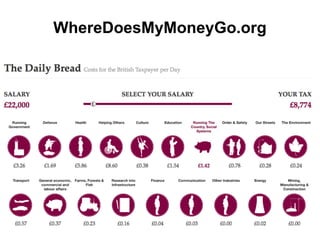
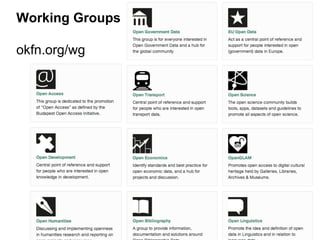
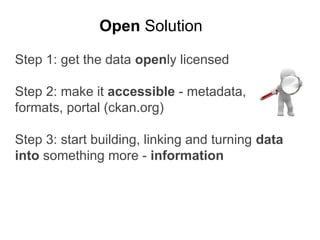
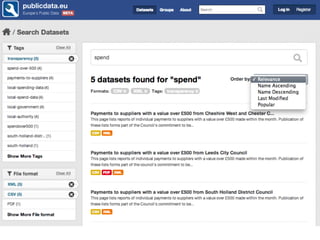
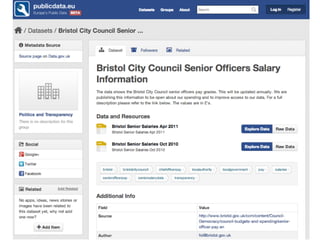
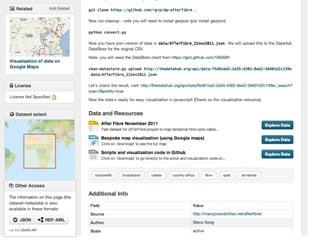
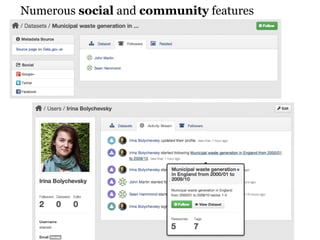
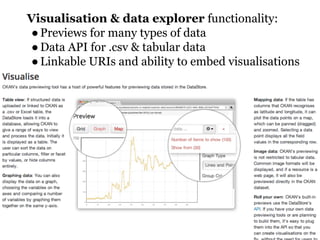
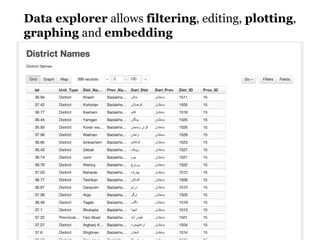
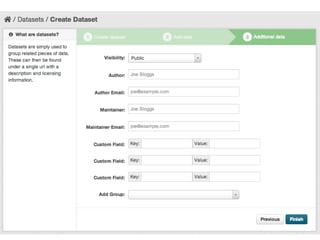
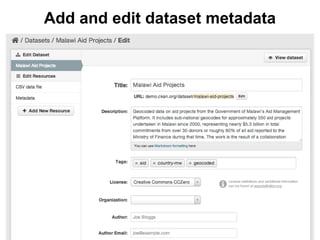
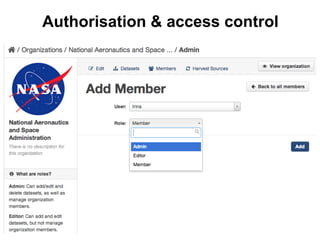
CKAN is an open-source software developed by the Open Knowledge Foundation for managing and discovering open data. It provides tools for data management and user-friendly features for searching and visualizing datasets, supporting various formats and multilingual content. The platform aims to improve governance and data utilization through accessible, openly licensed information across the globe.









































![Análisis de Datos SEO para el QUÉ y el CÚANDO [SOB 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/analisis-de-datos-seo-que-cuando-sob18-180616213753-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)













