. Binary search
3. Tree search
4. Hashing
3. Location of storage : The symbol table may be located in the
primary memory, thus making access fast. However, a large symbol
table may necessitate to store it, at least partially in the secondary
storage.
4. Scope issues : Scope rules of a language also put some
constraint in the symbol table structure. For example, in a block-
structured language, it may be necessary that a variable defined in
upper blocks must also be visible to its nested subblocks
Issues in the design of symbol
table
79.
Based onthe scope rules, the symbol tables
can be classified into two different classes:
◦ Simple symbol table with no nested scope and
◦ Scoped symbol table with nested scopes
80.
The fundamentaloperations on such a table are the
following:
1. Enter a new symbol into the table.
2. Lookup for a symbol and
3. Modify information about a symbol stored
earlier in the table.
There are several alternative data structures to
choose from to create such a simple symbol table.
However, the commonly used techniques are given
below.
◦ linear table.
◦ ordered list.
◦ tree and
◦ hash table.
Simple Symbol Table
81.
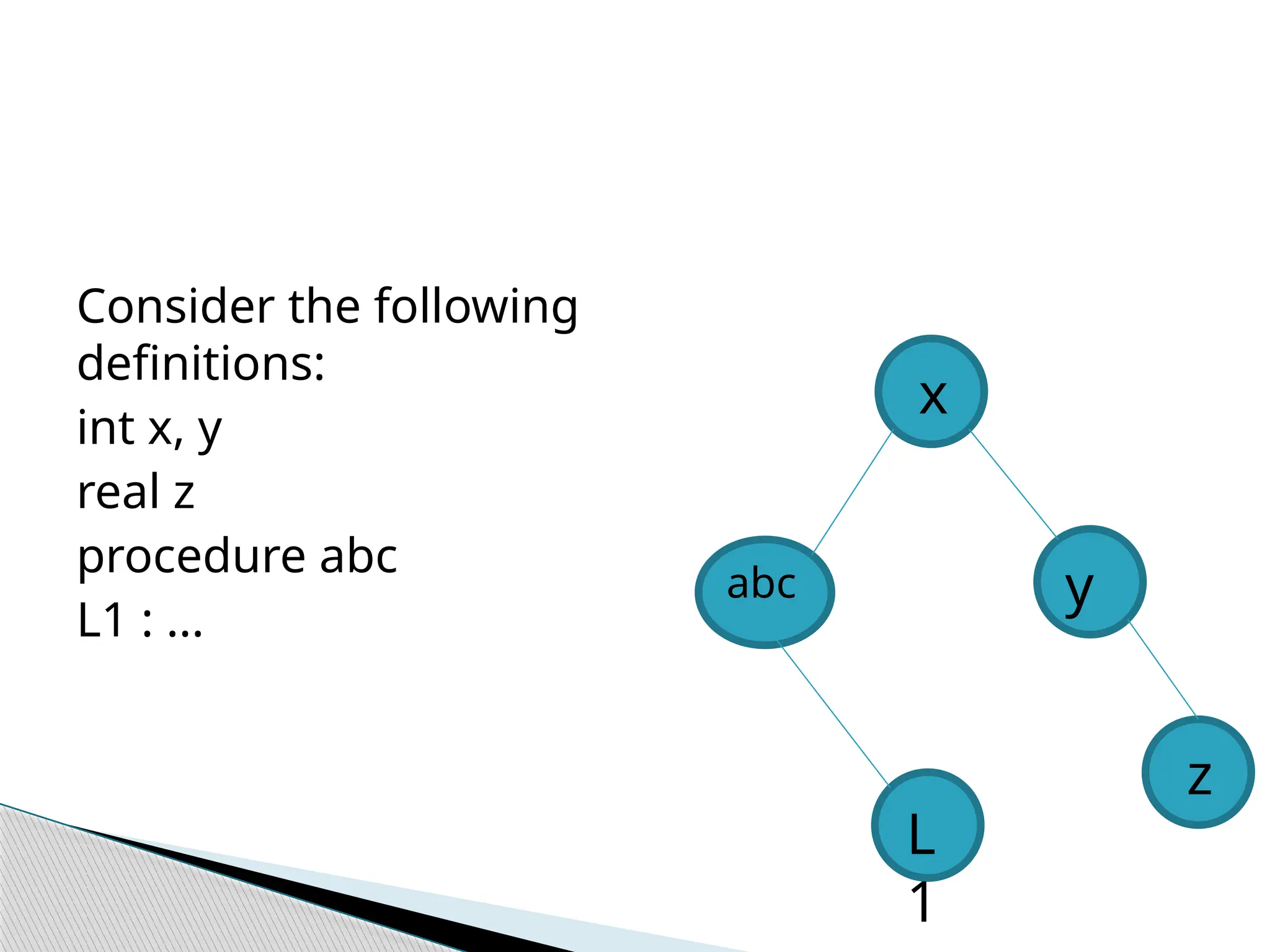
Consider the
followingdefinitions:
int w,x, y
real z
procedure disp
L1 : ...
