Download to read offline





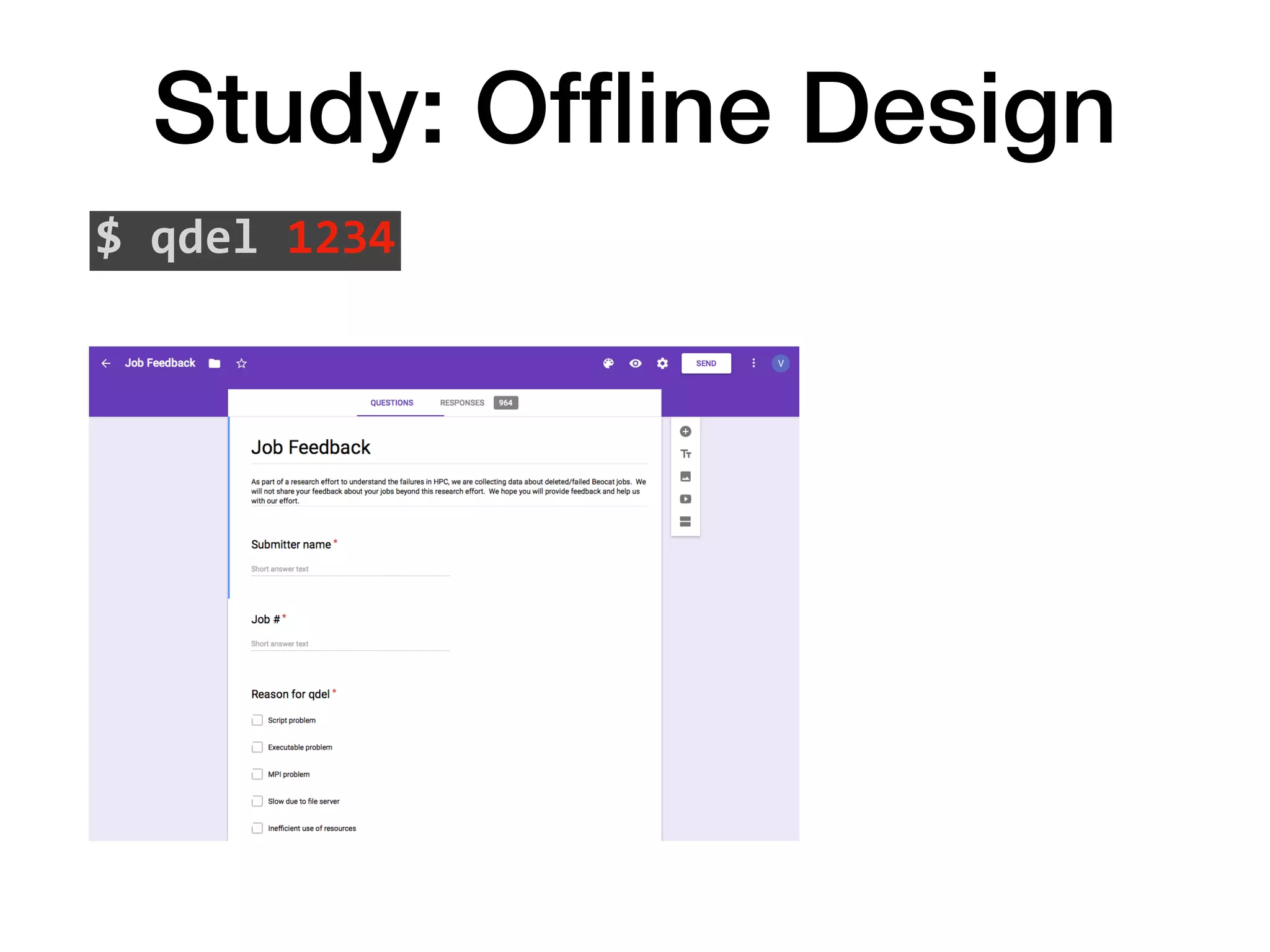
