Download to read offline




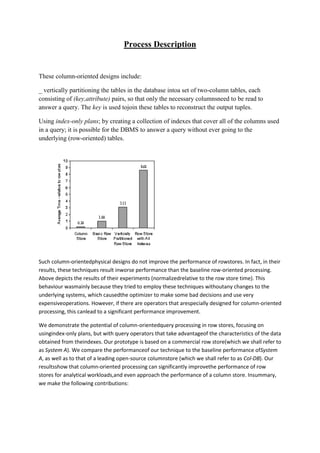

![Resources and Limitations
All of our experiments were run on an IBM System x3400(Model 7974) server, with a 1.6
GHz single processor, dualcore Intel Xeon CPU with 4 GB of RAM running FedoraLinux. The
server has a 1 TB Seagate SATA disk, with105 MB/sec sustained data rate at 7.2K RPM. The
serveralso has an 80 GB Fusion-IO IO-Disk SSD with a read bandwidthof 700 MB/sec and a
write bandwidth of 550 MB/sec.
The numbers we report are the average of several runs, andare based on a cold buffer pool.
We built a prototype usingSystem A. We used two TPC-H [2] data sets for ourexperiments,
with scale factors 10 and 30. The lineitemtable(fact table with 16 columns) contains 60
million rowsin the 10GB database, and 180 million rows in the 30GBdatabase. A typical data
warehousing query involves thefact table (lineitem) and one or more dimension tables,
withpredicates on the fact and/or dimension tables.](https://image.slidesharecdn.com/column-oriented-140114002510-phpapp01/85/Column-oriented-Transactions-7-320.jpg)
![Future scope and further enhancement
Several recent papers [3, 5, 8] have tackled the issue ofcomparing the performance of row
stores and column stores,and proposing optimizations for row stores in order for themto
compete with column stores for analytical workloads.
The work in [5] compares row stores and column stores.In particular, the authors try to
determine whether columnstore performance can be achieved in row stored usingcolumnoriented query processing. They simulate column-orientedprocessing by using both vertical
partitioning andindex-only plans in a commercial database system (referredto in the paper as
System X"), and compare the performanceof this system to the performance of C-Store [22].
In above Figure, System X performed very poorly withvertical partitioning, and even worse
with index-only plans.The reason for such a poor performance is because SystemX had to join
the (RID, value) lists coming from each indexusing a series of 2-way hash joins, each of
which builds anew hash table, which can be very expensive.
Bruno [8] argues that it is possible to achieve the performanceof column stores (or very close
to it) within row storeswithout any changes to the DBMS. The author proposes amethod to
store data in a compressed form, using a separatetable for each column in the original schema
(similar tothe vertical partitioning idea), but with these tables (called“c-tables”) storing
data in a format similar to run-length encoding.
The results show great performance improvement.However, this scheme requires creating a
c-table for everycolumn, and creating multiple indexes on every c-table, thusthe storage
requirements can grow rapidly. Additionally, thedependency between the tuples in the c-table
causes insertingnew rows to become very expensive, even for workloadswith infrequent
updates.Several optimizations have been implemented or proposedfor row-stores to approach
column-store performance, suchas super-tuples, using a column-based layout within eachdata
page, operating on compressed data, block processing,mirroring, invisible joins, late
materialization, and column-storeindexes [4, 12, 13, 15, 19, 20, 23, 24].
The idea of using multiple indexes to access data has beenstudied for some time. Mohan et al.
[16] introduced methodsfor using multiple indexes together to access base tables.
Raman et al. [21] presented two algorithms to perform theRID-list intersection operation,
which are comparable to thealgorithms we use for the low-cardinality indexes.
Flash memory has received increasing interest as a stablestorage media that can overcome the
access bottlenecks ofmagnetic disks. Researchers have considered modifying
existingalgorithms and data structures to make use of flashmemory. Flash-DB [17] is a selftuning flash-based index thatdynamically adapts to the mix of reads and writes in
theworkload. Flash-Logging [10] exploits using flash in appendmode for synchronous
logging.](https://image.slidesharecdn.com/column-oriented-140114002510-phpapp01/85/Column-oriented-Transactions-8-320.jpg)

