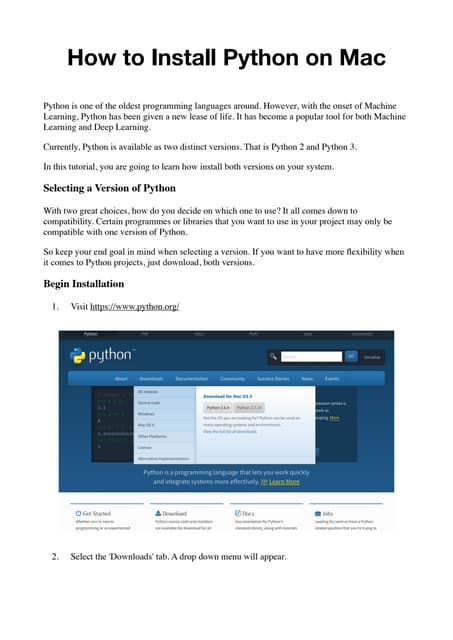
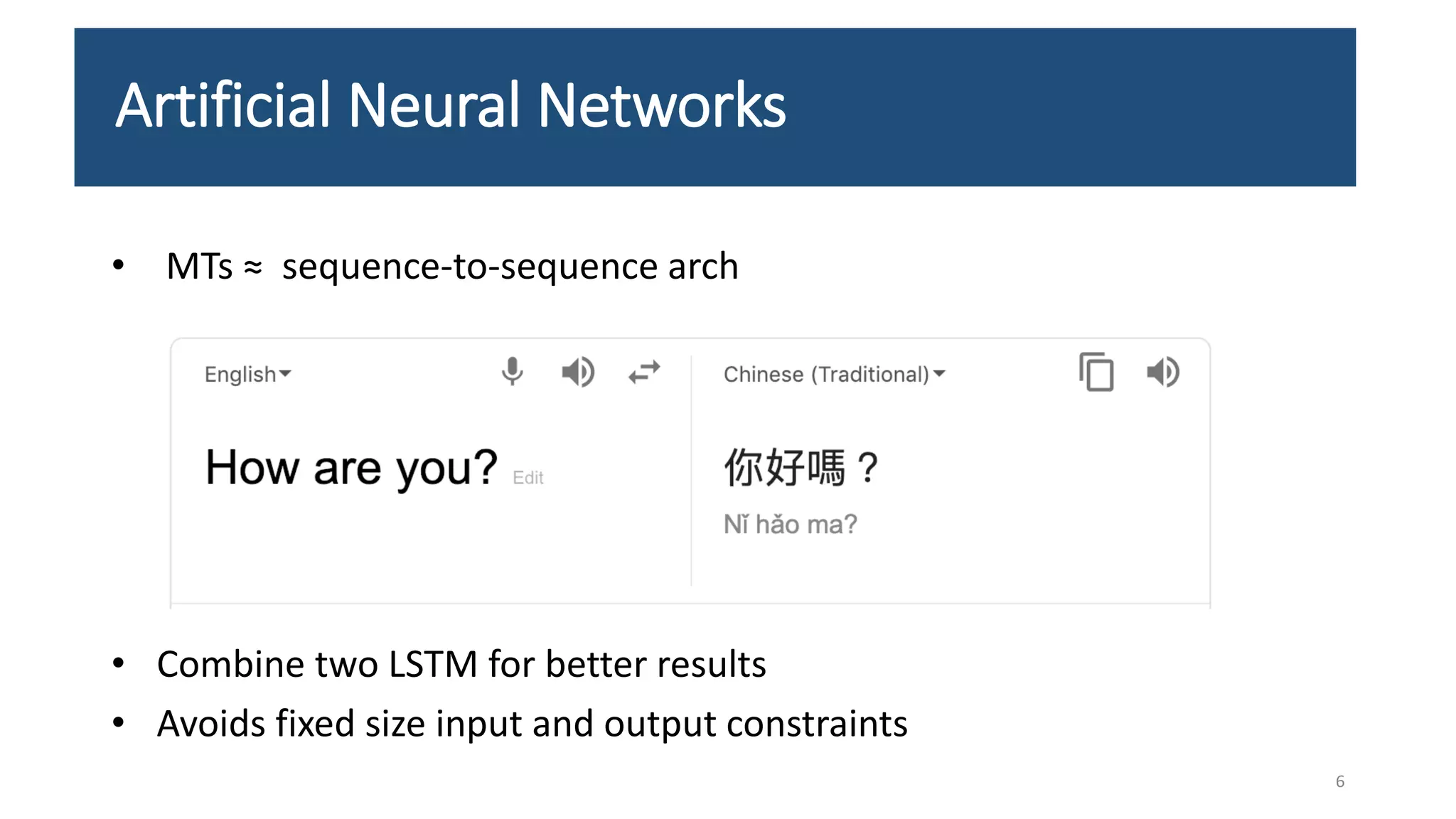
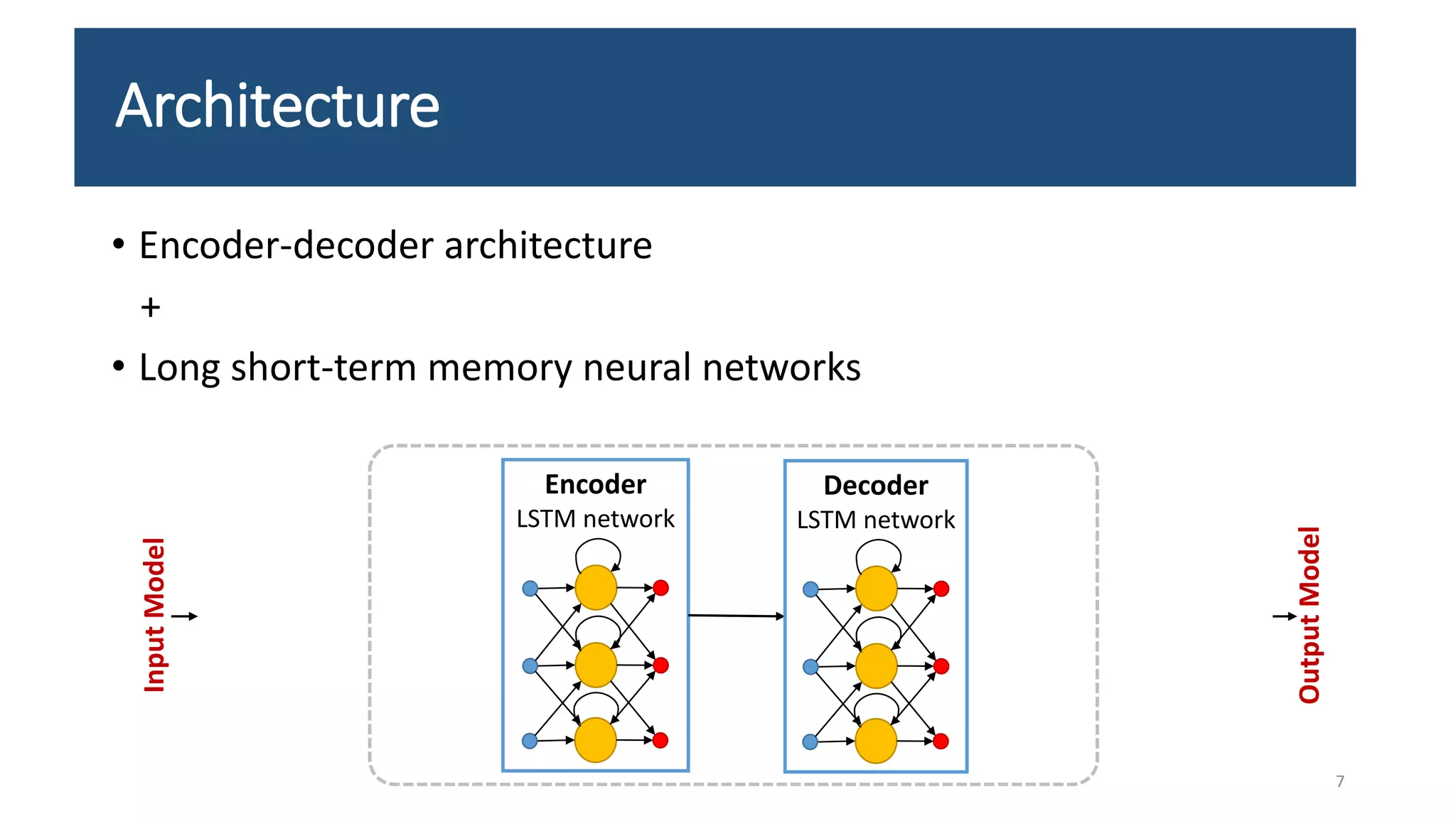
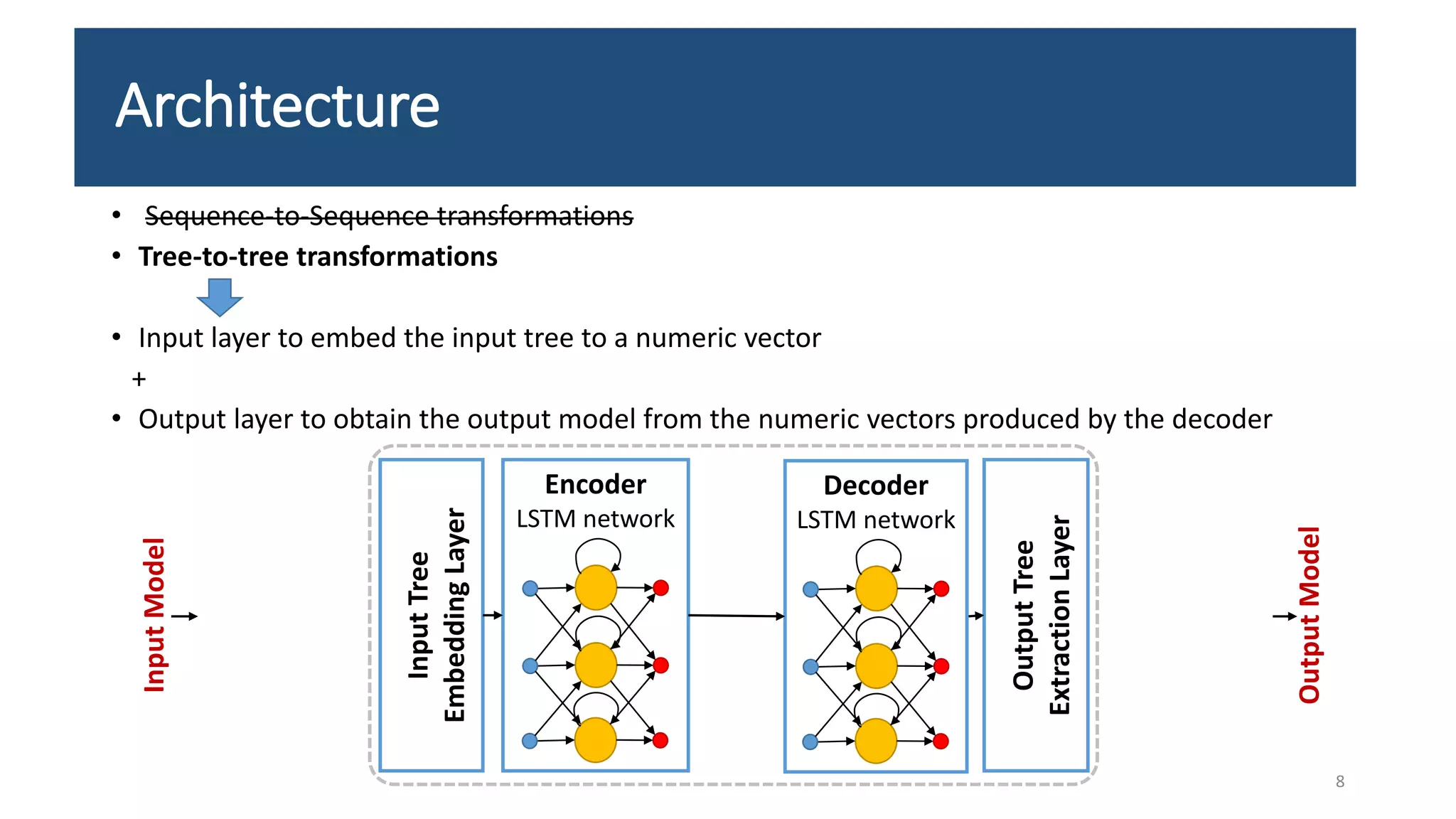
