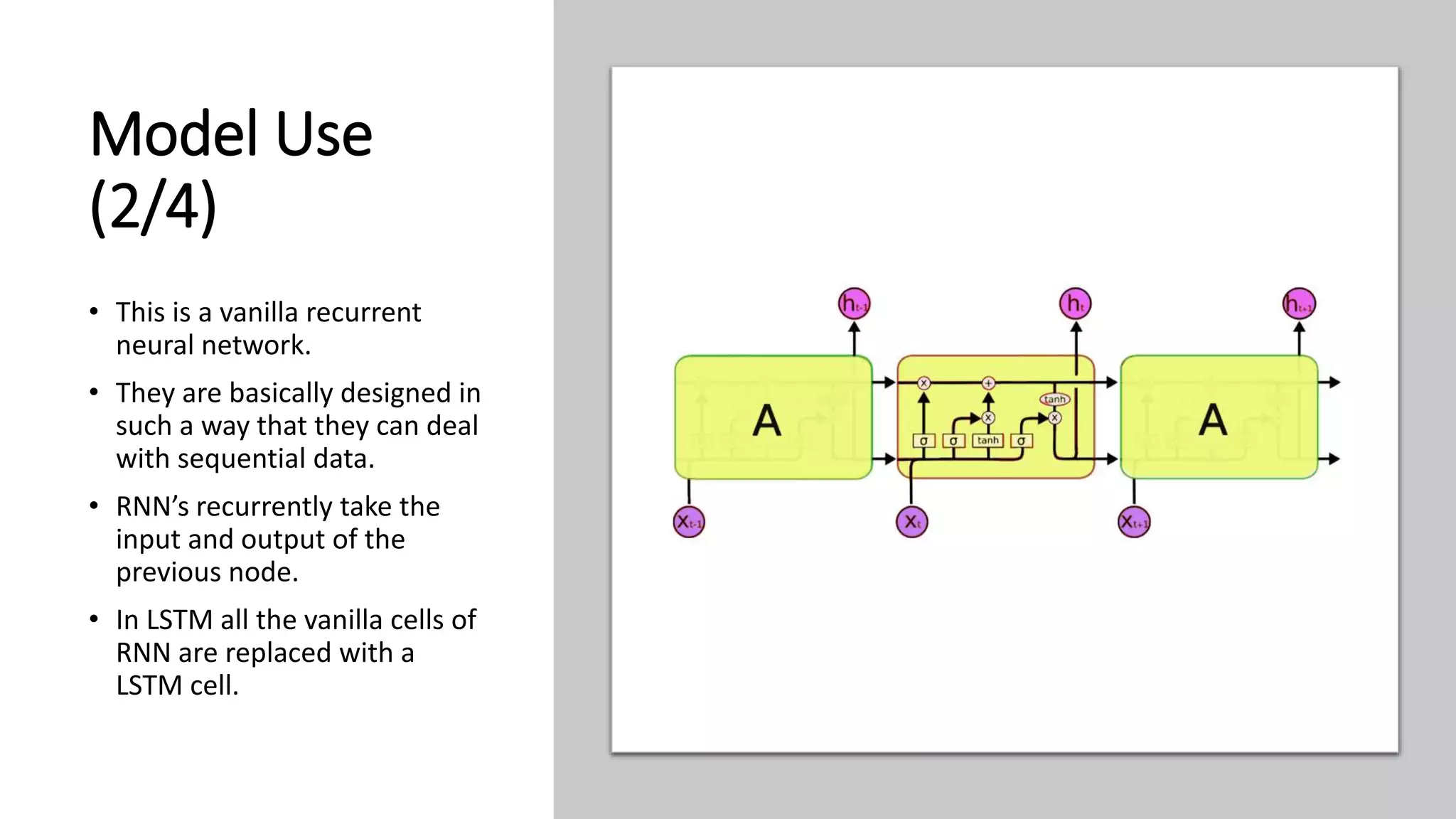
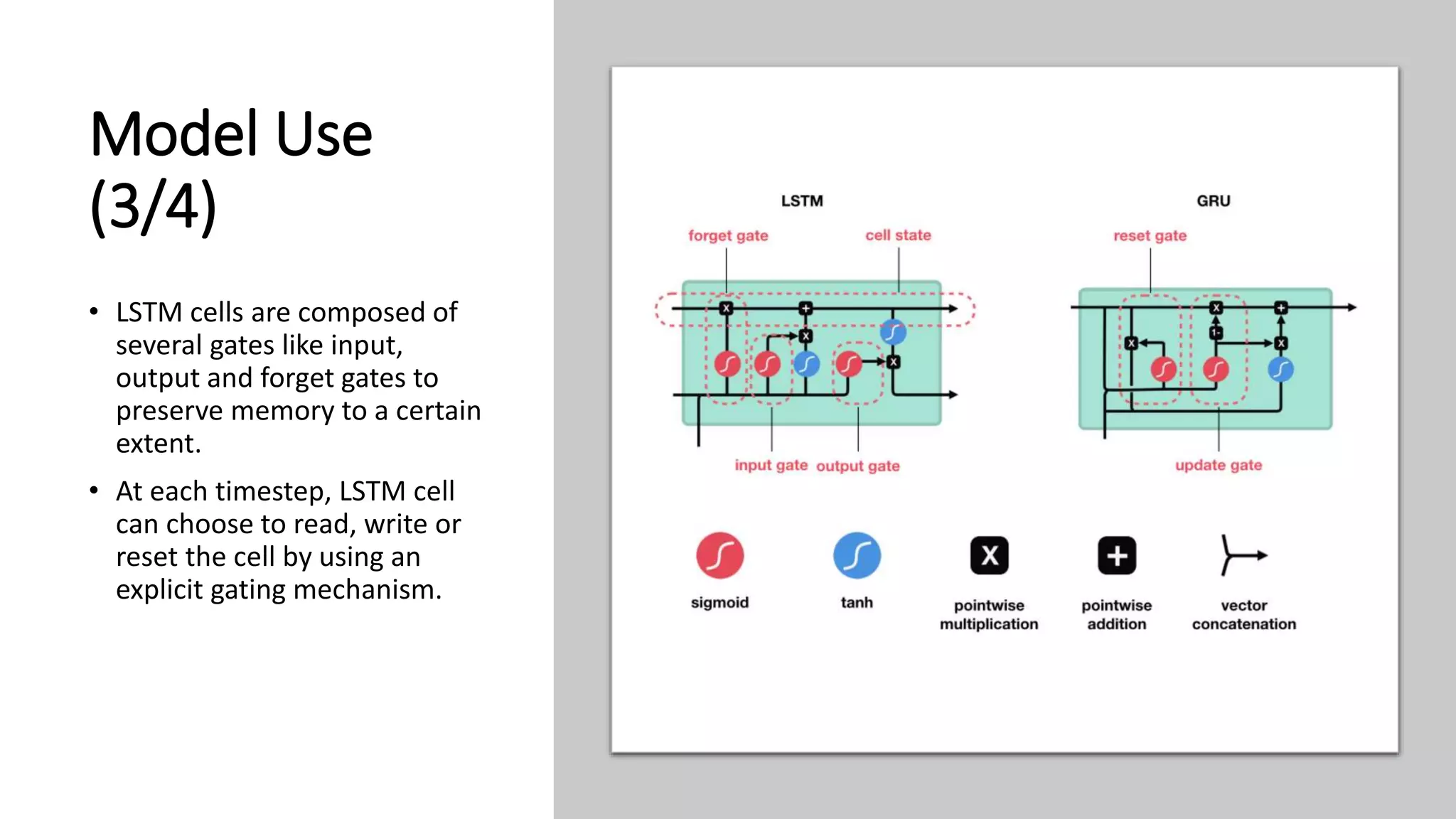
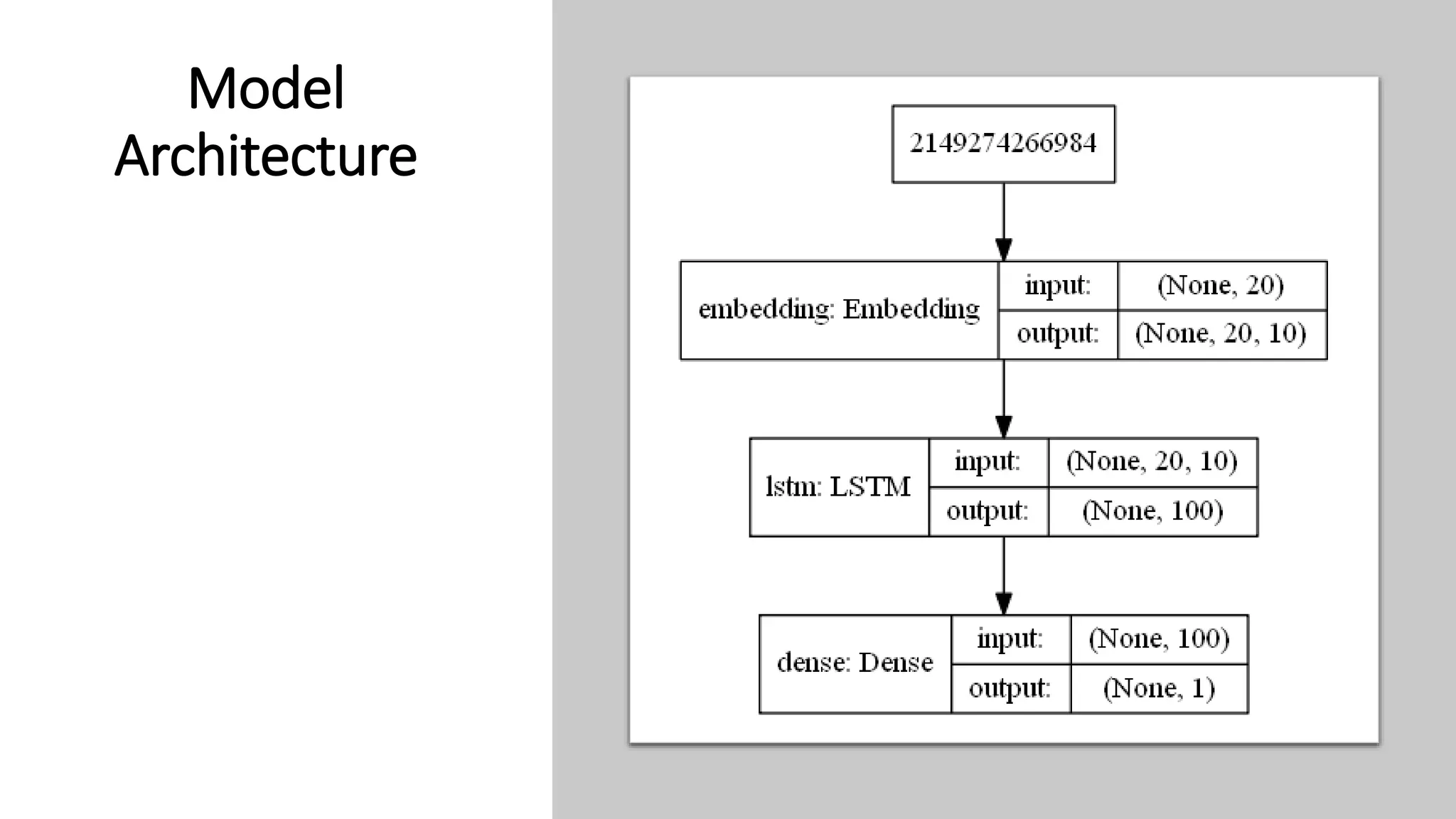
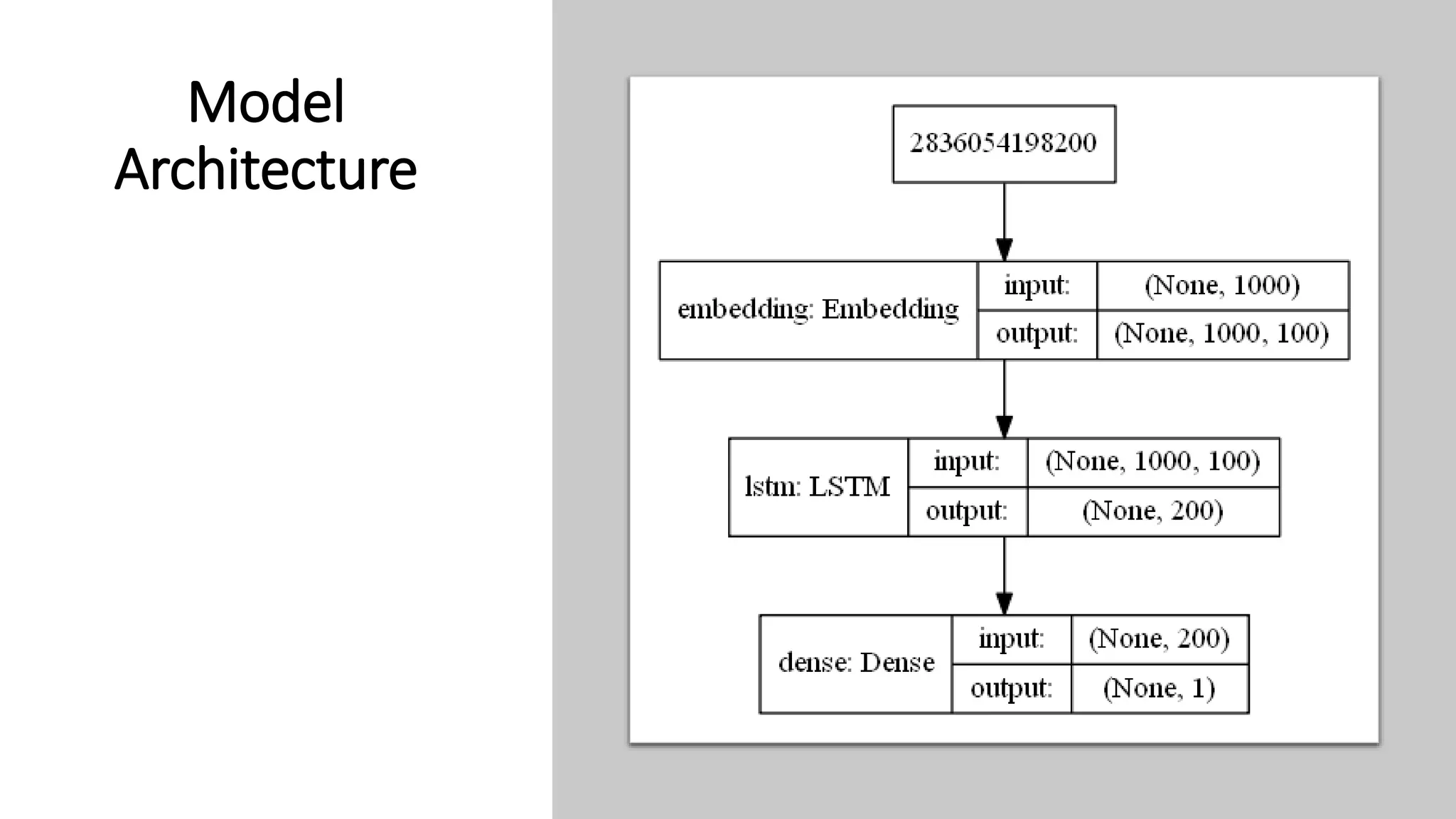