Linear table nam
e
type Location
w integer offset of w
x integer offset of x
y integer offset of y
z real offset of z
disp Procedu
re
offset of
disp
L1 label offset of
L1
• The lookup, insert and modify operations are going to
take O(n) time, n being the number of identifiers
stored.
• Insertion can be made O(l) by remembering the
82.
This isa variation of linear tables, in which a list
organization is used.
The list may be sorted in some fashion and
then, binary search can be used to access the
table in O(logn) time.
However, an insertion needs to be done at an
appropriate place, to preserve the sorted form.
Thus, the insertion becomes costly.
Ordered List
83.
Tree organizationof symbol table may be used to
speed up the access.
Each entry is represented by a node of the tree.
Based on string comparison of names, the entries
lesser than a reference node are kept in its left-
subtree, whereas the entries greater than the
reference node are put into the right subtree.
The individual nodes also hold two more pointer
fields to the left and right subtrees apart from
having the regular information related to the
symbol.
Trees
84.
Moreover, eachlookup operation, apart from the
equality check, needs to be followed by a
less-than/greater-than check for each node of the tree
where a match is not found and the search must
proceed further.
The average lookup time for an entry in the tree is
O(logn).
However, it could degrade to a single long branching,
thus requiring O(n) search time.
Proper height balancing strategies may be used for
example AVL trees, to keep the tree balanced
Trees
The mappingis done using a hash function. The table, as
such is organized as an array.
To store a symbol into the table, the hash function is
applied on it, which results into a unique location of the
table. The symbol along with its associated information is
stored in this location.
To access the symbol again its name is hashed to a
location of the table. Thus, the access time is 0(1).
However, the problem arises due to imperfectness of hash
functions that maps a number of symbols to the same