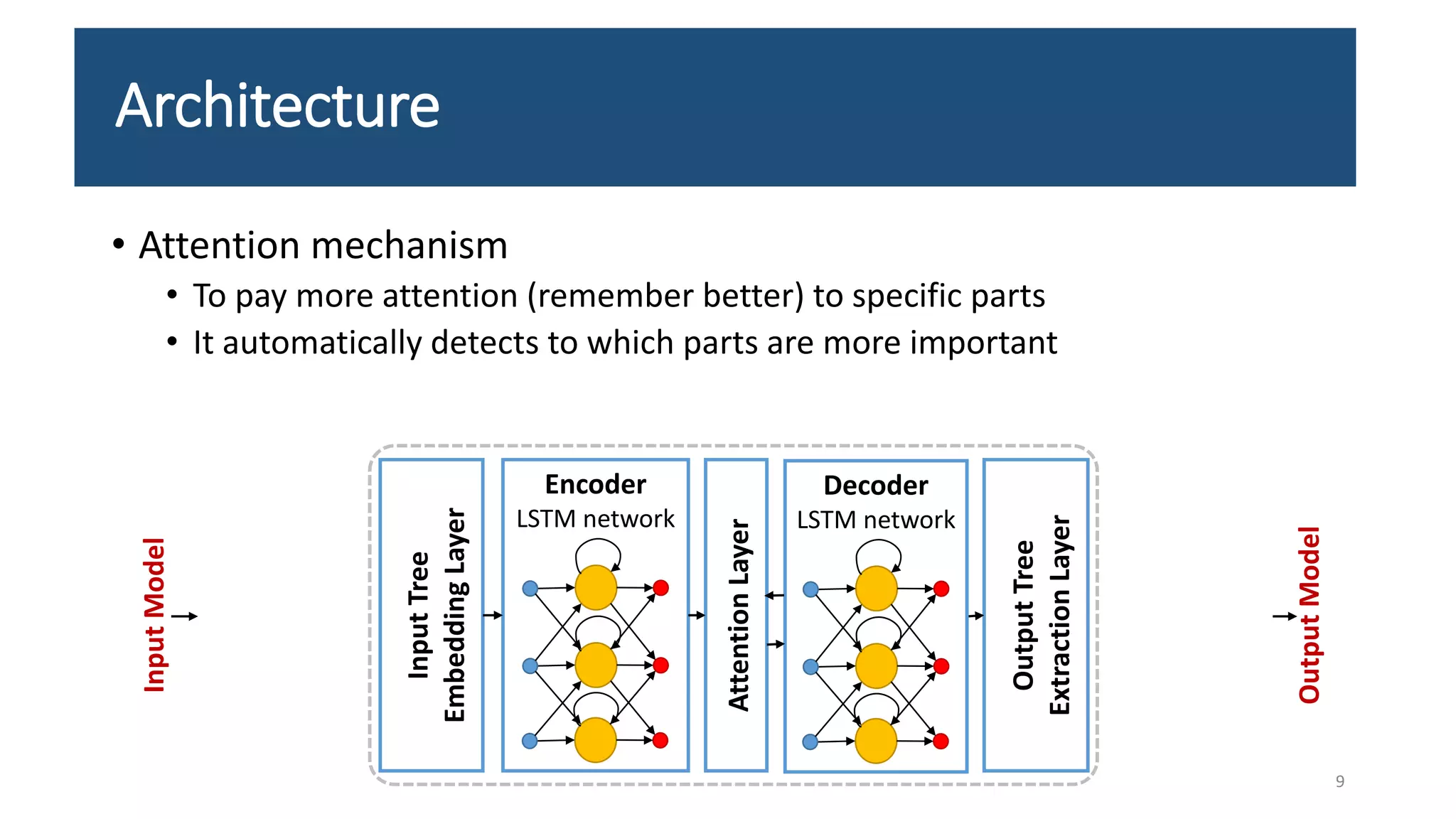
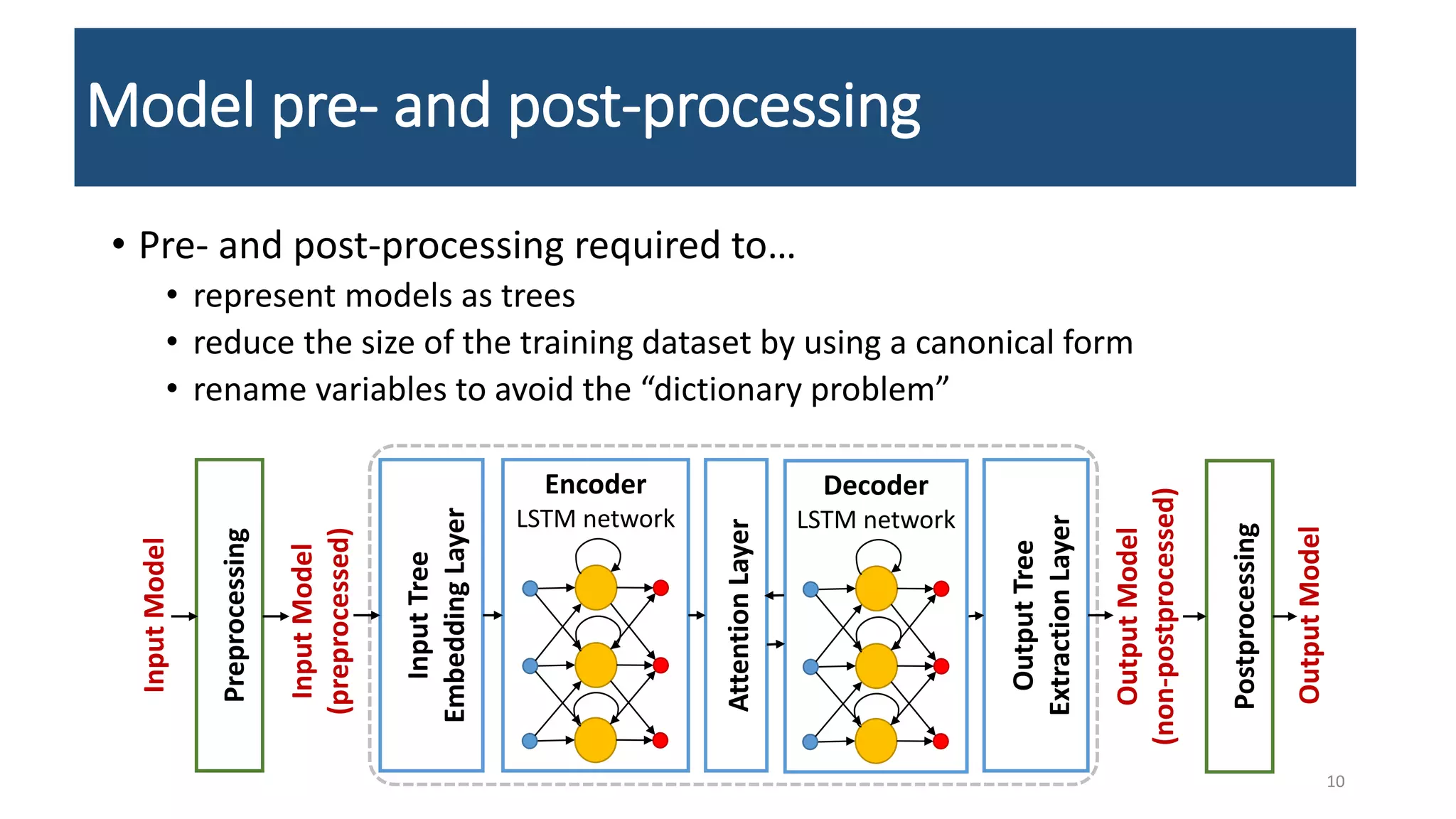
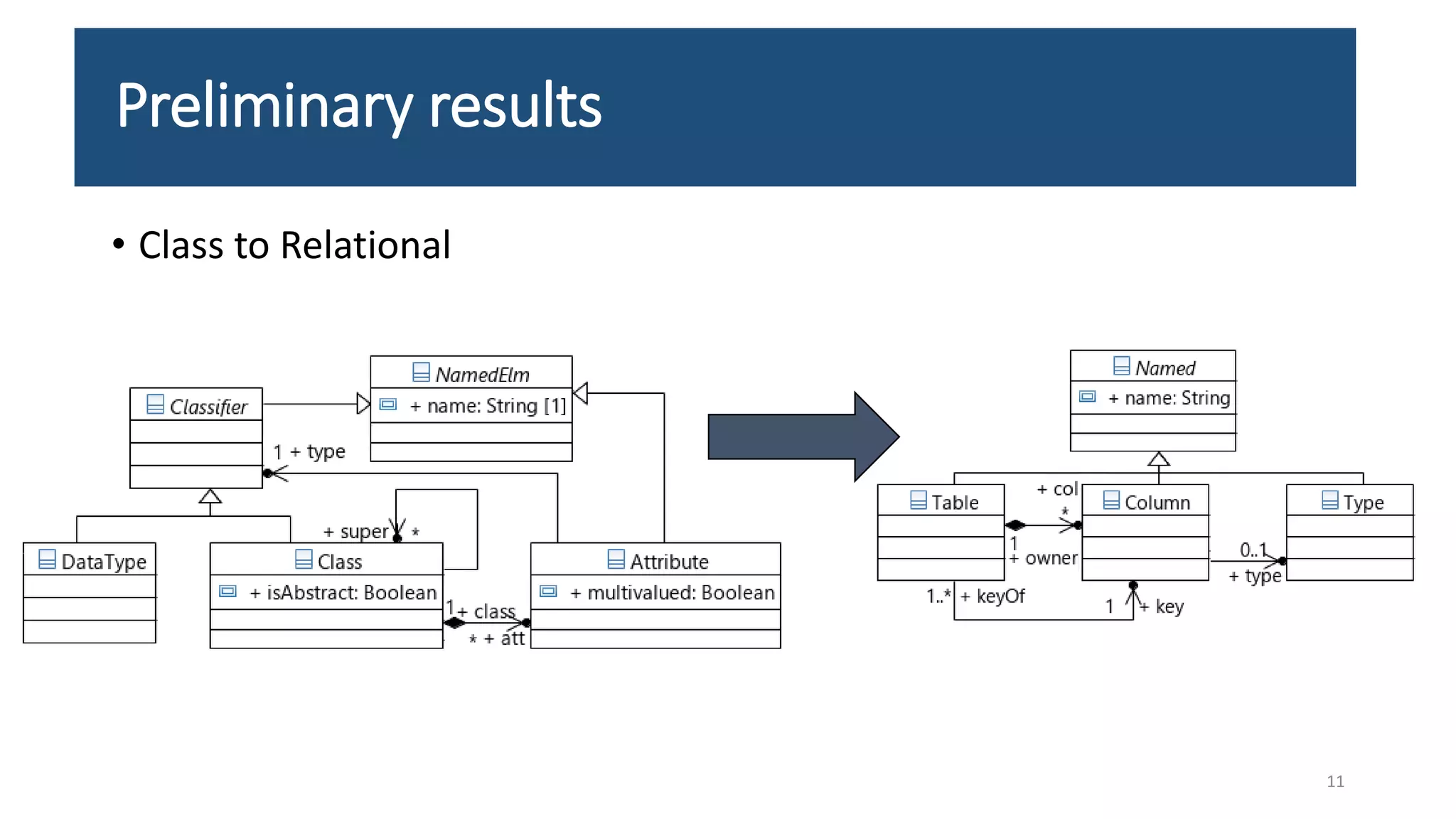