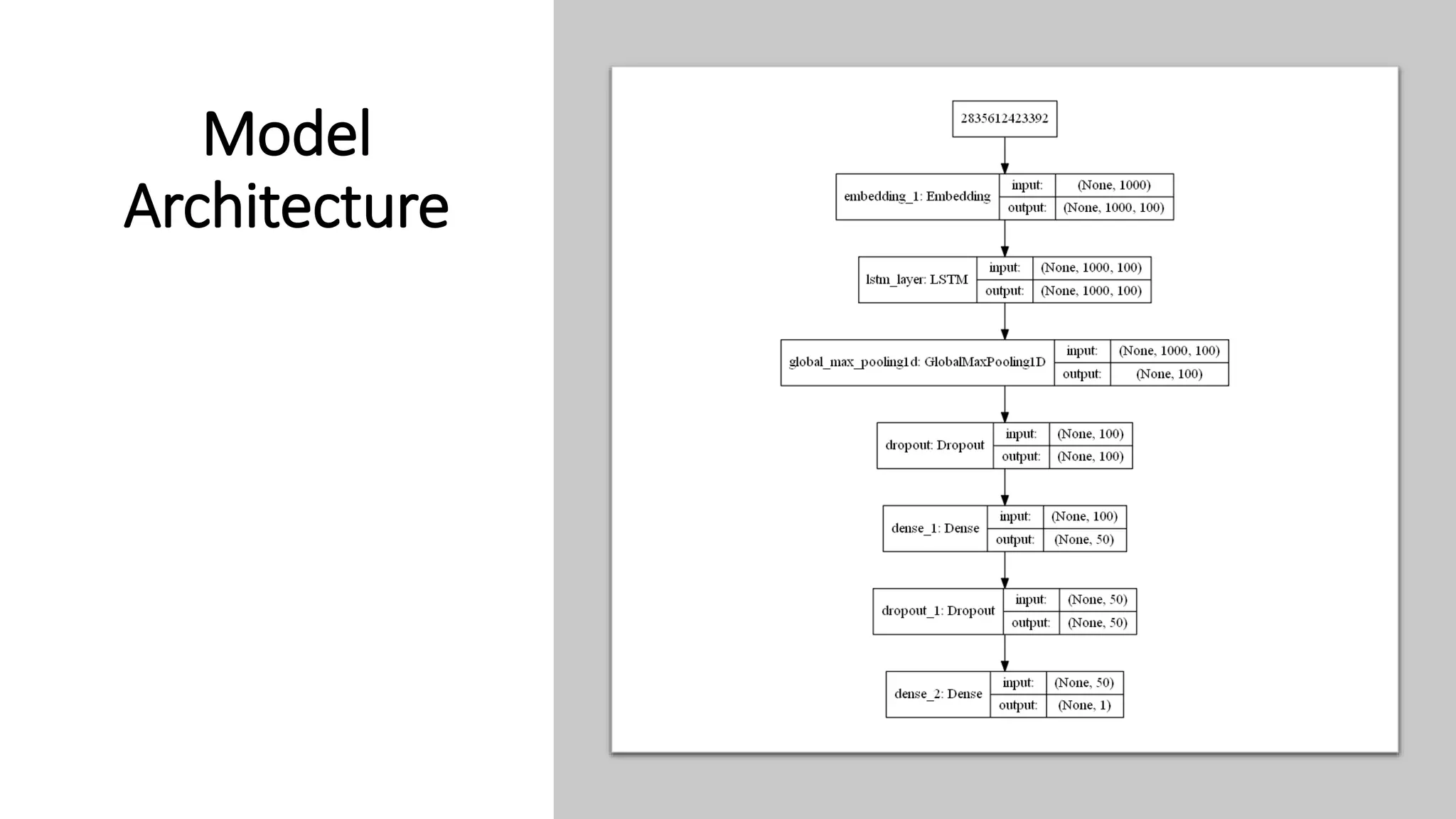
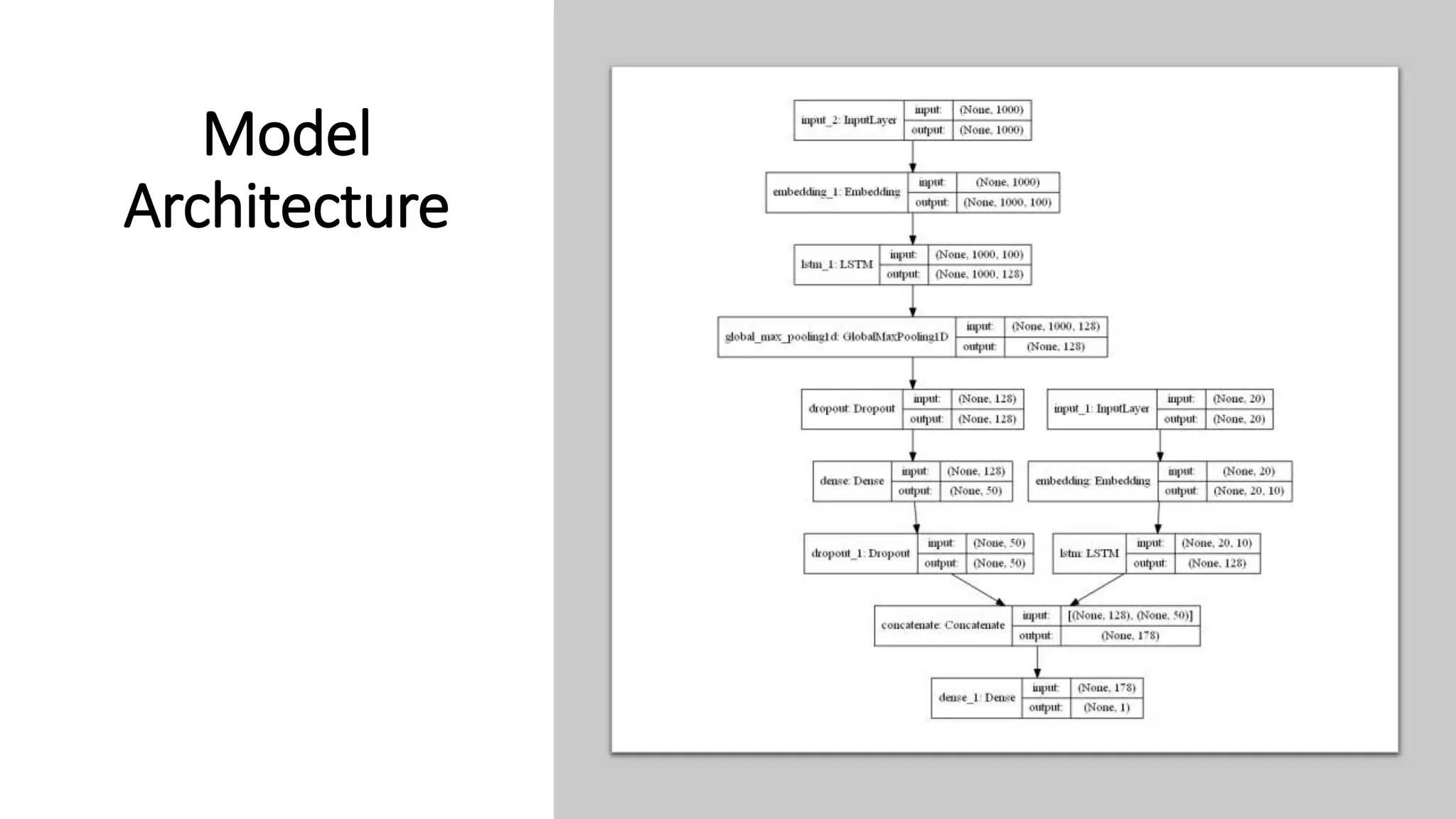
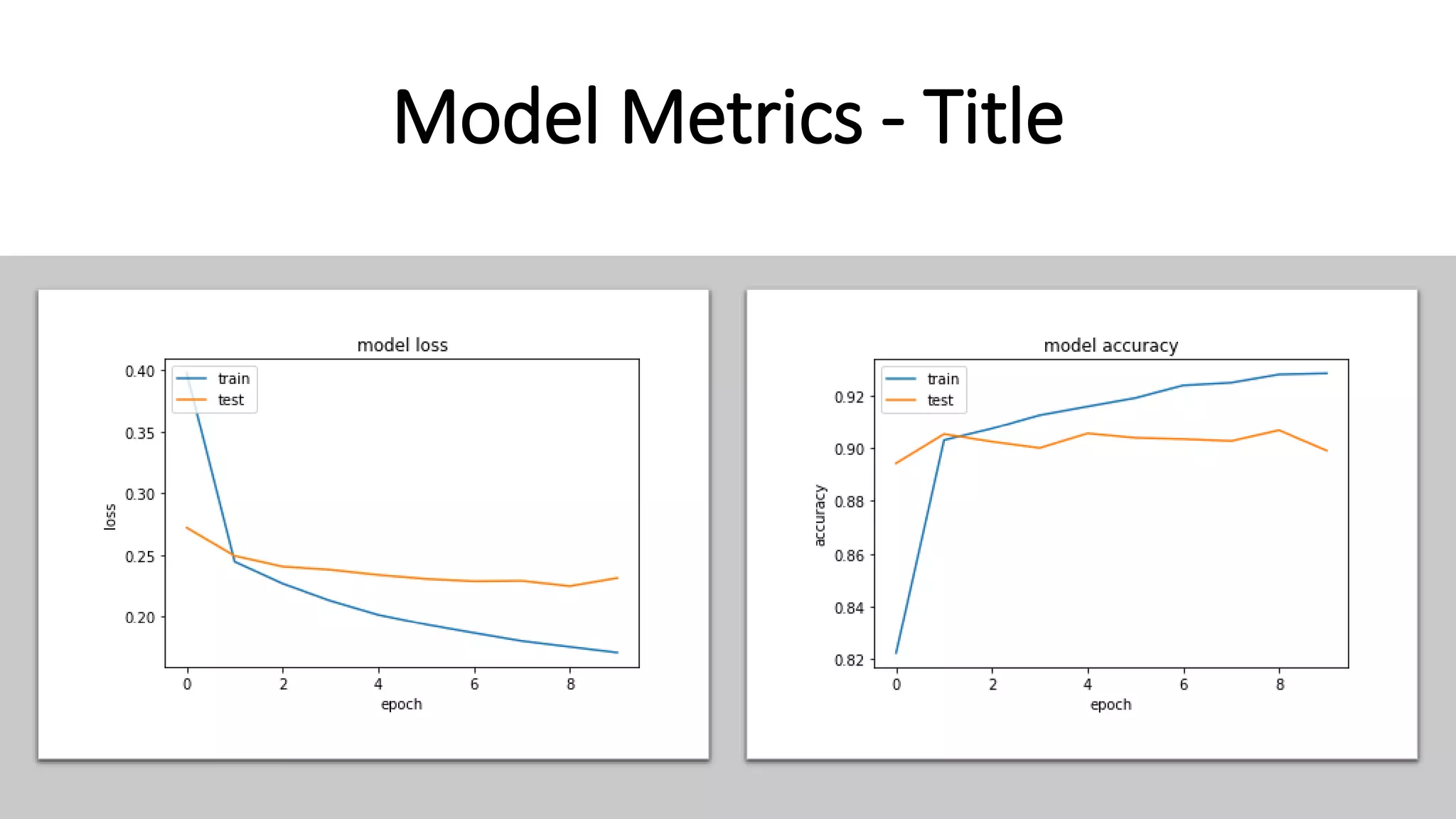