location. To resolve the conflict, some collision resolution
strategy needs to be followed.
The commonly used strategies for collision resolution are
open addressing and chaining. With both the strategies,
the worst case access time is 0(n), n being the total
number of records in the table. To reduce the number of
collisions, keeping the size of the table reasonable.
Hash Table
87.
The scope ofa symbol table defines the region of
the program, in which a particular definition of
the symbol is valid. This definition is said to be
visible within the scope region.
Scoped Symbol Table
88.
1.Global scope:An identifier with a global scope has
visibility throughout the program. The global variable
declarations of a program generally, come with this scope.
2. File-wide scope: For a program with modules
distributed in more than one file, an identifier defined to
have file-wide scope is visible only within the file. In other
words, it is global within the file.
3. Local scope within a procedure: For programs
having multiple procedures, an identifier defined within a
procedure may be visible only to the points inside the
procedure. This is commonly referred to as local variables
of functions or procedures.
4. Local scope within a block: A program block is a
code chunk having single entry and single exit. Thus a
procedure may be further divided into a number of blocks
and the identifier defined inside a block will be visible only
within that block.
89.
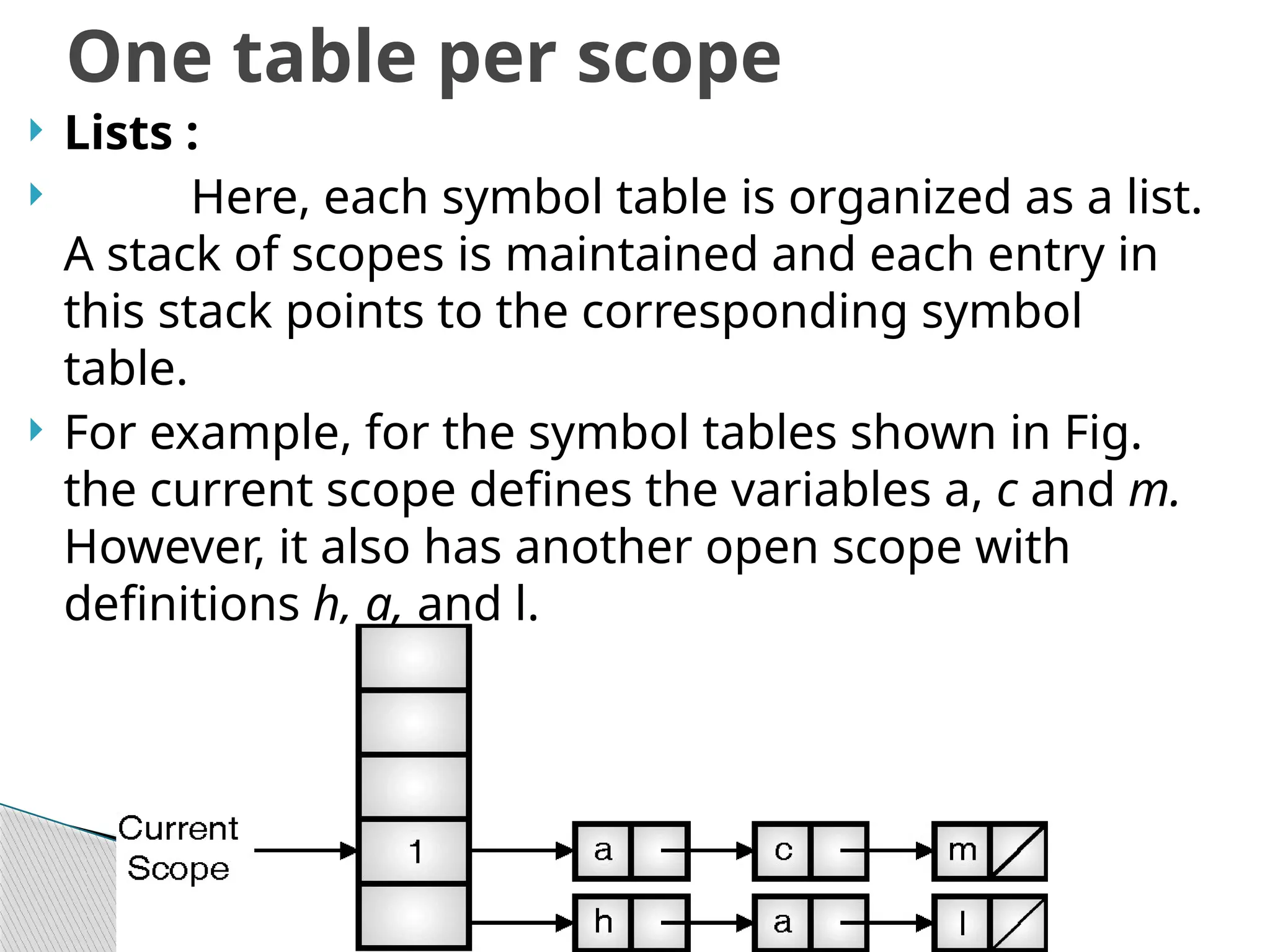
Lists :
Here, each symbol table is organized as a list.
A stack of scopes is maintained and each entry in
this stack points to the corresponding symbol
table.
For example, for the symbol tables shown in Fig.
the current scope defines the variables a, c and m.
However, it also has another open scope with
definitions h, a, and l.
One table per scope
90.
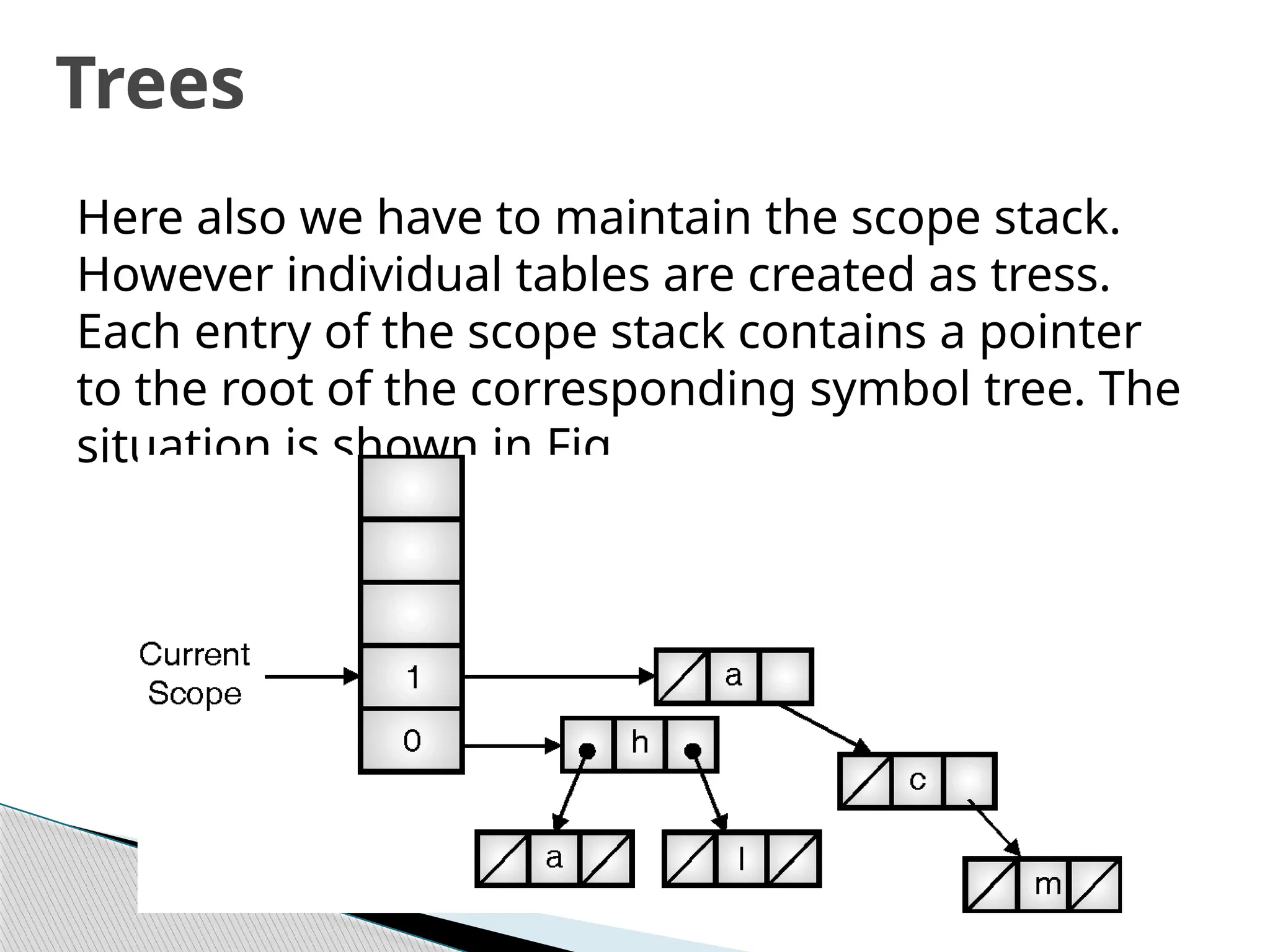
Here also wehave to maintain the scope stack.
However individual tables are created as tress.
Each entry of the scope stack contains a pointer
to the root of the corresponding symbol tree. The
