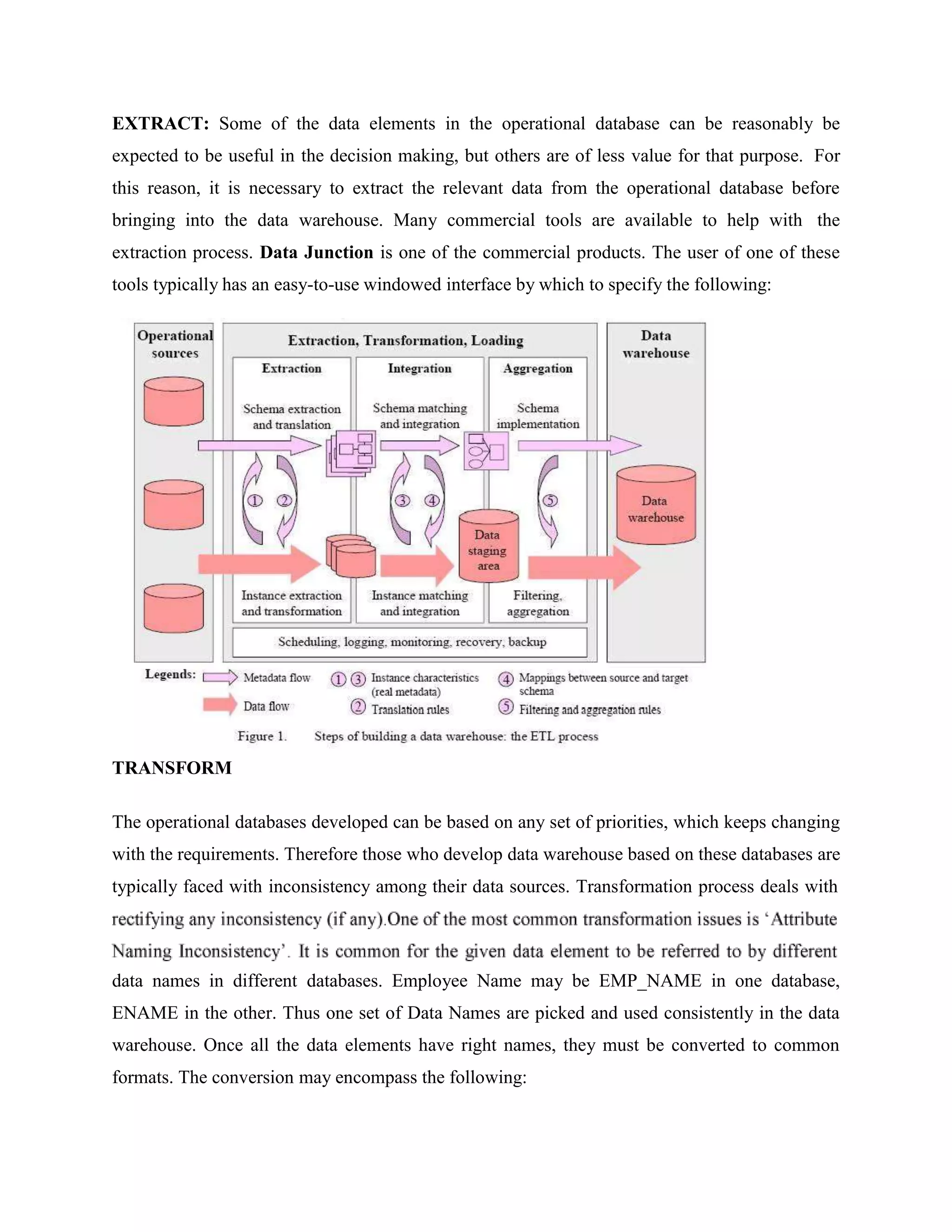
Operational database systems are designed to support transaction processing while data warehouses are designed to support analytical processing and report generation. Operational systems focus on business processes, contain current data, and are optimized for fast updates. Data warehouses are subject-oriented, contain historical data that is rarely changed, and are optimized for fast data retrieval. The three main components of a data warehouse architecture are the database server, OLAP server, and client tools. Data is extracted from operational systems, transformed, cleansed, and loaded into fact and dimension tables in the data warehouse using the ETL process. Multidimensional schemas like star, snowflake, and constellation organize this data. Common OLAP operations performed on the data include roll-up,