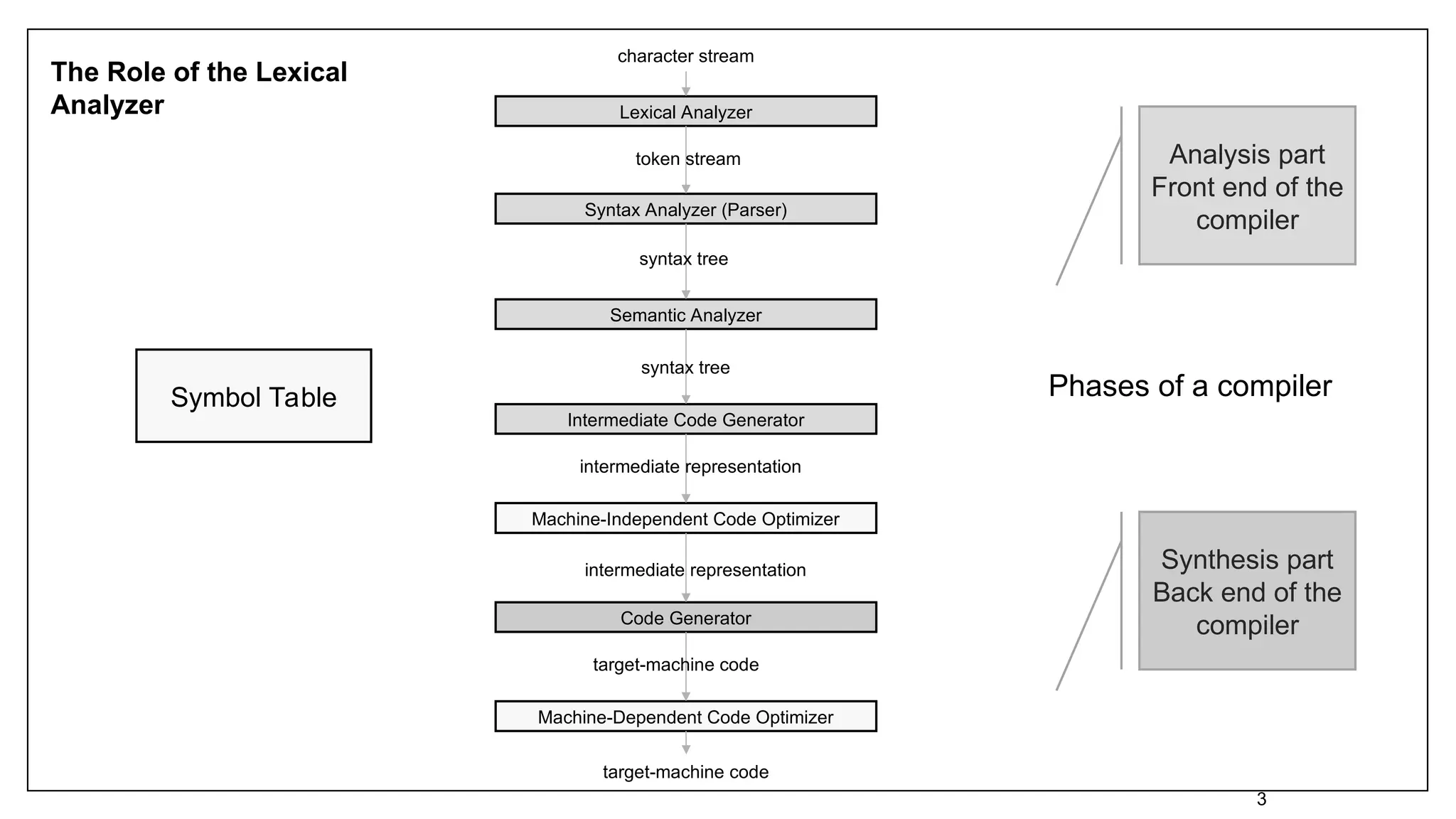
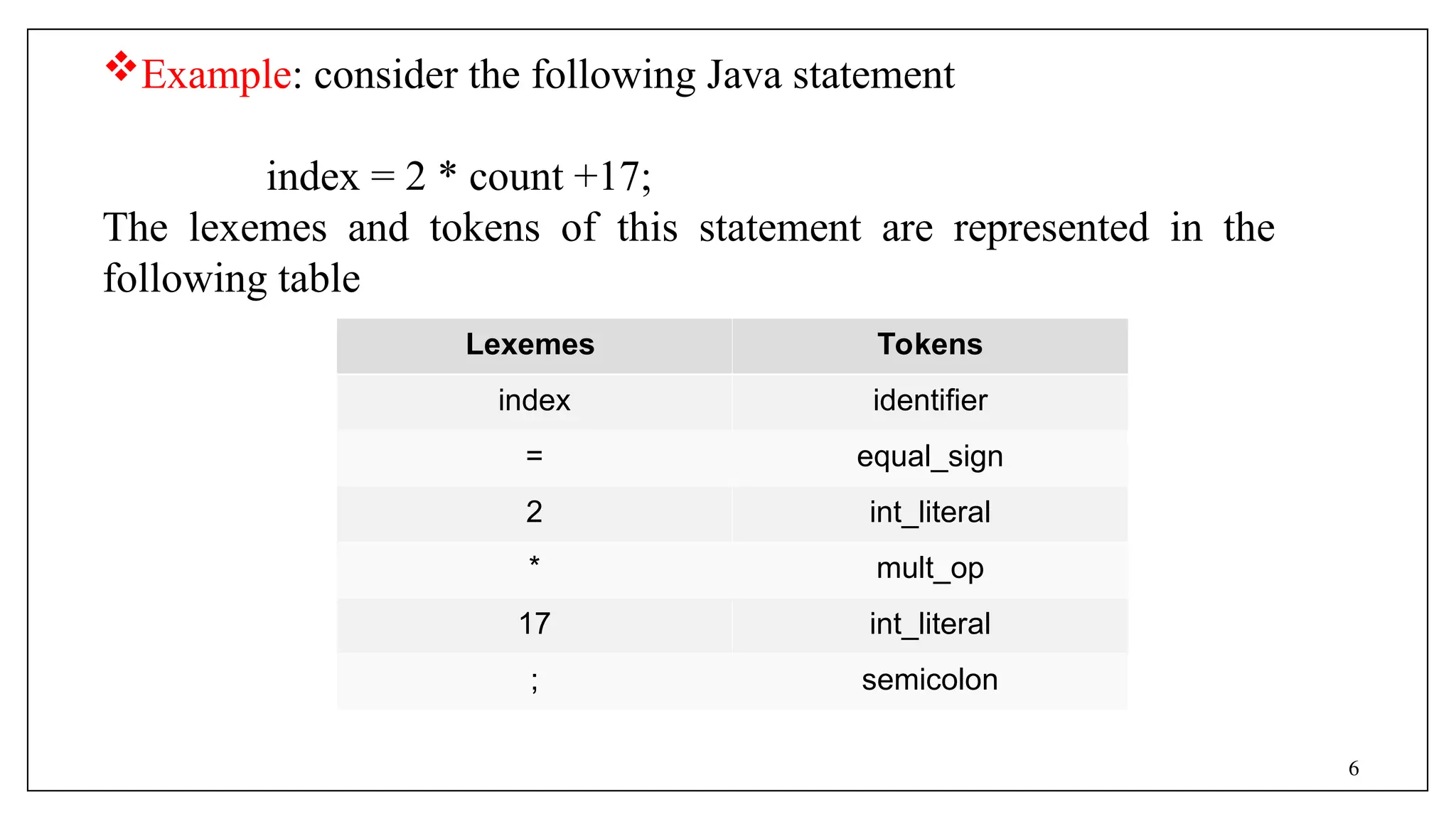
Waa barnaamij kombuyuutar oo u tarjuma barnaamij ku qoran hal luuqad (Source) una turjumaya barnaamijkiisa u dhigma ee luqadda kale. Barnaamijka Isha waa luqad heer sare ah oo sida luqadda Target ay noqon karto shay kasta laga bilaabo luqadda mashiinka mashiinka bartilmaameedka ah (inta u dhaxaysa Microprocessor ilaa Supercomputer) ilaa barnaamij kale oo luqadeed heer sare ah.