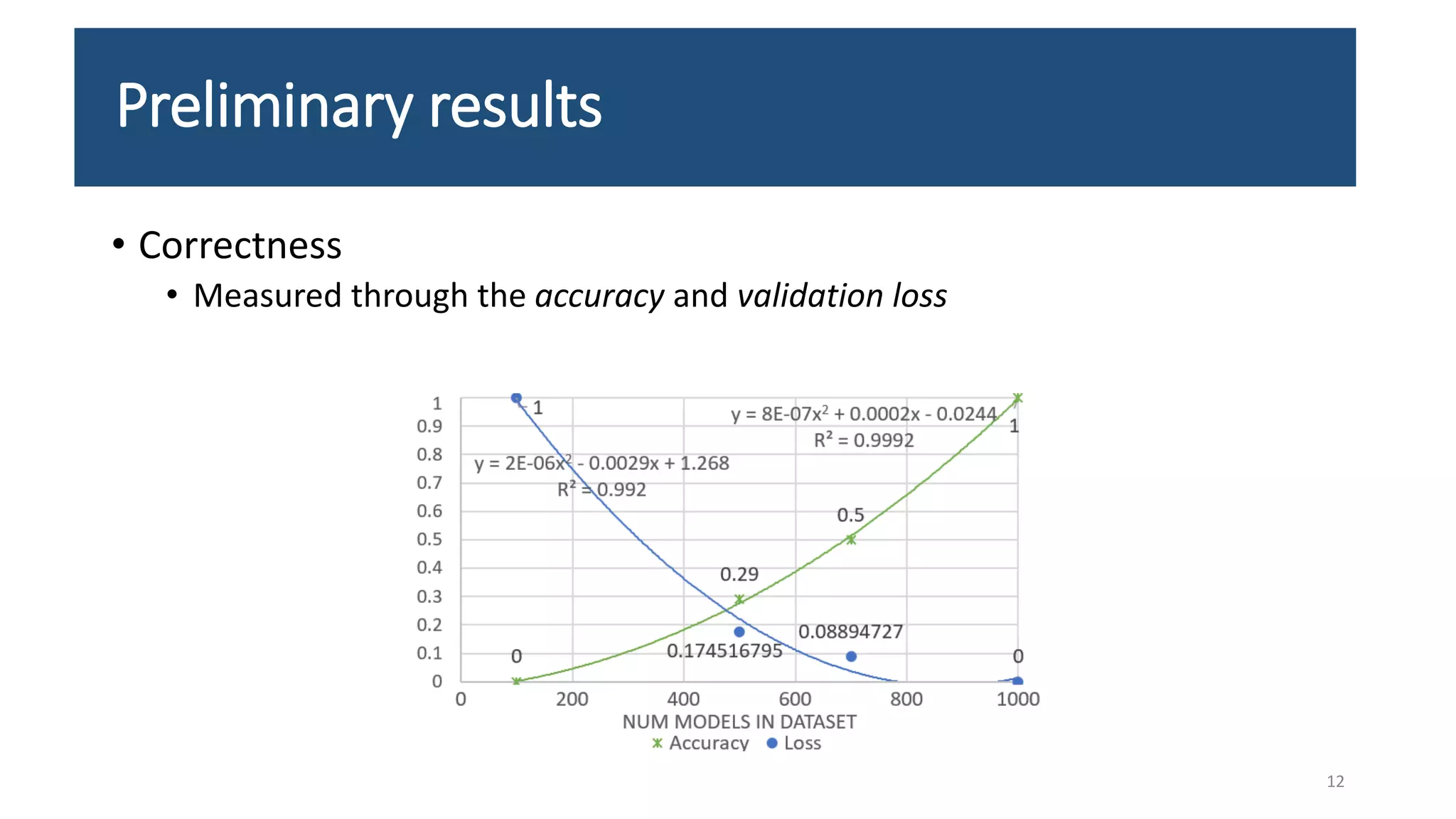
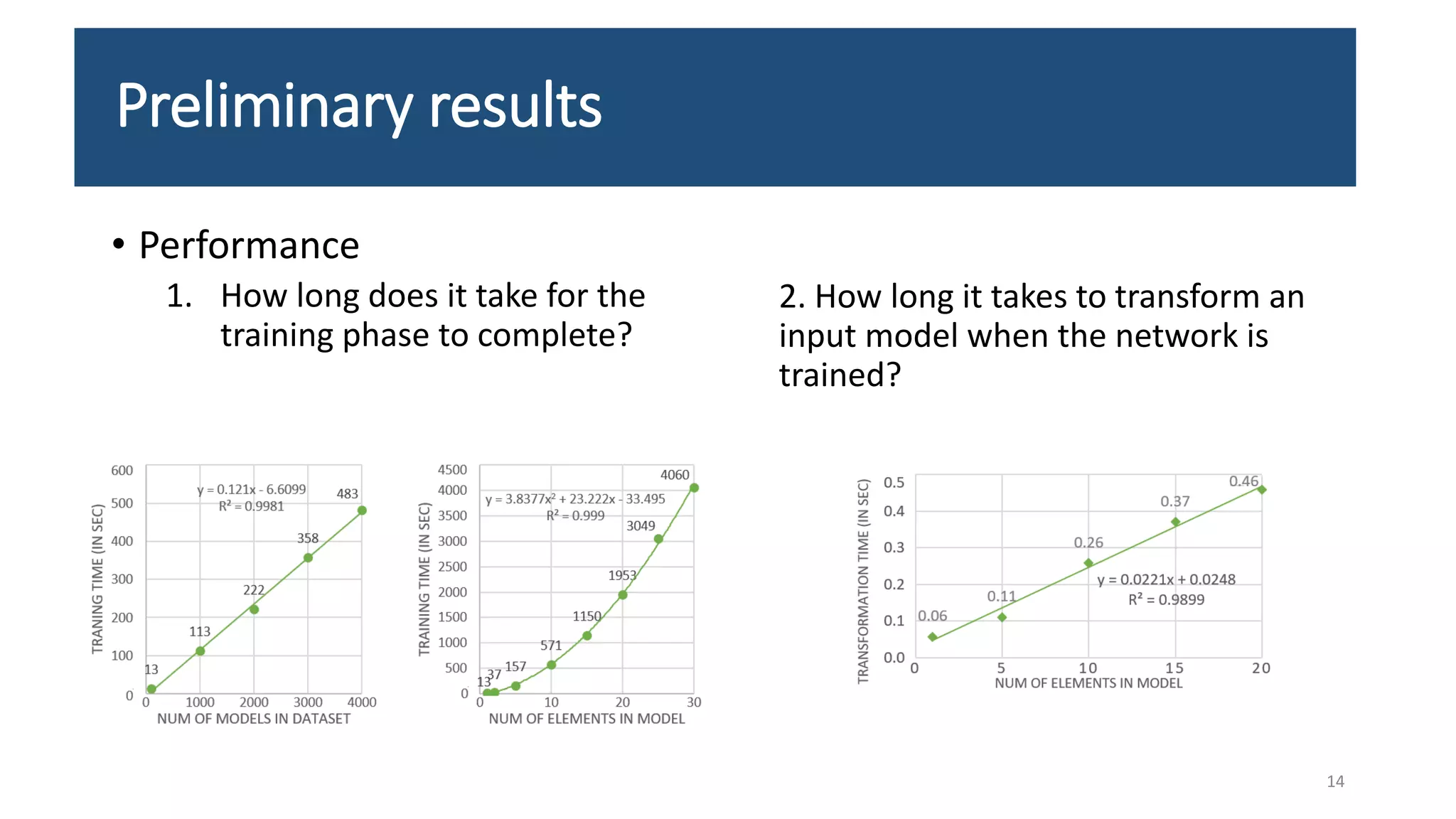
The document presents an LSTM-based neural network architecture designed for model transformations, utilizing an encoder-decoder structure combined with attention mechanisms to enhance performance. It discusses the preprocessing and post-processing of model data to improve training efficacy, as well as preliminary results on correctness and performance metrics. Limitations such as the size and diversity of the training dataset, computational constraints, and generalization challenges are also addressed.

