Downloaded 354 times















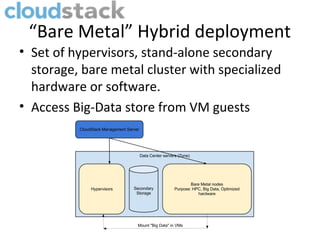



























The document presents a discussion on the relationship between CloudStack and big data, highlighting the decline of cloud computing trends and the rise of big data technologies. It details how CloudStack functions as an open-source IaaS solution, its history, and its capabilities in orchestrating data centers for big data environments. Additionally, it introduces various tools like Apache Whirr for deploying big data solutions and emphasizes the ongoing development opportunities within the CloudStack and big data ecosystem.















































![Big data application using hadoop in cloud [Smart Refrigerator]](https://cdn.slidesharecdn.com/ss_thumbnails/pushkarbhandari-160107183520-thumbnail.jpg?width=640&height=640&fit=bounds)







