ΣLaba Turjumaan oo inta badan la isticmaalo ayaa kala ah Compiler iyo Turjumaan
Compiler: Compiler waa barnaamij, waxa uu ku akhriyaa hal luuqad oo lagu magacaabo Source Language waxa uuna ku turjumayaa barnaamijkiisa u dhigma luuqad kale oo la yiraahdo Target Language, waxa u sii dheer in uu macluumaadka qaladka ah u soo bandhigo isticmaalaha.










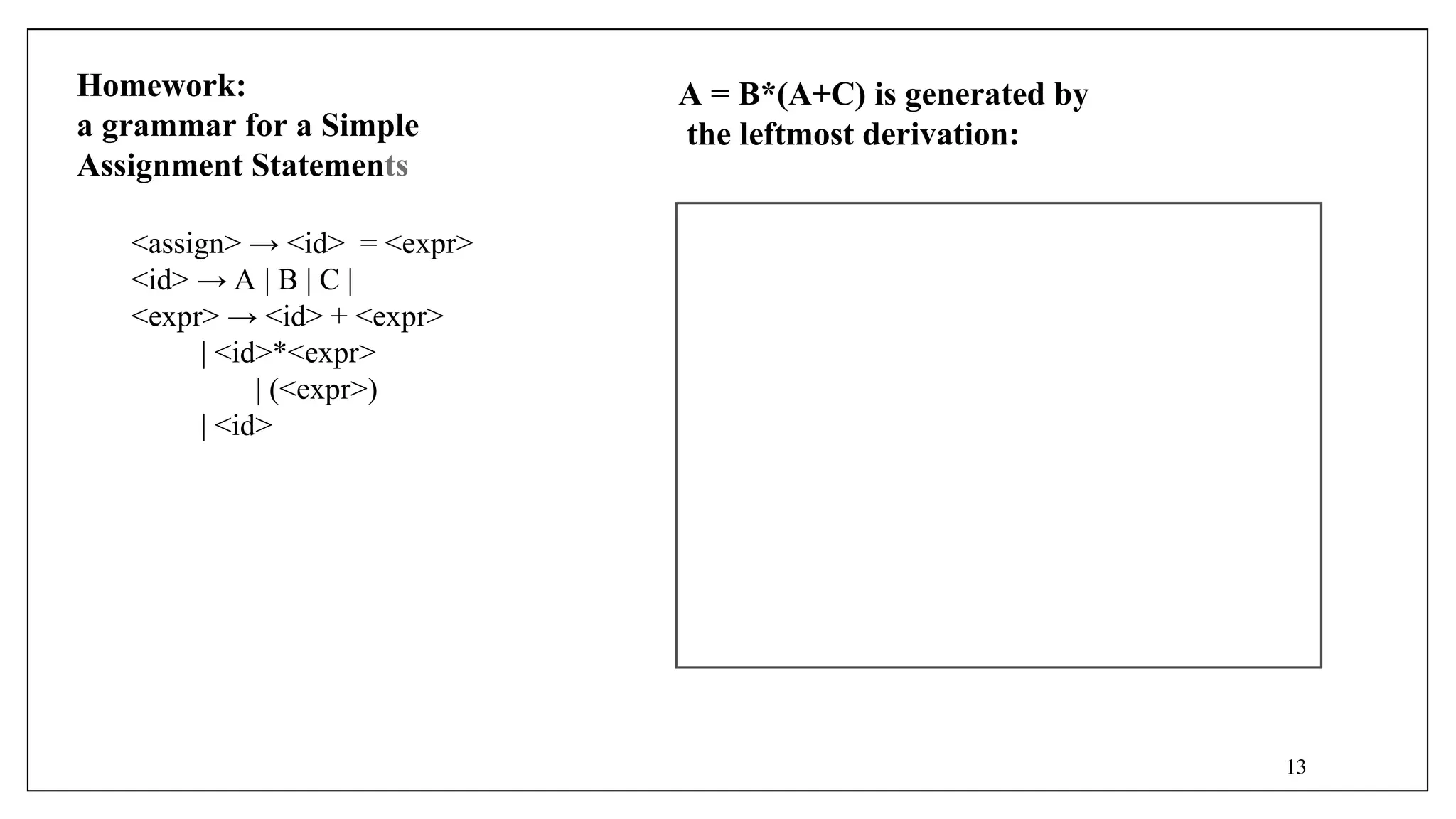

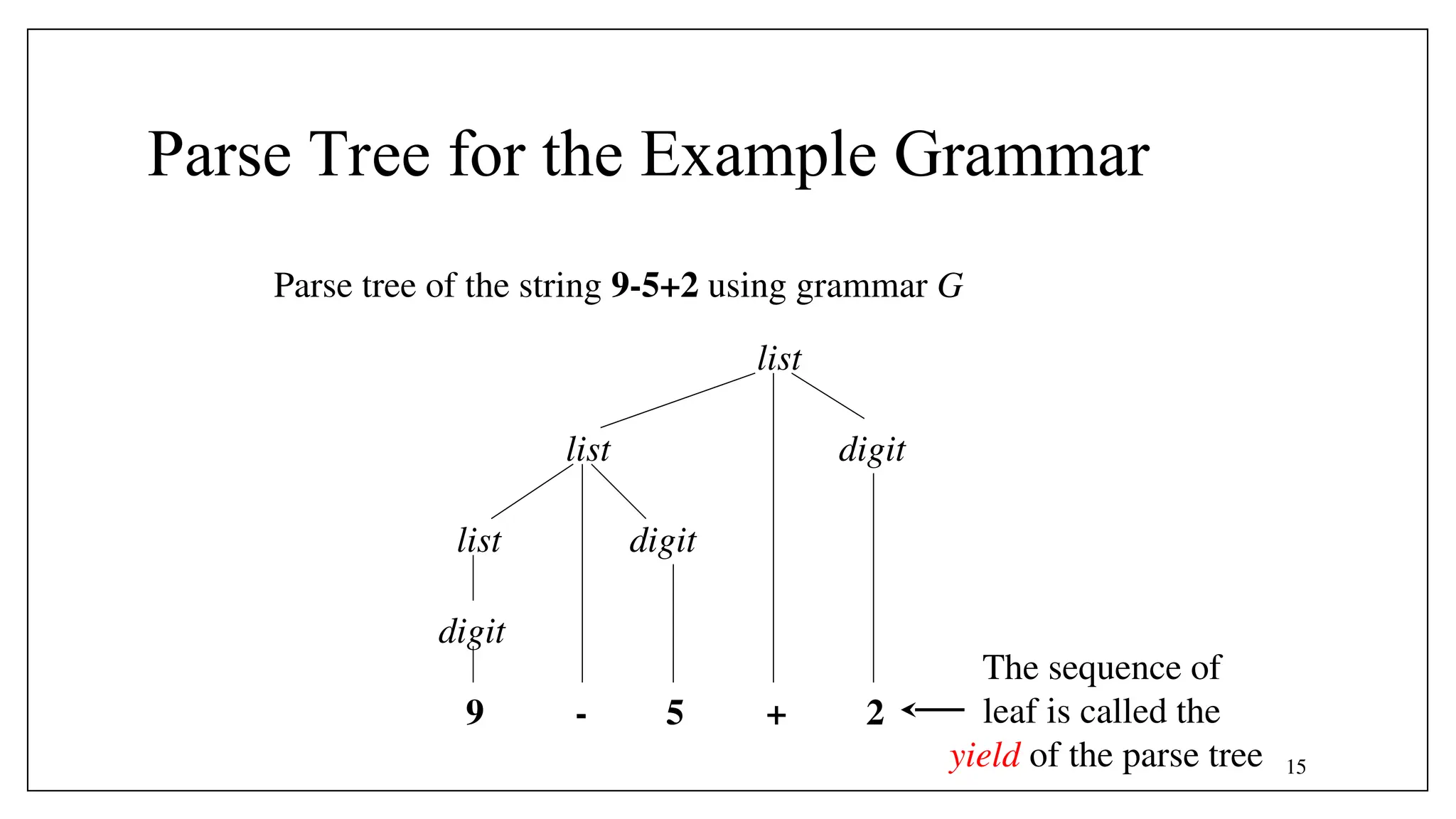






![- Optional parts are placed in brackets ([ ])
<if_stmt> → if (<expression>) <statement> [else
<statement>]
- Alternative parts of RHSs in parentheses and separate them with
vertical bars
<term> → <term> (* | / | %) <factor>
- Put repetitions (0 or more) are placed inside braces ({})
<ident_list> → <identifier> {, <identifier>}
- EBNF has the same expression power as BNF
- The addition includes optional constructs (parts), repetition, and multiple choices,
very much like regular expression.
