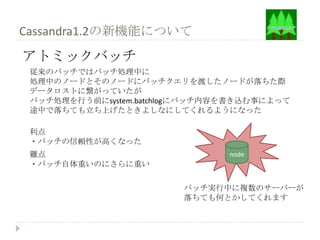
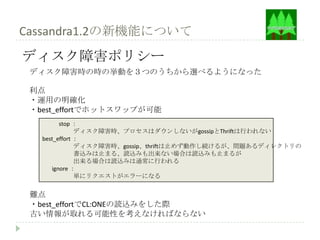
Cassandra1.2の新機能について
CQL3 Sets, Maps,Lists のコレクション対応
CQL3ではSets Maps Lists の型がカラムとして入れられるようになった
利点
・シリアライズ化して突っ込まなくてもよくなった
難点
・プライマリーキーとして宣言は出来ない
CREATE TABLE points (
id text PRIMARY KEY,
point list<int>
); id | point
insert into points (id, point) values ('test',[2,4,7,9]);
= ------+--------
test | [2, 7]
update points set point = point - [4, 9] where id = 'test‘;
select * from points;
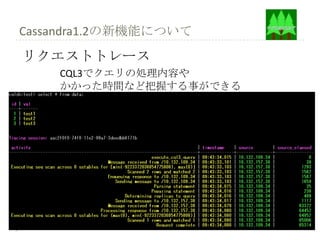
CQL3を使用してみる
Keyspaceとtableを作成
CREATEKEYSPACE space WITH strategy_class = 'SimpleStrategy'
AND strategy_options:replication_factor=1
しかしうまくいかな
い・・・
実は1.1のCQL3と1.2のCQL3は別物
(1.2のCQLとして1.1のCQLが資料として乗っている場合がある)
20.
CQL3を使用してみる
気を取り直してKeyspaceとtableを作成
CREATEKEYSPACE space WITH replication = {
'class': 'SimpleStrategy',
'replication_factor': '1'
}; 定義が違う
use space;
CREATE TABLE books ( 複合キーを使用する場合は
title text, 連ねて宣言する
chapter int,
page int,
line int,
value text,
PRIMARY KEY (title,chapter,page,line)
);
Insert into books(title,chapter,page,line,value) values (‘test’,1,1,1,‘testString’);
21.
CQL3を使用してみる
select文でwhere句を試そう
select * frombooks where title = 'test' ○取得できた
select * from books where chapter = 1 ×allow filter?
select * from books where chapter = 1 allow filtering ○取得できた
select * from books where title = 'test' and chapter = 1 ○取得できた
select * from books where page = 1 ×取得できない
select * from books where title = 'test' and page = 1 ×取得できない
select * from books where title = 'test' and chapter = 1 and page = 1 ○取得できた
select * from books where title = 'test' and chapter = 1 and line = 1 ×取得できない
select * from books where value = 'testString' ×取得できない
なぜ?! ここでRDBMSから1.2に直接入ってきた人間はじわじわ死ぬ
CQL3を使用してみる
Table を変更してもう一度試してみよう
select *from books where title = 'test' ×取得できない
select * from books where chapter = 1 ×取得できない
select * from books where chapter = 1 allow filtering ×取得できない
select * from books where title = 'test' and chapter = 1 ×取得できない
select * from books where page = 1 ×取得できない
select * from books where title = 'test' and page = 1 ×取得できない
select * from books where title = 'test' and chapter = 1 and page = 1 ×取得できない
select * from books where title = 'test' and chapter = 1 and line = 1 ×取得できない
select * from books where value = 'testString' ×取得できない
悪化したんですけどお!!!!11!
実際のwhere文について
PRIMARY KEY ((title,chapter),page,line)
この場合のRowKey部分のwhere句
・RowKeyを含める場合は確実にRowKey全てを含める事
○ select * from books where title = 'book1' and chapter = 1
× select * from books where chapter = 1
× select * from books where title = 'book1'
・RowKeyで範囲検索をする際はtokenを使用する事
(パーテショナーを理解してから使用する事)
○ select * from books where token(title,chapter) >= token('book1', 1)
and token(title,chapter) <= token('book1', 99)
× select * from books where token(title) >= token('book1')
and token(title) <= token('book1')
30.