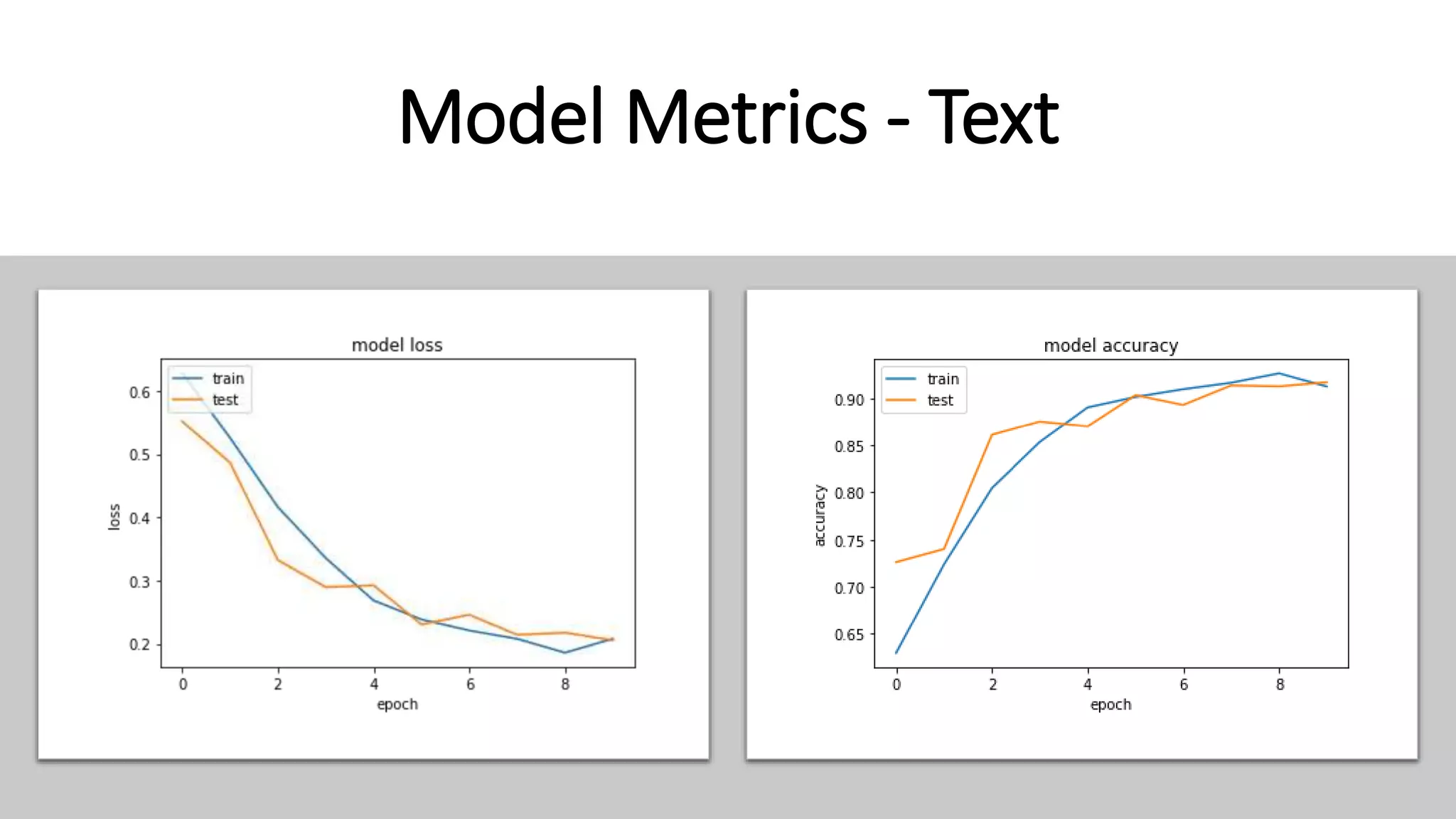
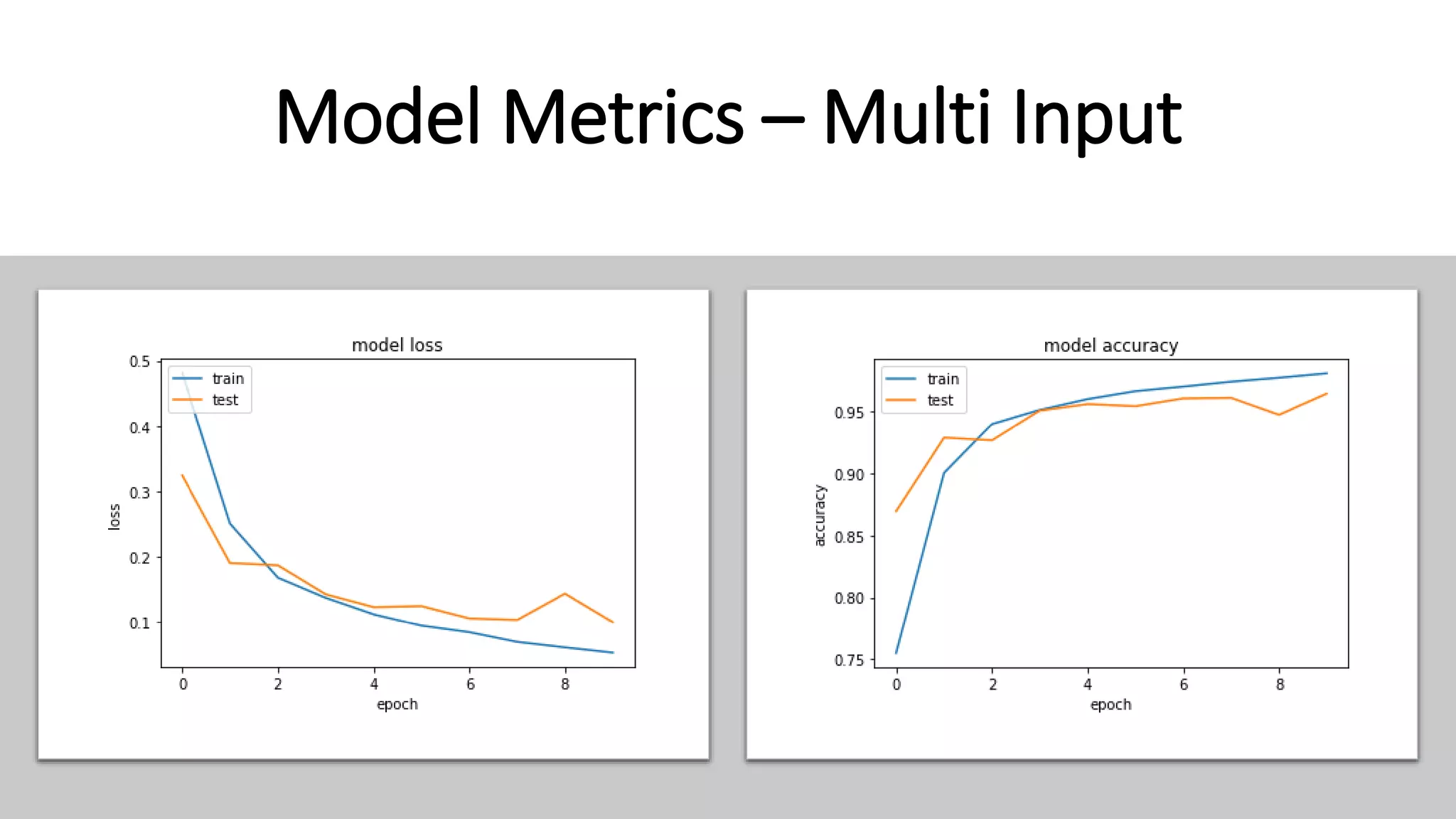
This document discusses fake news detection using LSTM neural networks. It presents exploratory data analysis of the dataset including corpus analysis, n-gram analysis and word clouds. It then discusses using LSTM for its ability to handle long sequential data better than RNNs. The model architecture uses an LSTM layer with embedding, padding and dropout. Metrics are presented for the title and text classification including a multi-input model. The conclusion discusses potential improvements like different n-grams, using RNN instead of bag-of-words, increased model size and hyperparameters tuning.













![NextWordPrediction_ppt[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nextwordpredictionppt1-231219040932-5e3a49be-thumbnail.jpg?width=640&height=640&fit=bounds)







































