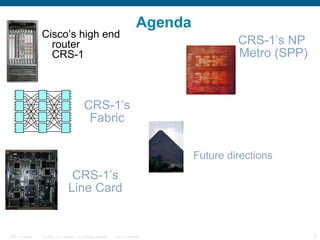
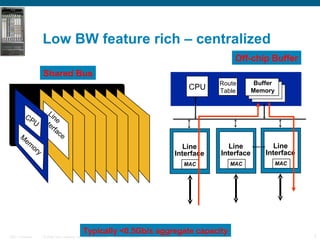
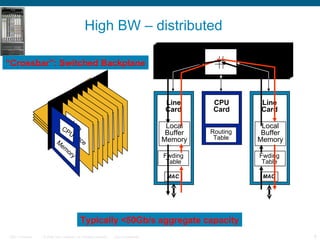
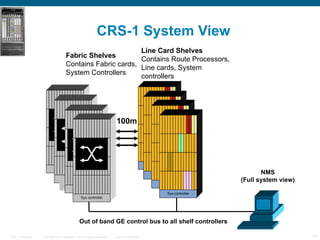
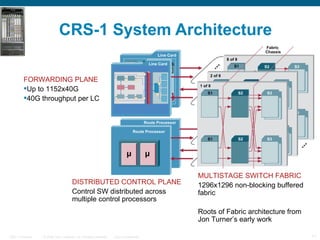
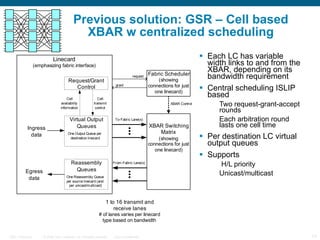
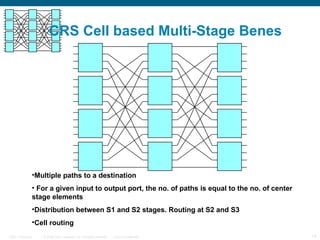
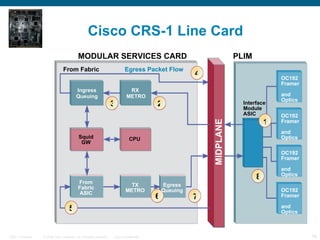
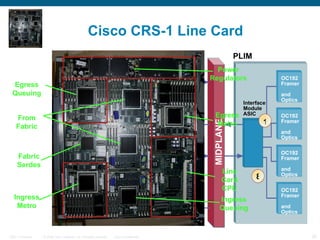
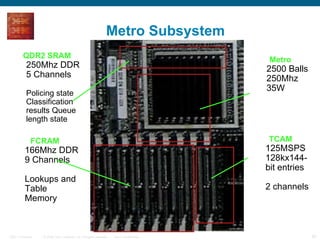
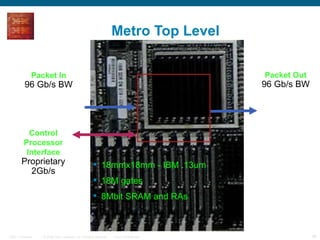
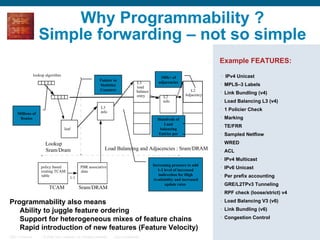
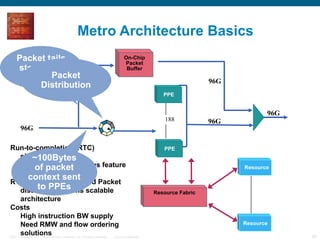
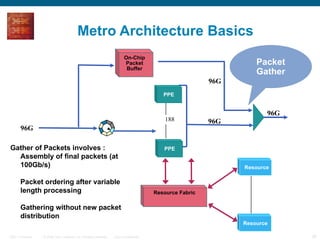
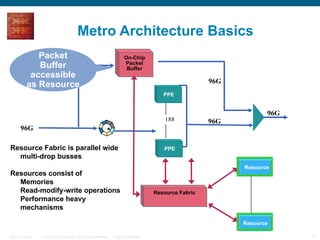
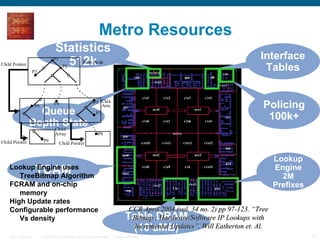
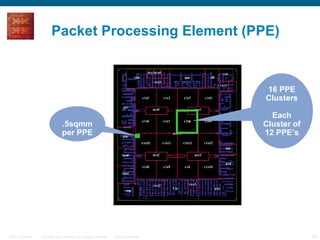
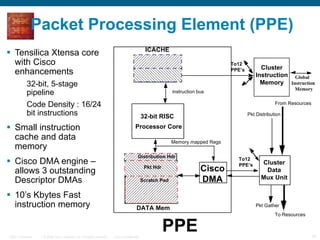
The document provides an overview of the Cisco CRS-1 router. It discusses the router's distributed architecture with multiple line cards and a high-speed fabric. The fabric uses a multi-stage Benes switch design to provide multiple paths between cards. Each line card contains specialized silicon that can process packets at wire speed through independent packet processing engines. The router is designed to scale routing capacity and features through this distributed and programmable hardware architecture.
























![Networks planes Networks are considered to have three planes / operating timescales Data : packet forwarding [μs, ns] Control : flows/connections [ ms, secs] Management : aggregates, networks [ secs, hours ] Planes coupling is in descendent order (control-data more, management-control less)](https://image.slidesharecdn.com/ciscocrs1-100507102836-phpapp02/85/Cisco-crs1-42-320.jpg)


















![[OpenInfra Days Korea 2018] (Track 2) Neutron LBaaS 어디까지 왔니? - Octavia 소개](https://cdn.slidesharecdn.com/ss_thumbnails/26octavia-180704054917-thumbnail.jpg?width=640&height=640&fit=bounds)

















