![References
[1] MySQL, http://http://www.mysql.com/.
[2] TPC-H Benchmark, http://www.tpc.org/tpch.
[3] D. J. Abadi, P. A. Boncz, and S. Harizopoulos. Column oriented Database Systems.
PVLDB, 2(2):1664–1665, 2009.
[4] D. J. Abadi, S. Madden, and M. Ferreira. Integrating Compression and Execution in
Column-oriented Database Systems.In SIGMOD, 2006.
[5] D. J. Abadi, S. R. Madden, and N. Hachem. Column-Stores vs. Row-Stores: How
Different Are They Really? In SIGMOD, 2008.
[6] P. A. Boncz and M. L. Kersten.MIL Primitives for Querying a Fragmented World.VLDB
Journal,
8(2):101–119, 1999.
[7] P. A. Boncz, M. Zukowski, and N. Nes.MonetDB/X100: Hyper-Pipelining Query
Execution. In CIDR, 2005.
[8] N. Bruno. Teaching an Old Elephant New Tricks.In CIDR, 2009.
[9] M. Canim, G. A. Mihaila, B. Bhattacharjee, C. A. Lang, and K. A. Ross.Buffered Bloom
Filters on Solid State Storage.In ADMS, 2010.
[10] S. Chen. FlashLogging: Exploiting Flash Devices for Synchronous Logging
Performance. In SIGMOD, 2009.
[11] B. Debnath, S. Sengupta, and J. Li. FlashStore: High Throughput Persistent Key-Value
Store. In VLDB, 2010.
[12] G. Graefe. Efficient Columnar Storage in B-trees. SIGMOD Record, 36(1):3–6, 2007.
[13] A. Halverson, J. L. Beckmann, J. F. Naughton, and D. J. Dewitt.A Comparison of CStore and Row-Store in a Common Framework.Technical Report TR1570, University of
Wisconsin-Madison, 2006.
[14] Y.-R. Kim, K.-Y.Whang, and I.-Y. Song. Page-Differential Logging: An Efficient and
DBMS-Independent Approach for Storing Data into Flash Memory. In SIGMOD, 2010.
[15] P.-˚ A. Larson, C. Clinciu, E. N. Hanson, A. Oks, S. L. Price, S. Rangarajan, A. Surna,
and Q. Zhou. SQL Server Column Store Indexes.In SIGMOD, 2011.
[16] C. Mohan, D. J. Haderle, Y. Wang, and J. M. Cheng. Single Table Access Using
Multiple Indexes: Optimization, Execution, and Concurrency Control Techniques. In EDBT,
1990.
[17] S. Nath and A. Kansal.FlashDB: Dynamic Self-Tuning Database for NAND Flash. In
IPSN, 2007.
[18] S. Padmanabhan, B. Bhattacharjee, T. Malkemus, L. Cranston, and M. Huras. MultiDimensional Clustering: A New Data Layout Scheme in DB2. In SIGMOD, 2003.
[19] S. Padmanabhan, T. Malkemus, R. C. Agarwal, and A. Jhingran. Block Oriented
Processing of Relational Database Operations in Modern Computer Architectures. In ICDE,
2001.
[20] R. Ramamurthy, D. J. DeWitt, and Q. Su.A Case for Fractured Mirrors.In VLDB, 2002.
[21] V. Raman, L. Qiao, W. Han, I. Narang, Y.-L. Chen, K.-H.Yang, and F.-L. Ling. Lazy,
Adaptive RID-List Intersection, and Its Application to Index Anding.In SIGMOD, 2007.
[22] M. Stonebraker, D. J. Abadi, A. Batkin, X. Chen, M. Cherniack, M. Ferreira, E. Lau, A.
Lin, S. Madden, E. O’Neil, P. O’Neil, A. Rasin, N. Tran, and S. Zdonik. C-Store: A ColumnOriented DBMS. In VLDB, 2005.
[23] D. Tsirogiannis, S. Harizopoulos, M. A. Shah, J. L. Wiener, and G. Graefe. Query
Processing Techniques for Solid State Drives.In SIGMOD, 2009.](https://image.slidesharecdn.com/column-oriented-140114002510-phpapp01/85/Column-oriented-Transactions-10-320.jpg)

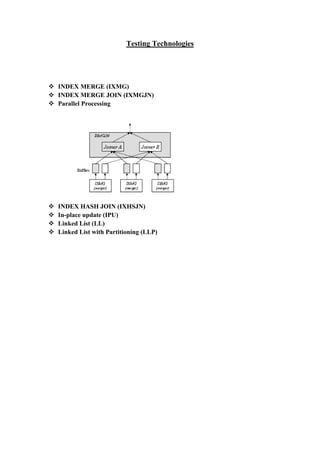
Column-oriented query processing techniques can significantly improve the performance of row-oriented database systems when applied properly. The authors introduce new operators such as index merge, index merge join, and index hash join that take advantage of parallel processing and unique characteristics of database indexes. An experimental study shows their approach using these operators on a commercial row-oriented database system approaches the performance of a column-oriented database system.

































