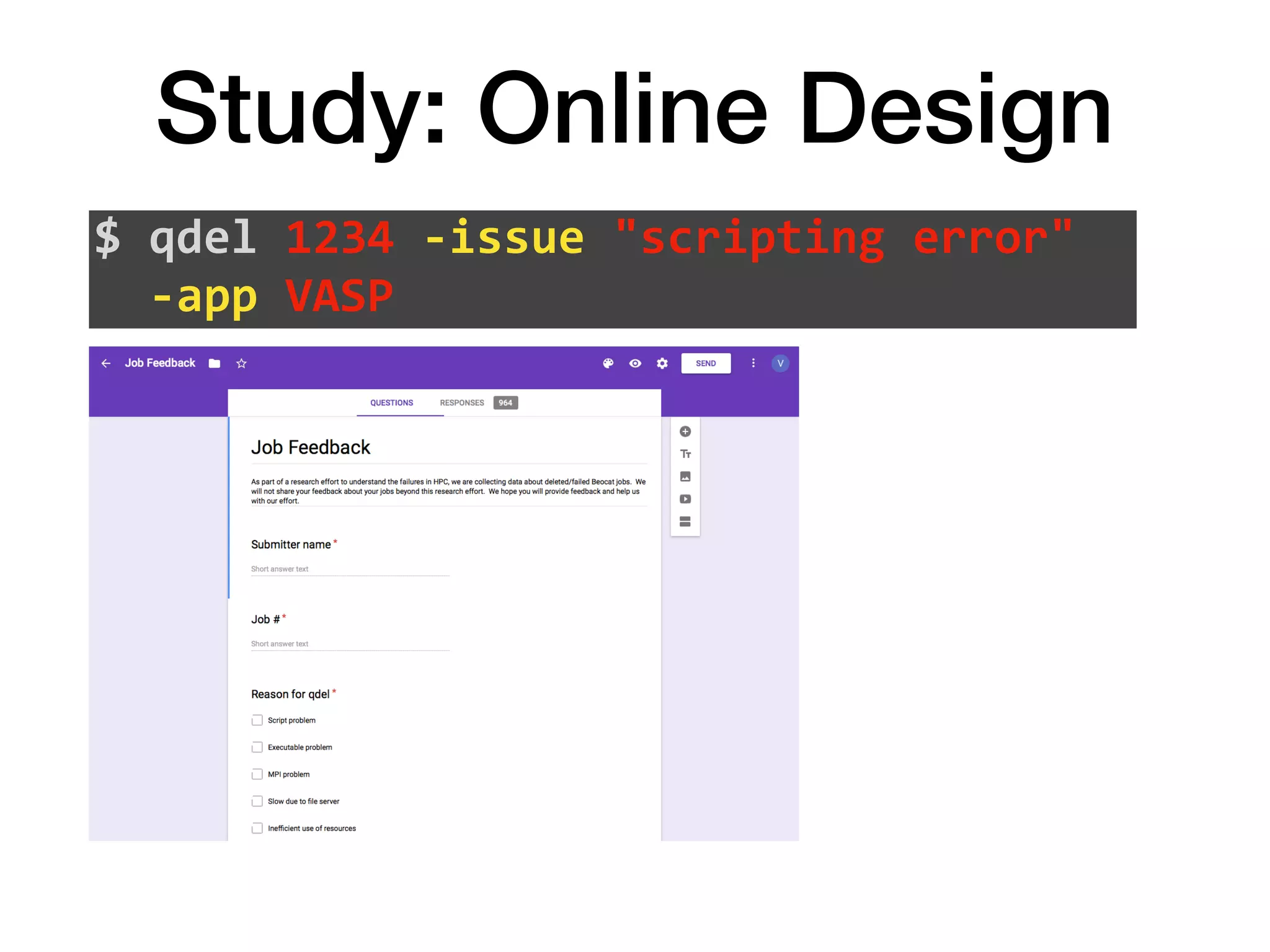


