This document discusses runtime environments and compiler design. It contains the following key points:
- A runtime environment provides services like memory allocation, libraries, and environment variables to allow programs to execute. It maps program elements like names and identifiers to actual memory locations.
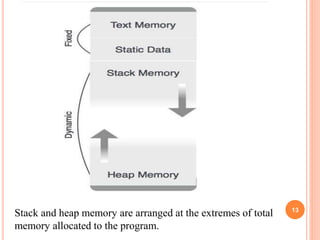
- Programs use stack allocation for procedure calls and return addresses. Variables use heap allocation which dynamically allocates and frees memory as needed.
- Symbol tables stored information about program elements to check scopes, declarations, and types. They are typically implemented as hash tables for efficient lookups. Scope is determined by nested symbol tables.


























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