situation is shown in Fig
Trees
91.
Hash Tables:
Similar to the single scope case, a hash
table is built for each scope. Each entry in the
scope stack points to the hash table
corresponding to the scope.
Hash Tables :
92.
In thiscase there exists a single table into which all variables
will be stored. In order to remember the scope of the
variables, each entry in the symbol table has an extra field
identifying the scope of the symbol.
Single table is more efficient in the sense that it does not
waste space as compared to the case of one table per scope.
However, some space saved in the process is eaten up by the
scope number field.
As we go into more and more nesting, the scope number
increases. Thus, in order to search for a variable, we have to
start with the highest scope number and then, try out the
entries having the next lesser scope number and so on.
As when a scope gets closed all the variables with that scope
number are removed from the table.
One Table for All Scopes
93.
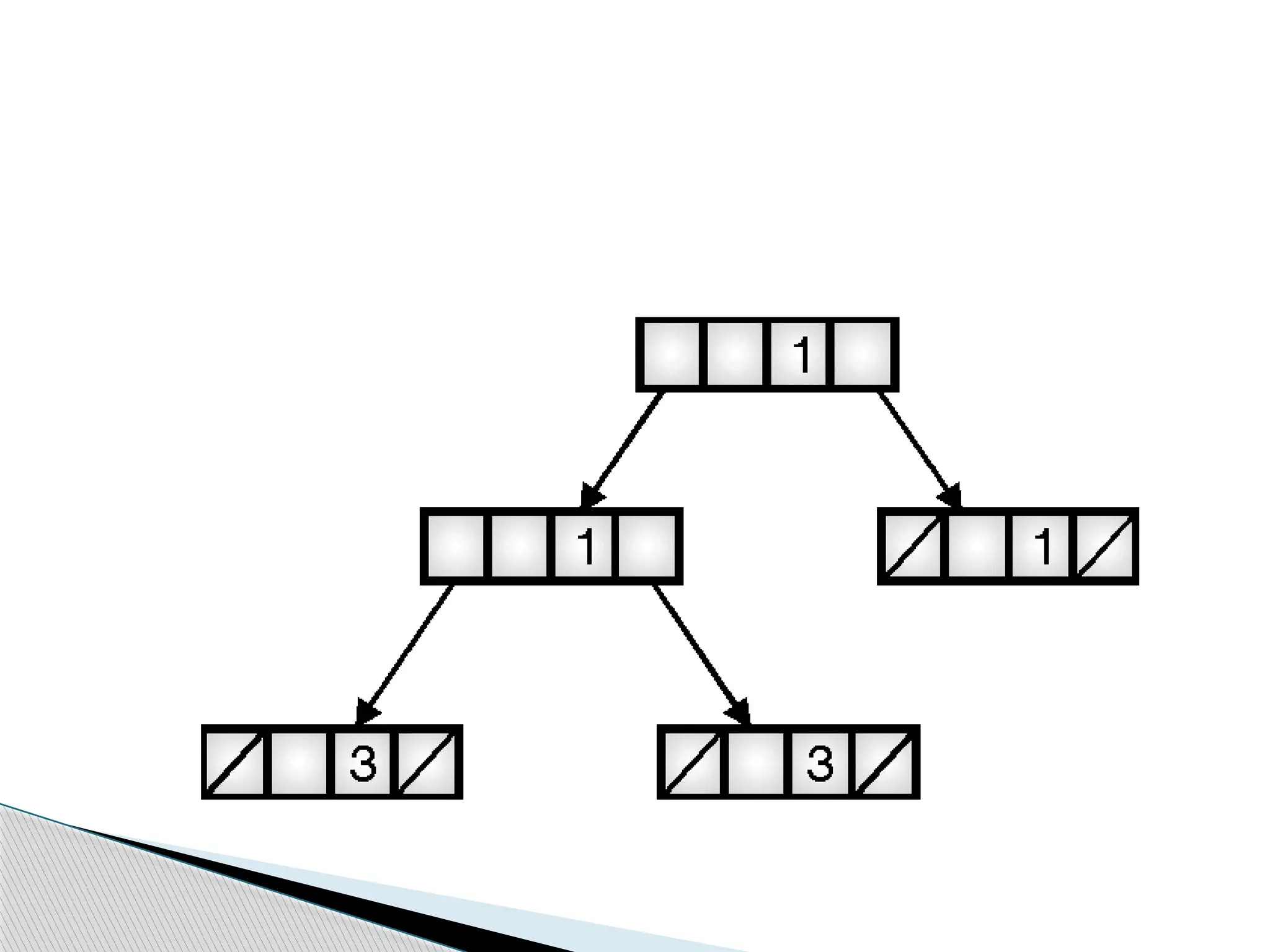
It issimilar to the one-table-per-scope case,
except the fact that all the tables are now
concatenated into a single list. The scope
number is maintained and when a scope gets
closed that portion of the list is deleted. A
typical such list has been shown in Fig.7.30.
It corresponds to the case with three nested
scopes 3 being the innermost, 2 next and 1 the
outermost. To search for X, the first entry
matches Y matches with the definition in scope
2 and so on.
Lists
94.
It buildsa single tree along with the scope
information stored at each node.
For example Fig shows a tree structured table for
the nested blocks with H, A, and L appearing at
scope 1 and A and C appearing at scope 3.
The major difficulty encountered here is that the
insertion of a new symbol always occurs at the leaf
level.
Thus to search for the definition of a variable, we
have to search for matching entry all the way to the
leaves till the last matching entry found.
Deletion of entries also needs traversing the whole
tree to remove symbols from the current scope.
Trees
96.
