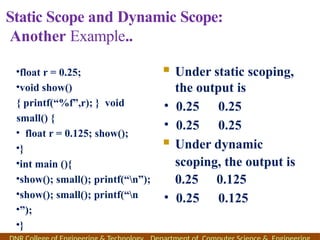
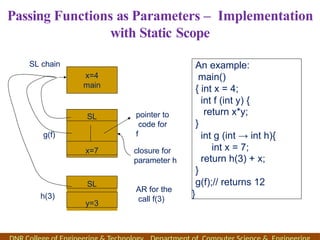
The document outlines the syllabus and course objectives for a compiler design course at DNR College of Engineering & Technology, covering various units such as language processing, lexical and syntax analysis, code generation, and optimization techniques. It emphasizes the practical application of compiler technology, including the use of tools like lex and yacc, as well as theoretical concepts such as static and dynamic scoping. Additionally, it includes references to key textbooks and specifies the learning outcomes for students in the course.




































![1 a) Differentiate between Static and Dynamic Storage allocation Strategies. [7M]
Oct-2019
b) What is dangling Reference in storage allocation? Explain with an Example. [8M]
2. What is a Flow Graph? Explain how a given program can be converted in to a Flow
graph? [8M] Oct-2019
3. a) Define Symbol table? Explain about the data structures used for Symbol table. 8M
b) Explain in brief abotu Stack Storage allocation strategy. [8M] May-2019
4 a) Consider the C program and generate the code and Write different object code
forms Main() { int i, a[10]; while (i<=10) a[i]=i*5; } [8M] Oct-2018
b) What is Activation Record? Explain its usage in stack allocation strategy. How it is
different from heap allocation? [7M]
IMPORTANT QUESTIONS](https://image.slidesharecdn.com/16cdunit-v-1-250123041405-bcb7714a/85/iii-ii-cd-nCompiler-design-UNIT-V-1-pptx-38-320.jpg)
![5 a) What is a leader of basic block? Write and explain the algorithm used to find
leaders. Draw flow graph for matrix multiplication. [8M] May-2018
b) Draw and explain the Runtime memory organization static storage allocation
strategy with pros and cons. [8M]
6 a) What is reference counting? Explain how they are used in garbage collection. [8M]
b) Efficient Register allocation and assignment improves the performance of object
code-Justify this statement with suitable examples. Nov-2017
7 a) Define Symbol table. Explain about the data structures for Symbol table. [8M]
b) Explain reducible and non reducible flow graphs with examples. [8M] May-2017
8 a) What is meant by activation of procedure? How it can be represented with
activation tree and record? Explain with quick sort example. [8M] Nov-2016
b) Explain the functional issues to be considered while generating the object code. [8M
9 a) What are the contents of a symbol table? Explain in detail the symbol table
organization for block-Structured languages. [8M] May-2016
b) Explain in detail about Stack allocation scheme. [8M]
IMPORTANCE QUESTIONS](https://image.slidesharecdn.com/16cdunit-v-1-250123041405-bcb7714a/85/iii-ii-cd-nCompiler-design-UNIT-V-1-pptx-39-320.jpg)



![1. a) Define Symbol table? Explain about the data structures used for Symbol table. 8M
b) Explain in brief about Stack Storage allocation strategy. [8M] May-2019
A symbol table may serve the following purposes depending upon the language in
hand:
To store the names of all entities in a structured form at one place.
To verify if a variable has been declared.
To implement type checking, by verifying assignments and expressions in the
source
code are semantically correct.
To determine the scope of a name (scope resolution).
If a compiler is to handle a small amount of data, then the symbol table can be
implemented as an unordered list, which is easy to code, but it is only suitable for small
tables only.
Data Structure for Symbol Tables
In designing a Symbol-Table mechanism, there should be a scheme that allows,
adding new entries and finding existing entries in a table efficiently.
A symbol table can be implemented in one of the following ways:](https://image.slidesharecdn.com/16cdunit-v-1-250123041405-bcb7714a/85/iii-ii-cd-nCompiler-design-UNIT-V-1-pptx-43-320.jpg)


![Static vs Dynamic Memory Allocation
Static memory allocation is a method of
allocating memory, and once the
memory is allocated, it is fixed.
Dynamic memory allocation is a
method of allocating memory, and once
the memory is allocated, it can be
changed.
Modification
In static memory allocation, it is not
possible to resize after initial allocation.
In dynamic memory allocation, the
memory can be minimized or maximize
accordingly.
Implementation
Static memory allocation is easy to
implement.
Dynamic memory allocation is
complex to implement.
Speed
In static memory, allocation execution
is faster than dynamic memory
allocation.
In dynamic memory, allocation
execution is slower than static memory
allocation.
2 Differentiate between Static and Dynamic Storage allocation Strategies. [7M]
Oct-2019](https://image.slidesharecdn.com/16cdunit-v-1-250123041405-bcb7714a/85/iii-ii-cd-nCompiler-design-UNIT-V-1-pptx-46-320.jpg)

![3. What is a Flow Graph? Explain how a given program can be converted in to a Flow
graph? [8M]
Control Flow graph: - Once an `program is partitioned into basic blocks, we
represent
the flow of control between them by a flow graph. The nodes of the flow graph are the
basic blocks. There is an edge from block B to block C if and only if it is possible for
the first instruction in block C to immediately follow the last instruction in block B.
There are two ways that such an edge could be justified:
•There is a conditional or unconditional jump from the end of B to the beginning of C.
•C immediately follows B in the original order of the three-address
instructions, and B does not end in an unconditional jump.
In any of the above cases B is a predecessor of C, and C is a successor of B. Two
nodes
are added to the flow graph, called the entry and exit that do not correspond to
executable intermediate instructions. There is an edge from the entry to the first
executable node of the flow graph, that is, to the basic block that comes from the first
instruction of the intermediate code.](https://image.slidesharecdn.com/16cdunit-v-1-250123041405-bcb7714a/85/iii-ii-cd-nCompiler-design-UNIT-V-1-pptx-48-320.jpg)


































![Pre-Dac-Presentation [Autosaved]ph-d.ppt](https://cdn.slidesharecdn.com/ss_thumbnails/pre-dac-presentationautosaved-250121140912-ba31fea7-thumbnail.jpg?width=640&height=640&fit=bounds)






