Extended BNF
24](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-24-2048.jpg)







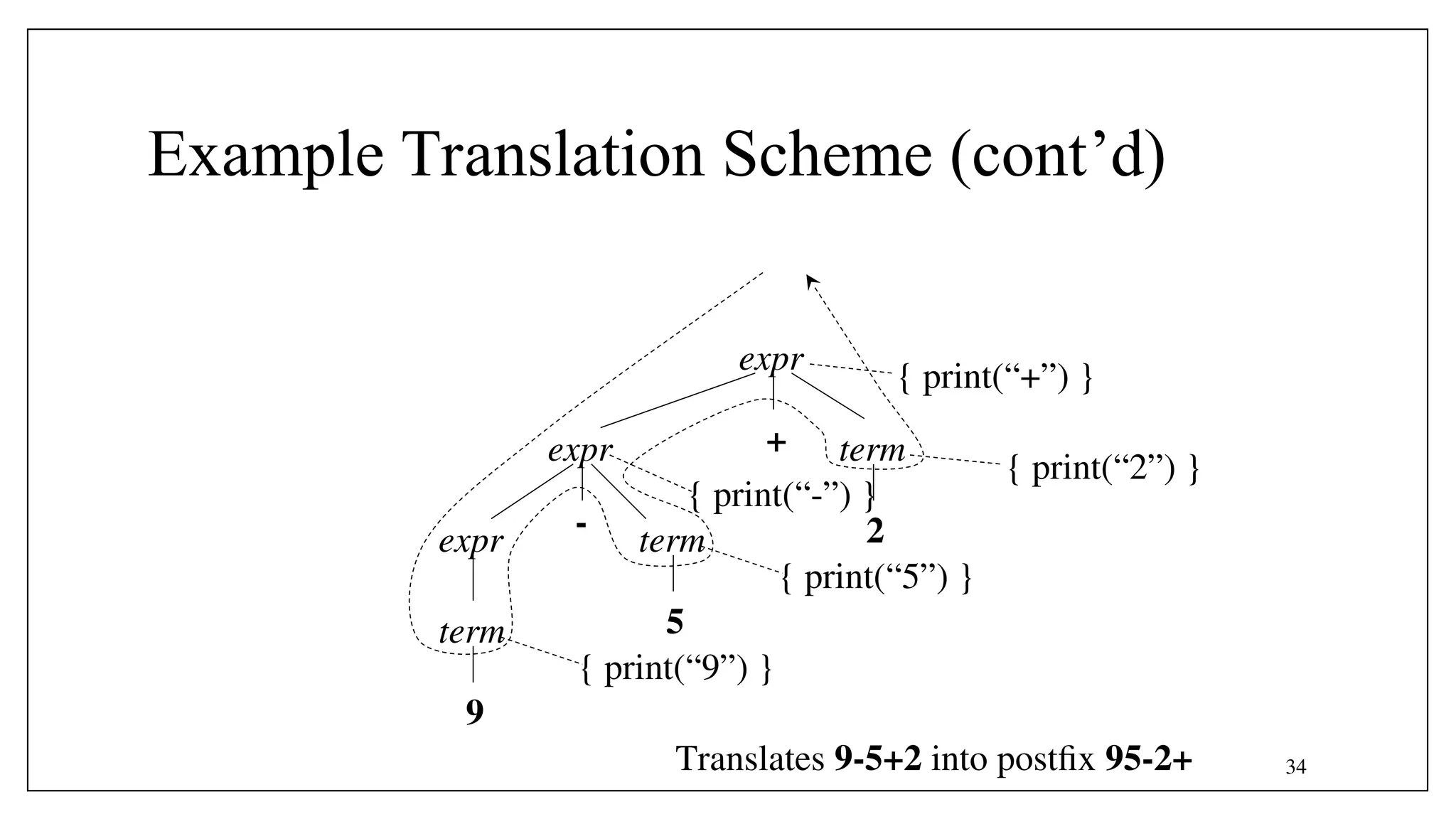


![37
Example Predictive Parser (Grammar)
type simple
| ^ id
| array [ simple ] of type
simple integer
| char
| num dotdot num](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-37-2048.jpg)
![38
Example Predictive Parser (Program
Code)
procedure match(t : token);
begin
if lookahead = t then
lookahead := nexttoken()
else error()
end;
procedure type();
begin
if lookahead in { ‘integer’, ‘char’, ‘num’ } then
simple()
else if lookahead = ‘^’ then
match(‘^’); match(id)
else if lookahead = ‘array’ then
match(‘array’); match(‘[‘); simple();
match(‘]’); match(‘of’); type()
else error()
end;
procedure simple();
begin
if lookahead = ‘integer’ then
match(‘integer’)
else if lookahead = ‘char’ then
match(‘char’)
else if lookahead = ‘num’ then
match(‘num’);
match(‘dotdot’);
match(‘num’)
else error()
end;](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-38-2048.jpg)
![39
Example Predictive Parser (Execution Step
1)
type()
match(‘array’)
array [ num num
dotdot ] of integer
Input:
lookahead
Check lookahead
and call match](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-39-2048.jpg)
![40
Example Predictive Parser (Execution Step
2)
match(‘array’)
array [ num num
dotdot ] of integer
Input:
lookahead
match(‘[’)
type()](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-40-2048.jpg)
![41
Example Predictive Parser (Execution Step
3)
simple()
match(‘array’)
array [ num num
dotdot ] of integer
Input:
lookahead