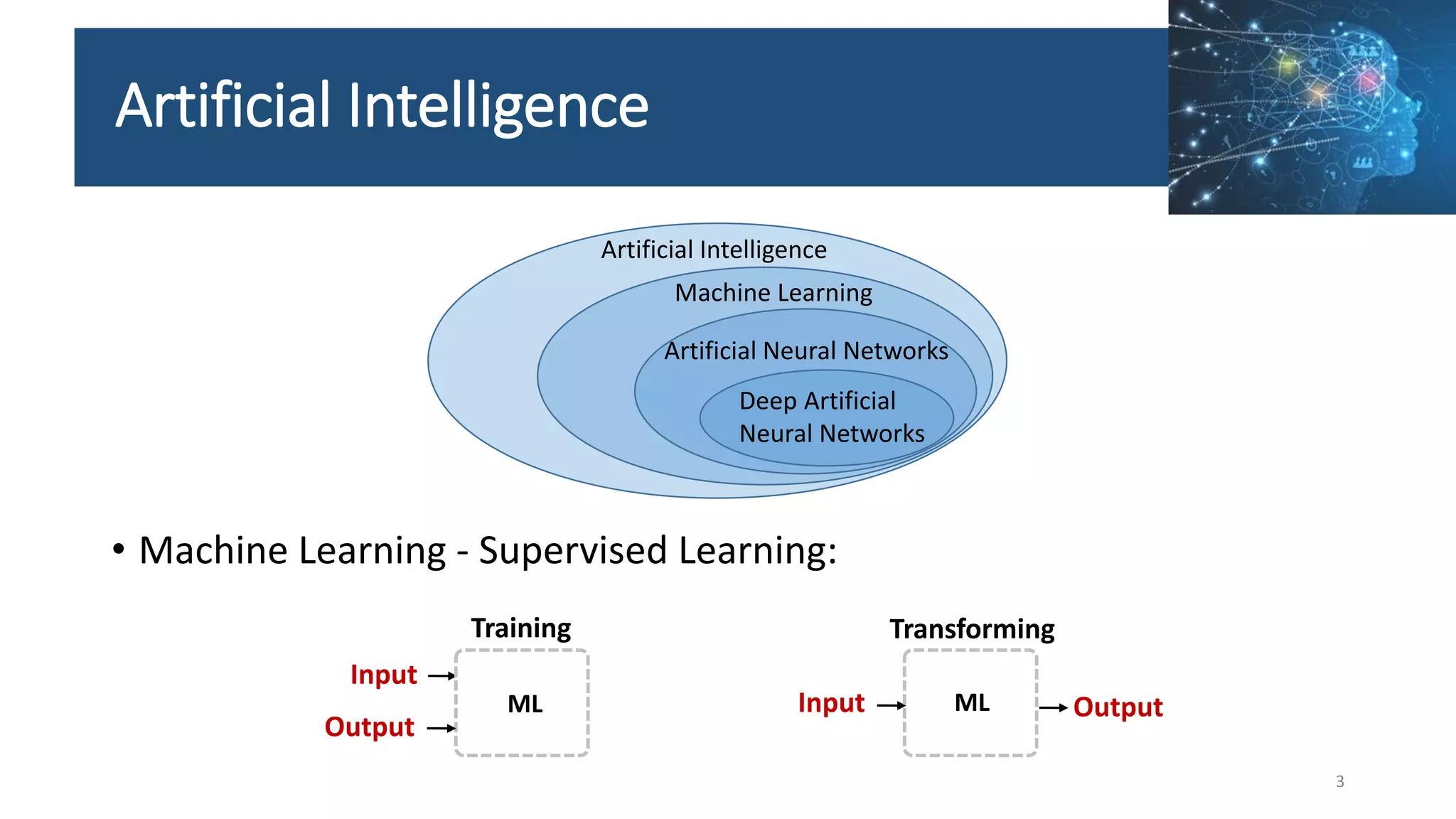
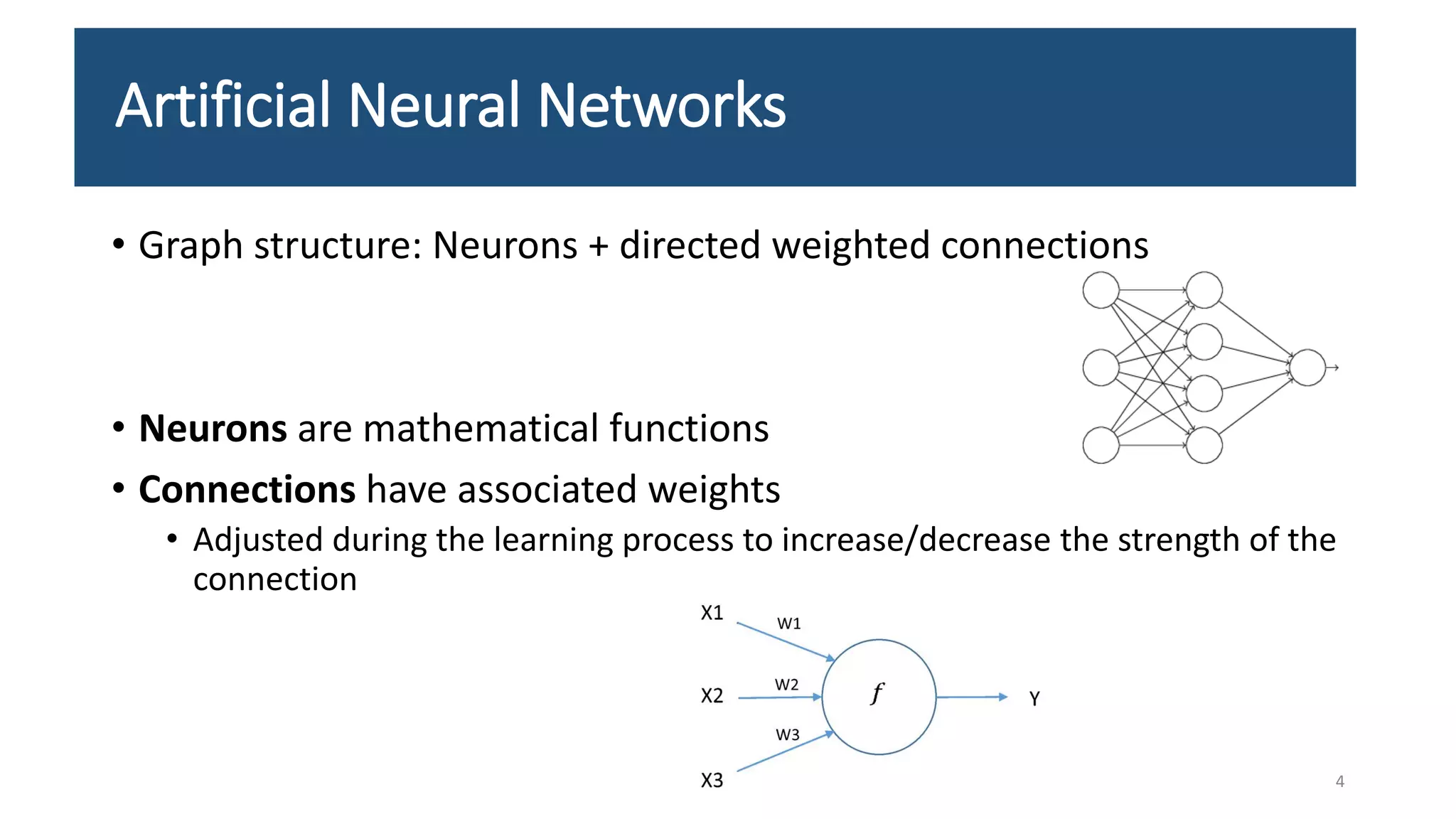
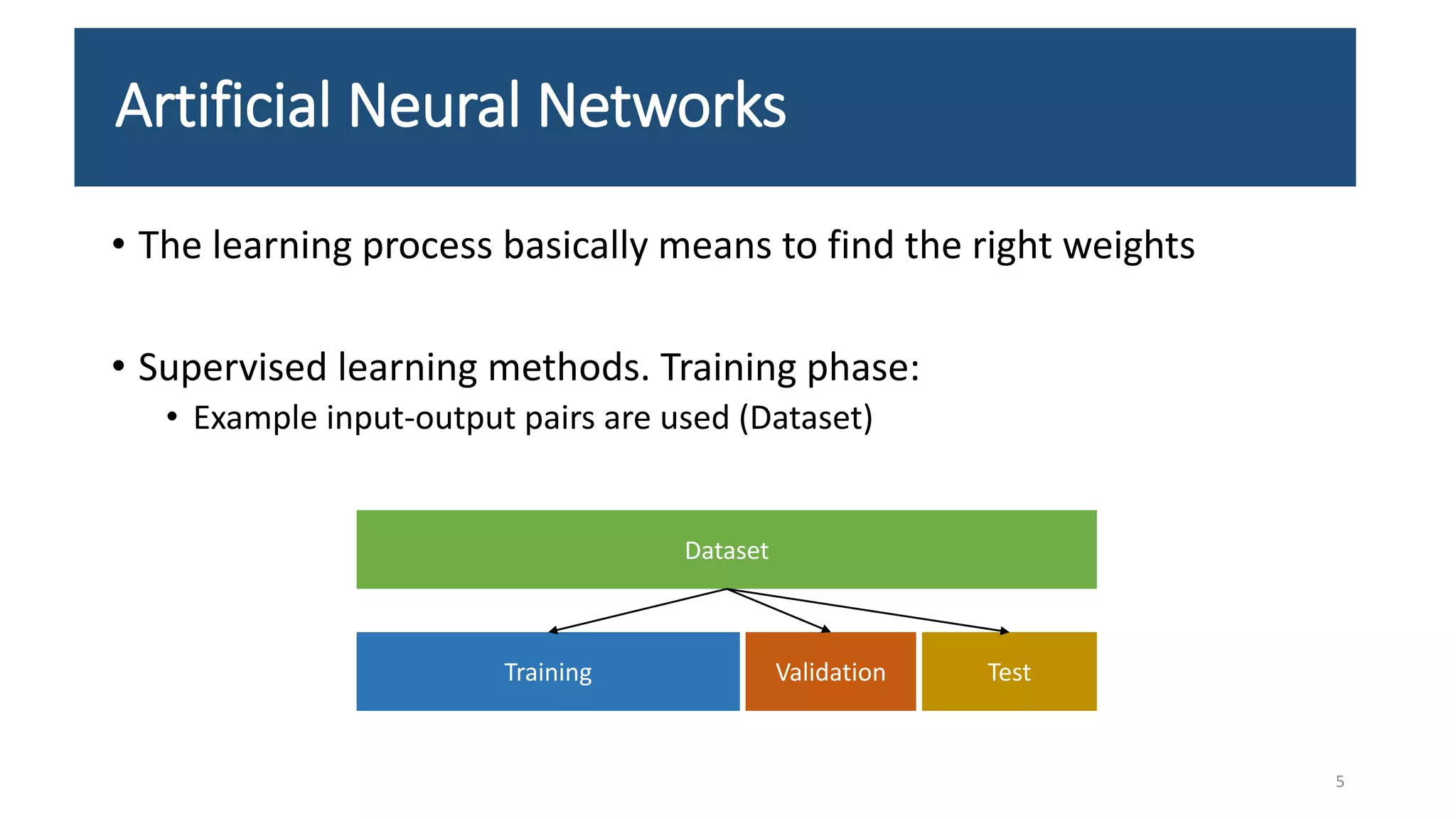
























![[5] Understanding the YOLOv8 Architecture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/5understandingtheyolov8architecture-240724131844-70710c0c-thumbnail.jpg?width=640&height=640&fit=bounds)