実際のwhere文について
PRIMARY KEY ((title,chapter),page,line)
この場合のColumn部分のwhere句
・Columnで検索する際は宣言した順番に指定する必要がある
またallow filtering は複数のRowKeyから指定したColumnを取得する場合に付与しなければならない
○ select * from books where page = 1 allow filtering
× select * from books where line = 1 allow filtering
○ select * from books where page = 1 and line = 1 allow filtering
・取得するRowKeyが一つの場合は allow filtering は付与しなくてもよ
い○ select * from books where title = 'book1' and chapter = 1 and page = 1
○ select * from books where title = 'book1' and chapter = 1 and page = 1 allow filtering
・Columnで範囲検索をする場合は一つのColumnのみ指定できる
○ select * from books where title = 'book1' and chapter = 1 and page >= 1 and page <= 99
× select * from books where title = 'book1' and chapter = 1 and page >= 1 and line >= 1
31.
実際のwhere文について
Primary key 以外のカラムをwhere文で使用したい場合
そのカラムにインデックスを張る
CREATE INDEX [<indexname>] ON <cfname> ( <colname> )
カラムファミリ booksのvalueというカラムにインデックスを張る場合
CREATE INDEX ON books (value);
value を使用して問い合わせる
select * from books where value = ‘test’
パーテーションキーが複合キーの場合
where句でパーテーションキーとの併用が・・・・
あと COMPACT STRAGE には使用できない・・・・
32.
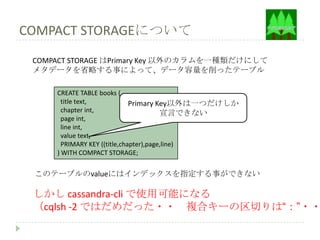
COMPACT STORAGEについて
COMPACTSTORAGE はPrimary Key 以外のカラムを一種類だけにして
メタデータを省略する事によって、データ容量を削ったテーブル
CREATE TABLE books (
title text, Primary Key以外は一つだけしか
chapter int, 宣言できない
page int,
line int,
value text,
PRIMARY KEY ((title,chapter),page,line)
) WITH COMPACT STORAGE;
このテーブルのvalueにはインデックスを指定する事ができない
しかし cassandra-cli で使用可能になる
(cqlsh -2 ではだめだった・・ 複合キーの区切りは“:”・・
33.
ByteOrderedPartitioner
にする事で可能なクエリ
・パーテーションキーの範囲検索がColumnと同じように可能
例えば
CREATE TABLE books (
title text,
chapter int,
page int,
line int,
value text,
PRIMARY KEY ((title,chapter),page,line)
);
の場合
Select * from books where title = ‘text’ and chapter > 3
and page = 1
and line >= 3 and line < 8 allow filtering
34.