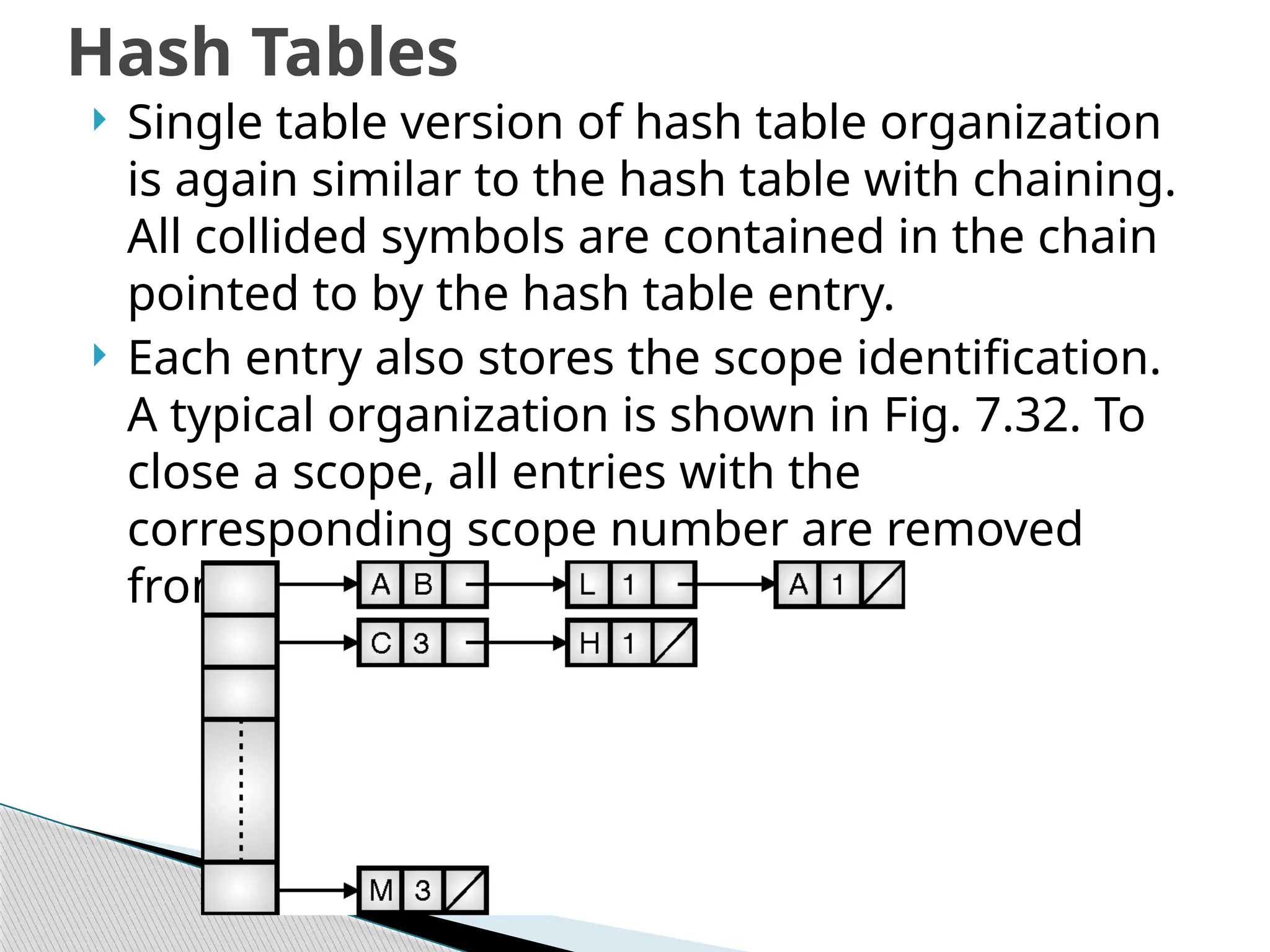
Single tableversion of hash table organization
is again similar to the hash table with chaining.
All collided symbols are contained in the chain
pointed to by the hash table entry.
Each entry also stores the scope identification.
A typical organization is shown in Fig. 7.32. To
close a scope, all entries with the
corresponding scope number are removed
from the chain.
Hash Tables
97.
begin
integer n;
procedure
Begin
n :=n+1;
k := k+4;
print(n);
end;
n := 0;
p(n);
print(n);
end;
Output:
call by value: 1 1
call by value-result: 1 4
call by reference: 5 5
#38 Initializing data-structures may require allocating memory but where to allocate this memory. After doing type inference we have to do storage allocation. It will allocate some chunk of bytes. But in language like lisp it will try to give continuous chunk. The allocation in continuous bytes may lead to problem of fragmentation i.e. you may develop hole in process of allocation and de-allocation.
Thus storage allocation of heap may lead us with many holes and fragmented memory which will make it hard to allocate continuous chunk of memory to requesting program. So we have heap mangers which manage the free space and allocation and de-allocation of memory. It would be efficient to handle small activations and activations of predictable size as a special case as described in the next slide. The various allocation and de-allocation techniques used will be discussed later.
#39 As mentioned earlier, for efficiency reasons we can handle small activations and activations of predictable size as a special case as follows:
For each size of interest, keep a linked list if free blocks of that size
If possible, fill a request for size s with a block of size s’, where s’ is the smallest size greater than or equal to s. When the block is eventually de-allocated, it is returned to the linked list it came from.
For large blocks of storage use the heap manger.