match(‘[’)
match(‘num’)
type()](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-41-2048.jpg)
![42
Example Predictive Parser (Execution Step
4)
simple()
match(‘array’)
array [ num num
dotdot ] of integer
Input:
lookahead
match(‘[’)
match(‘num’) match(‘dotdot’)
type()](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-42-2048.jpg)
![43
Example Predictive Parser (Execution Step
5)
simple()
match(‘array’)
array [ num num
dotdot ] of integer
Input:
lookahead
match(‘[’)
match(‘num’) match(‘num’)
match(‘dotdot’)
type()](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-43-2048.jpg)
![44
Example Predictive Parser (Execution Step
6)
simple()
match(‘array’)
array [ num num
dotdot ] of integer
Input:
lookahead
match(‘[’) match(‘]’)
match(‘num’) match(‘num’)
match(‘dotdot’)
type()](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-44-2048.jpg)
![45
Example Predictive Parser (Execution Step
7)
simple()
match(‘array’)
array [ num num
dotdot ] of integer
Input:
lookahead
match(‘[’) match(‘]’) match(‘of’)
match(‘num’) match(‘num’)
match(‘dotdot’)
type()](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-45-2048.jpg)
![46
Example Predictive Parser (Execution Step
8)
simple()
match(‘array’)
array [ num num
dotdot ] of integer
Input:
lookahead
match(‘[’) match(‘]’) type()
match(‘of’)
match(‘num’) match(‘num’)
match(‘dotdot’)
match(‘integer’)
type()
simple()](https://image.slidesharecdn.com/chapter2-250809145519-ea0c27db/75/Compiler-design-lessons-notes-from-Semester-46-2048.jpg)



















