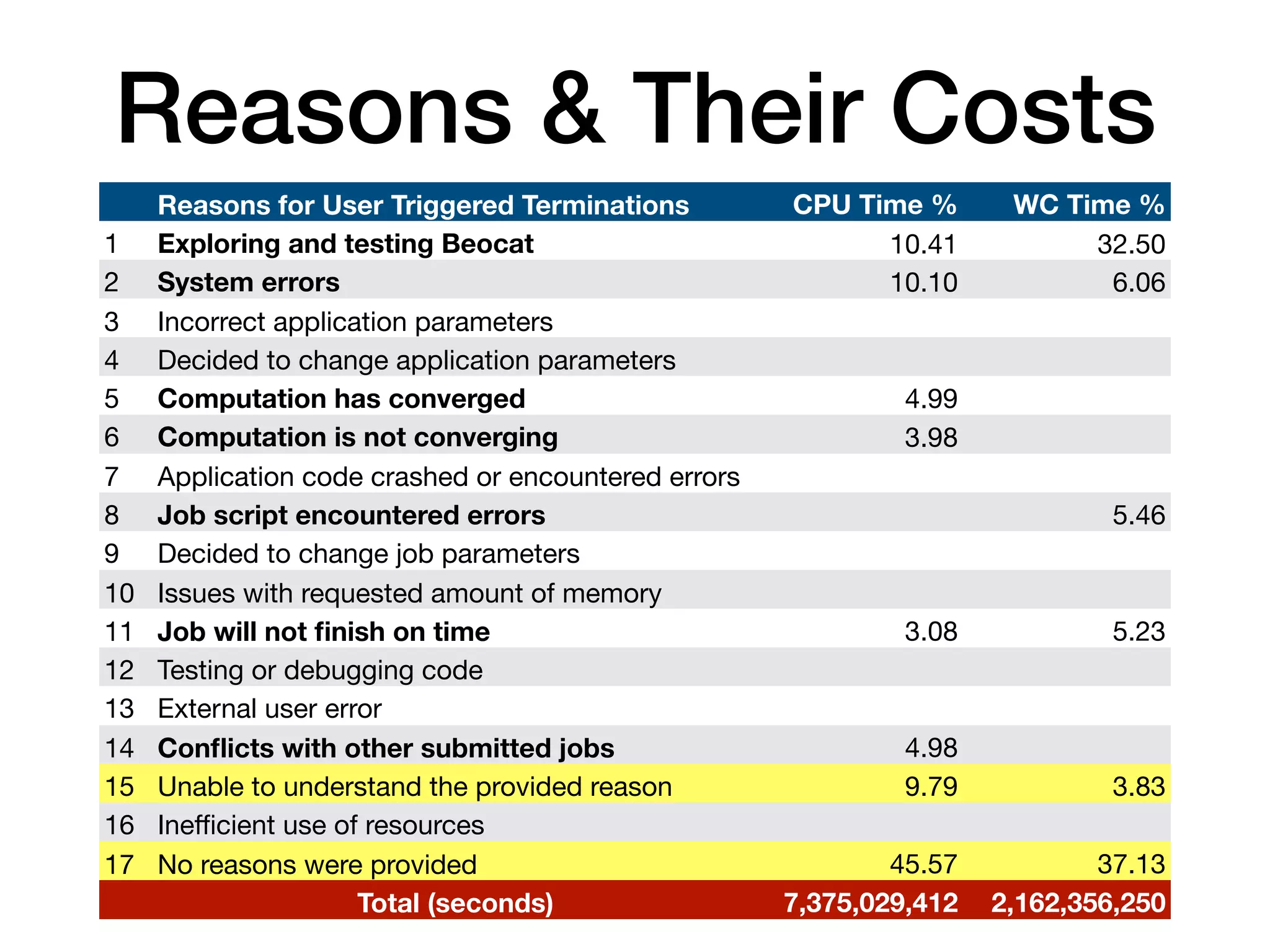


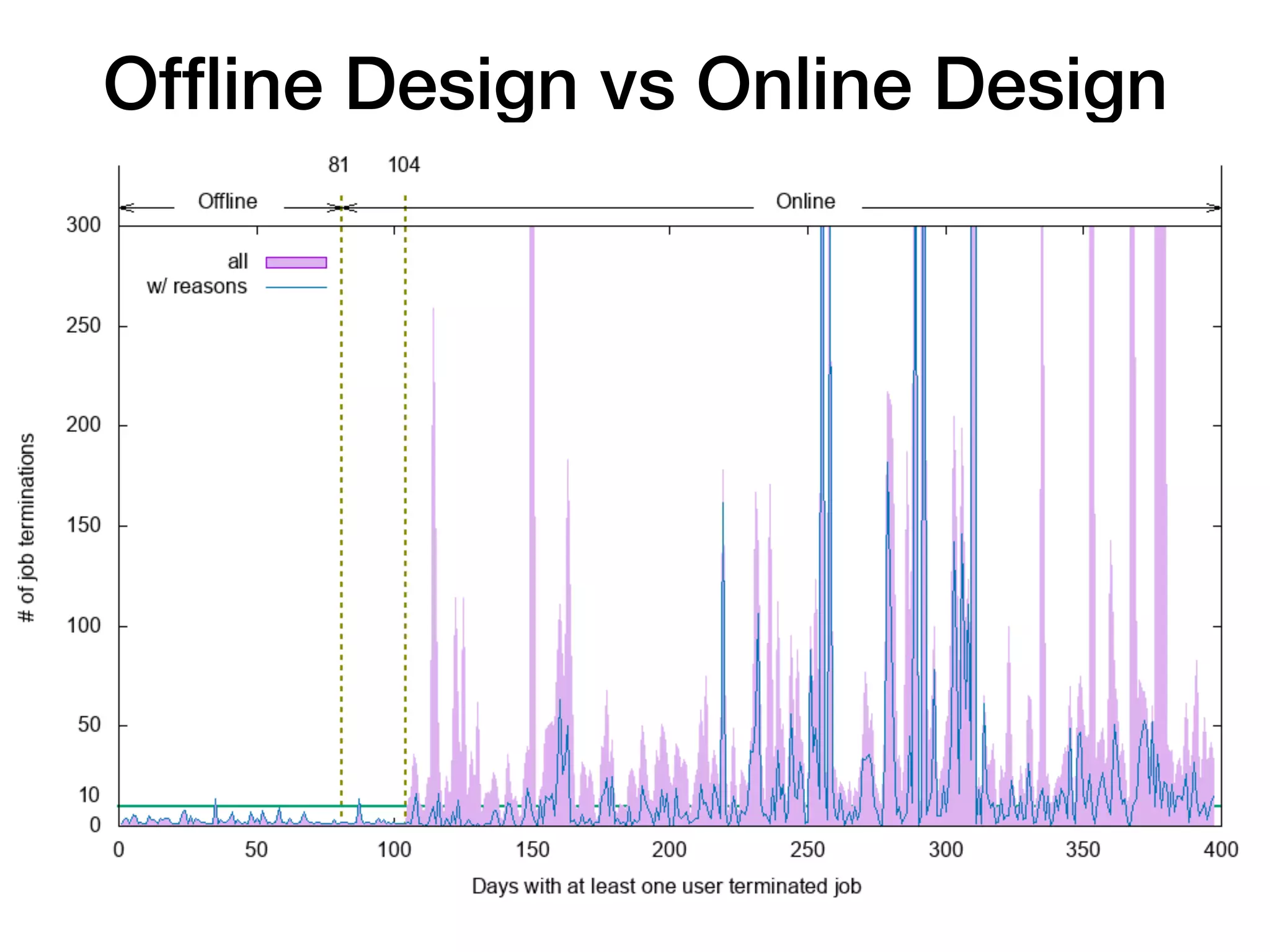



The document discusses a study conducted on the Beocat HPC cluster at Kansas State University to understand why users terminate jobs early. The study found that user terminated jobs accounted for around 10% of total CPU time and 12.75% of user wait time, representing significant wasted resources. The top reasons for job termination included exploring the system, system errors, jobs not finishing on time, and jobs converging or not converging earlier than expected. The study suggests ways to address the top reasons and reduce wastage through techniques like improving system reliability, helping users estimate job runtimes better, and automating convergence detection. Repeating such studies on other clusters could help understand wastage in different HPC environments.

















![Testing concepts [3] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/testing-concepts-170926174731-thumbnail.jpg?width=640&height=640&fit=bounds)

![Code Coverage [9] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/code-coverage-170926180427-thumbnail.jpg?width=640&height=640&fit=bounds)
![Boundary Value Testing [7] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/boundary-value-testing-170926175738-thumbnail.jpg?width=640&height=640&fit=bounds)
![Equivalence Class Testing [8] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/equivalence-class-testing-170926175813-thumbnail.jpg?width=640&height=640&fit=bounds)





![Behavior Driven Development [10] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/bdd-170926180601-thumbnail.jpg?width=640&height=640&fit=bounds)

![Introduction [1] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/introduction-170926174323-thumbnail.jpg?width=640&height=640&fit=bounds)
![Unit testing [4] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/unit-testing-170926175035-thumbnail.jpg?width=640&height=640&fit=bounds)

![Intro to Python3 [2] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/intro-to-python3-170926175135-thumbnail.jpg?width=640&height=640&fit=bounds)
![Property Based Testing [5] - Software Testing Techniques (CIS640)](https://cdn.slidesharecdn.com/ss_thumbnails/property-based-testing-170926175312-thumbnail.jpg?width=640&height=640&fit=bounds)



















