Downloaded 24 times






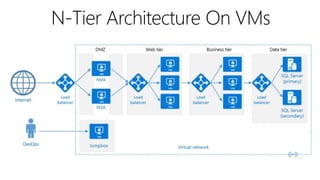
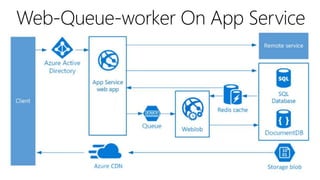
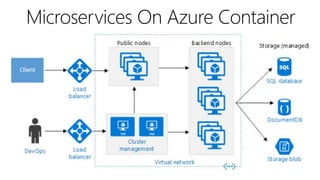
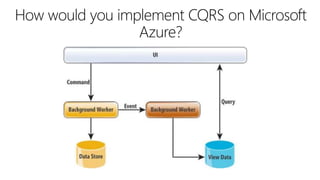
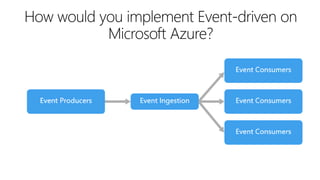
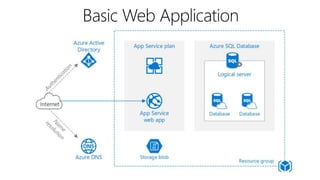
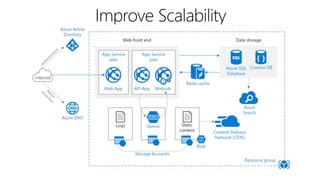
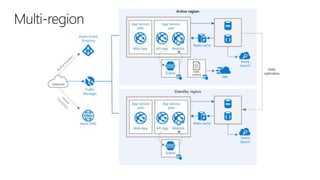
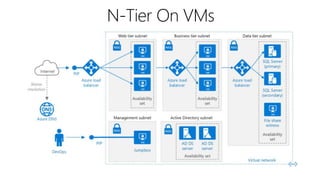






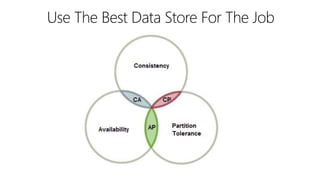



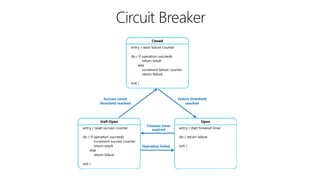
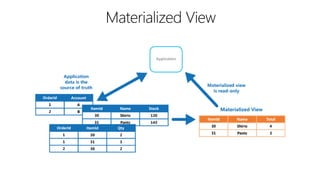
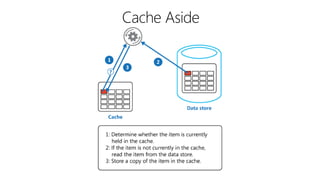


This document outlines key concepts for cloud architecture patterns including microservices, CQRS, and event-driven architectures. It discusses technology choices for compute, data storage, and design principles for quality like scalability, availability, and resiliency. Common patterns are described like retrying operations, circuit breakers, and load balancing to improve reliability.









































