ByteOrderedPartitioner
にする事で可能なクエリ
・複合パーテーションキーでのインデックス2個目の範囲検索
例えば
CREATE TABLE books (
title text,
chapter int, で、こんなクエリが可能
page int,
line int, Select * from books where title = ‘text’ and chapter > 3
value1 text, and page = 1
value2 text, and line >= 3 and line < 8
value3 text, and value1 = ‘test’
PRIMARY KEY ((title,chapter),page,line) and value2 > ‘a’ and value2 < ‘z’
); allow filtering
CREATE INDEX idx_001 ON books (value1);
CREATE INDEX idx_002 ON books (value2);
逆を言えば複合パーテーションキーでインデックス2個目の範囲検索は
ByteOrdered以外の場合は出来ない







![Cassandra1.2の新機能について
CQL3 Sets, Maps, Lists のコレクション対応
CQL3ではSets Maps Lists の型がカラムとして入れられるようになった
利点
・シリアライズ化して突っ込まなくてもよくなった
難点
・プライマリーキーとして宣言は出来ない
CREATE TABLE points (
id text PRIMARY KEY,
point list<int>
); id | point
insert into points (id, point) values ('test',[2,4,7,9]);
= ------+--------
test | [2, 7]
update points set point = point - [4, 9] where id = 'test‘;
select * from points;](https://image.slidesharecdn.com/1-21-2cql3-130310201817-phpapp02/85/1-2-1-2-cql3-11-320.jpg)
![Cassandra1.2の新機能について
新パーテショナー Murmur3
RandomPartitionerの早い安い旨い版
利点
・早い
・数値が少ない
・シノニムが生じるのが少ない
難点
・範囲変わって計算の仕方も変わった
・しれっとデフォルトに・・
・RandomPartitionerのレンジ範囲
0 ~ 2^127
( 0 ~ 170141183460469231731687303715884105728 )
・Murmur3Partitionerのレンジ範囲
-2^63 ~ 2^63 - 1
( -9223372036854775808 ~ 9223372036854775807 )
python -c 'print [((2**64 / リングのノード数) * i) - 2**63 for i in range(リングのノード数)]](https://image.slidesharecdn.com/1-21-2cql3-130310201817-phpapp02/85/1-2-1-2-cql3-12-320.jpg)












![データ構造
パーテーションキーを知る場合
今までのデータ構造を知ると良い リング一周 -2^63 ~ 2^63 – 1
(パーテショナーがMurmur3の場合)
テーブルではなくカラムファミリ
ColumnFamily[RowKey][Column] = value ノード1
ノード6 ノード2
RowKey パーテショ
ナー
ノード5 ノード3
RowKeyの値を変換
ノード4
RowKey = パーテーションキー 値によってリングのどこ
に位置するデータか決ま
る](https://image.slidesharecdn.com/1-21-2cql3-130310201817-phpapp02/85/1-2-1-2-cql3-25-320.jpg)
![データ構造
PRIMARY KEYの指定はColumnFamilyで
当てはめた考え方のほうが理解しやすい
ColumnFamily[RowKey][Column] = value
で言うPRIMARY KEYは
PRIMARY KEY ((RowKey),Column)
PRIMARY KEY ((title,chapter),page,line)
の場合ColumnFamilyで言う
ColumnFamily[title,chapter][page,line]](https://image.slidesharecdn.com/1-21-2cql3-130310201817-phpapp02/85/1-2-1-2-cql3-26-320.jpg)

![データ構造
Cassandraは原則 RowKey Column それぞれ1塊しか指定する事ができませ
ん
RowKeyはリング基準での一塊 ColumnはRowKeyに入っている一塊
ノード1
[00001]
[00002]
[00003]
ノード6 ノード2
[00004]
[00005]
[00006]
[00007]
ノード5 ノード3 [00008]
[00009]
ノード4 [00010]
ノード1~2 と ノード4~5 とか 00001 ~ 00003 と 00009~00008
同時に指定することは出来ない など同時に指定する事はできない](https://image.slidesharecdn.com/1-21-2cql3-130310201817-phpapp02/85/1-2-1-2-cql3-28-320.jpg)


![実際のwhere文について
Primary key 以外のカラムをwhere文で使用したい場合
そのカラムにインデックスを張る
CREATE INDEX [<indexname>] ON <cfname> ( <colname> )
カラムファミリ booksのvalueというカラムにインデックスを張る場合
CREATE INDEX ON books (value);
value を使用して問い合わせる
select * from books where value = ‘test’
パーテーションキーが複合キーの場合
where句でパーテーションキーとの併用が・・・・
あと COMPACT STRAGE には使用できない・・・・](https://image.slidesharecdn.com/1-21-2cql3-130310201817-phpapp02/85/1-2-1-2-cql3-31-320.jpg)