Heap manger will dynamically allocate memory. This will come with a runtime overhead. As heap manager will have to take care of defragmentation and garbage collection. But since heap manger saves space otherwise we will have to fix size of activation at compile time, runtime overhead is the price worth it.
#57 Consider the following program to illustrate the fact that an access link must be passed with the actual parameter f. The details are explained in the next slide.
#58 Lexical scope rules apply even when a nested procedure is passed as a parameter. In the program shown in the previous slide, the scope of declaration of m does not include the body of b. Within the body of b, the call h(2) activates f because the formal h refers to f. Now how to set up the access link for the activation of f? The answer is that a nested procedure that is passed as a parameter must take its access link along with it, as shown in the next slide. When procedure c passes f, it determines an access link for f, just as it would if it were calling f. This link is passed along with f to b. Subsequently, when f is activated from within b, the link is used to set up the access link in the activation record for f.
#59 Actual procedure parameter f carries its access link along as described earlier.
#63 In dynamic scope, a new activation inherits the existing bindings of non local names to storage. A non local name a in the called activation refers to the same storage that it did in the calling activation. New bindings are set up for the local names of the called procedure, the names refer to storage in the new activation record.
#64 Consider the example shown to illustrate that the output depends on whether lexical or dynamic scope is used.
#65 The outputs under the lexical and the dynamic scoping are as shown. Under dynamic scoping, when show is called in the main program, 0.250 is written because the variable r local to the main program is used. However, when show is called from within small, 0.125 is written because the variable r local to small is used.
#66 We will discuss two approaches to implement dynamic scope. They bear resemblance to the use of access links and displays, respectively, in the implementation of the lexical scope.
