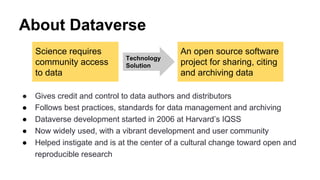
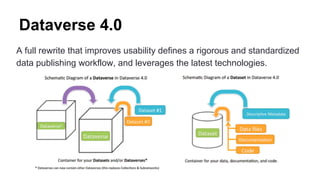
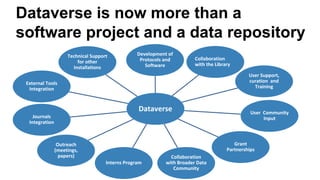
Dataverse is an open-source platform developed at Harvard for sharing, citing, and archiving research data, with a focus on creating a culture of open and reproducible science. It features enhanced usability, a standardized data publishing workflow, and supports a wide range of metadata and access control options. The platform has seen significant growth in usage, with over 1000 dataverses and 58,000 datasets shared globally, alongside ongoing collaborations to integrate various tools and support new data types.