Downloaded 68 times





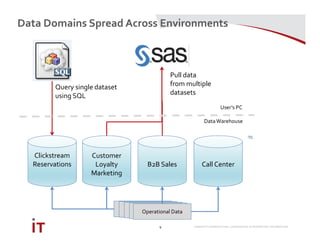

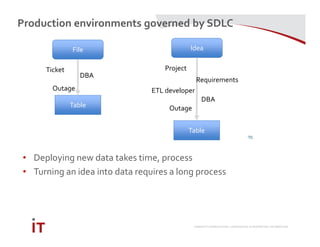


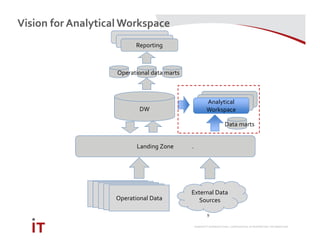

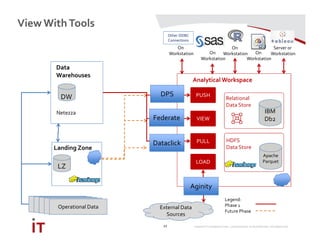


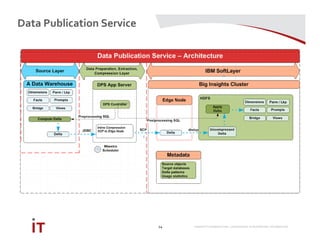

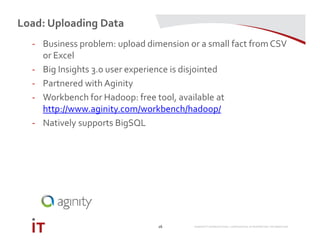
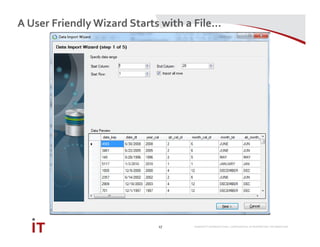
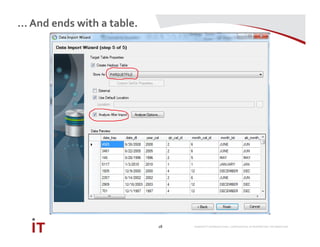
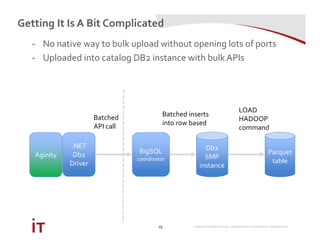


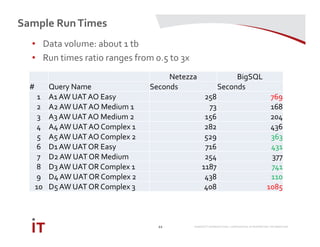








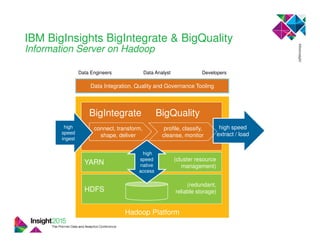
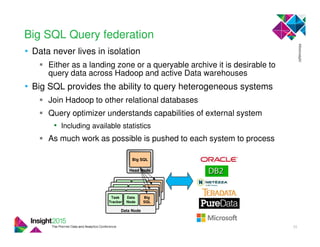








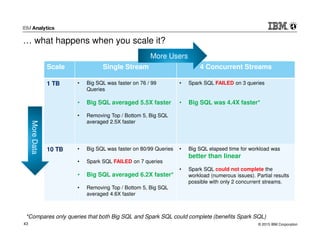
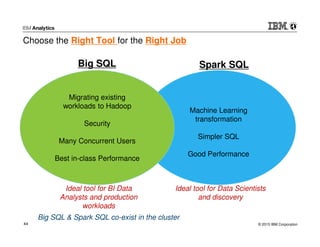





This document discusses Marriott International's journey to implementing a cloud-based data warehouse and analytics platform using IBM BigSQL on Softlayer cloud infrastructure. It describes the limitations of their existing on-premises system, challenges faced in migrating data and queries to the cloud, lessons learned, and next steps to further improve the platform. The system is now in production use by an initial group of users at Marriott.

















![Kb 40 kevin_klineukug_reading20070717[1]](https://cdn.slidesharecdn.com/ss_thumbnails/kb40kevinklineukugreading200707171-101026100915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


































