1. Deep Access: Dynamic scope results if access links point to the same activation records that control links do. A simple implementation is to dispense with access links and use control links to search into the stack, looking for the first activation record containing storage for the non-local name. The term deep access comes from the fact that search may go deep into the stack. The depth to which the search may go depends on the input of the program and cannot be determined at compile time.
2. Shallow Access: Here the idea is to hold the current value of each name in static memory. When a new activation of a procedure p occurs, a local name n in p takes over the storage for n. The previous value of n is saved in the activation record for p and is restored when the activation of p ends.
#67 This is, in a sense, the simplest possible method of passing parameters. The actual parameters are evaluated and their r-values are passed to the called procedure. Call-by-value is used in C, and Pascal parameters are usually passed this way. Call-by-Value can be implemented as follows:
A formal parameter is treated just like a local name, so the storage for the formals is in the activation record of the called procedure.
The caller evaluates the actual parameters and places their r-values in the storage for the formals.
A distinguishing feature of call-by-value is that operations on the formal parameters do not affect values in the activation record of the caller.
#70 When the parameters are passed by reference (also known as call-by-address or call-by location), the caller passes to the called procedure a pointer to the storage address of each actual parameter.
If an actual parameter is a name or an expression having an l-value, then that l-value itself is passed.
However, if the actual parameter is an expression, like a + b or 2, that has no l-value, then the expression is evaluated in a new location, and the address of that location is passed.
A reference to a formal parameter in the called procedure becomes, in the target code, an indirect reference through the pointer passed to the called procedure.
#72 This is a hybrid form between call-by-value and call-by-reference (also known as copy-in copy-out or value-result).
Before control flows to the called procedure, the actual parameters are evaluated. The r-values of the actuals are passed to the called procedure as in call-by-value. In addition, however, the l-values of those actual parameters having l-values are determined before the call.
When the control returns, the current r-values of the formal parameters are copied back into the l-values of the actuals, using the l-values computed before the call. Only the actuals having l-values are copied.
#74 This is defined by the copy-rule as used in Algol.
The procedure is treated as if it were a macro; that is, its body is substituted for the call in the caller, with the actual parameters literally substituted for the formals. Such a literal substitution is called macro-expansion or inline expansion.
The local names of the called procedure are kept distinct from the names of the calling procedure. We can think of each local of the called procedure being systematically renamed into a distinct new name before macro-expansion is done.
The actual parameters are surrounded by parentheses if necessary to preserve their integrity.




















![program sort;
var a : array[0..10] of integer;
procedure readarray;
var i :integer;
:
function partition (y, z
:integer) :integer;
var i, j ,x, v :integer;
procedure quicksort (m, n
:integer);
var i :integer;
:
i:= partition (m,n);
quicksort (m,i-1);
quicksort(i+1, n);
:
begin{main}
readarray;
quicksort(1,9)
end.](https://image.slidesharecdn.com/compilerdesignruntimeenvironments-250505065510-7489eea4/75/Compiler-Design_Run-time-environments-pptx-25-2048.jpg)
























![ An alternative to access link ( a faster method to
access nonlocals ).
Using an array d of pointers to activation
records, the array is called a display.
Referencing nonlocal variables always requires
only two memory references.
Suppose control is in a procedure p at nesting
depth j, then the first j-1 elements of the display
point to the most recent activation of the
procedures that lexically enclose procedure p,
and d[j] points to the activation of p.
