Downloaded 46 times









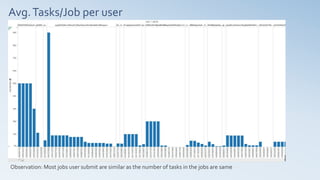














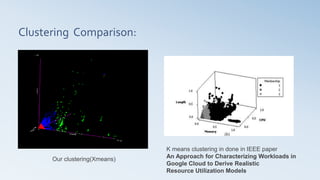
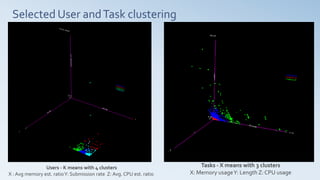









This document summarizes the analysis of a cloud computing workload dataset. Key findings include: 1) Users were categorized into 4 clusters based on submission rate and resource estimation ratios. 2) Tasks were clustered into 3 groups using memory usage, length, and CPU usage. 3) Time series analysis using dynamic time warping identified tasks with similar workloads within predictable user clusters. 4) Workload prediction models were developed to determine step changes in resource allocation based on reference workload curves for predictable users and tasks.