Displays](https://image.slidesharecdn.com/compilerdesignruntimeenvironments-250505065510-7489eea4/75/Compiler-Design_Run-time-environments-pptx-57-2048.jpg)
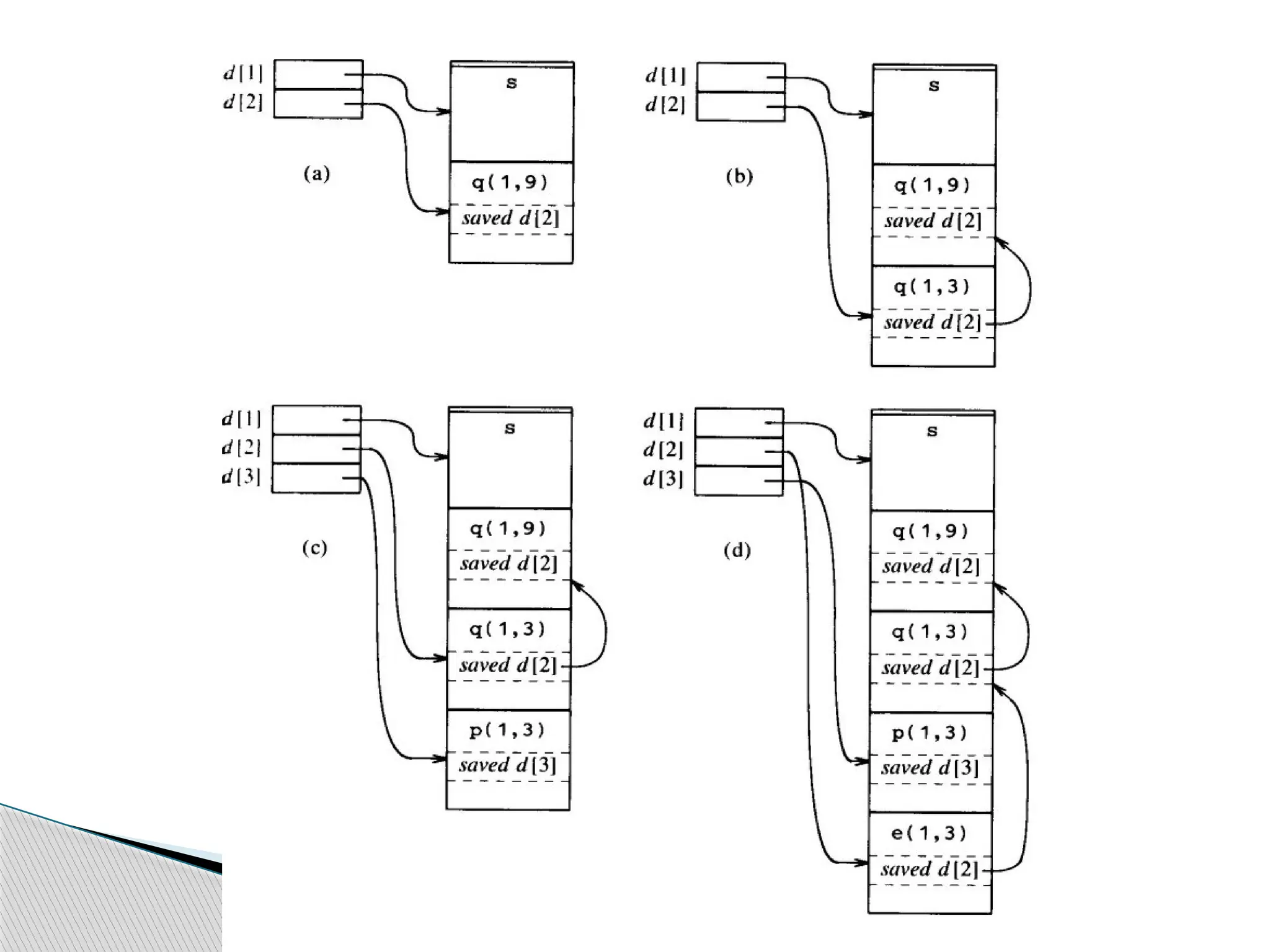
![Justification for Displays
Suppose procedure at depth j calls procedure at
depth i
Case j < i then i = j + 1
called procedure is nested within the caller
first j elements of display need not be changed
set d[i] to the new activation record
Case j i
≥
enclosing procedure at depthes 1…i-1 are same and are
left un-disturbed
old value of d[i] is saved and d[i] points to the new record
display is correct as first i-1 records are not disturbed](https://image.slidesharecdn.com/compilerdesignruntimeenvironments-250505065510-7489eea4/75/Compiler-Design_Run-time-environments-pptx-59-2048.jpg)











![ Call by name (used in Algol)
◦ names are copied
◦ local names are different from names of calling
procedure
swap(i,a[i])
temp = i
i = a[i]
a[i] = temp
Parameter Passing …](https://image.slidesharecdn.com/compilerdesignruntimeenvironments-250505065510-7489eea4/75/Compiler-Design_Run-time-environments-pptx-71-2048.jpg)
![Example:
void p (int x)
{ ++x;}
The effect of p(a[i]) is of evaluating
++(a[i])](https://image.slidesharecdn.com/compilerdesignruntimeenvironments-250505065510-7489eea4/75/Compiler-Design_Run-time-environments-pptx-72-2048.jpg)






















![begin
array a[1..10] of integer;
integer n;
procedure p(b: integer);
begin
print(b);
n := n+1;
print(b);
b := b+5;
end;
a[1] := 10;
a[2] := 20;
a[3] := 30;
a[4] := 40;
n := 1;
p(a[n+2]);
new_line;
print(a);
end;](https://image.slidesharecdn.com/compilerdesignruntimeenvironments-250505065510-7489eea4/75/Compiler-Design_Run-time-environments-pptx-100-2048.jpg)
































































