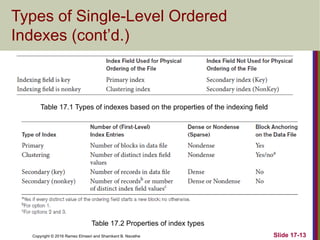
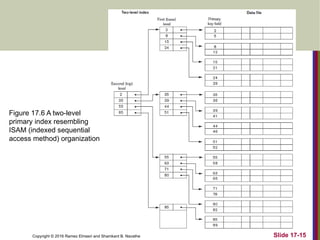
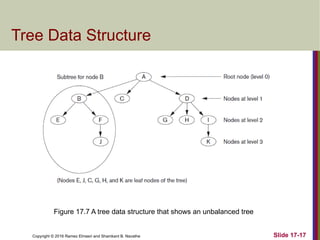
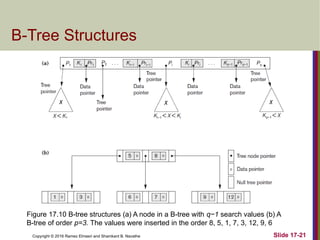
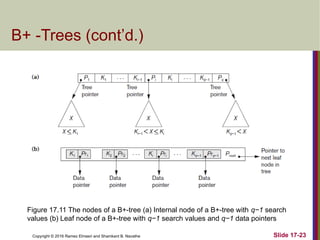
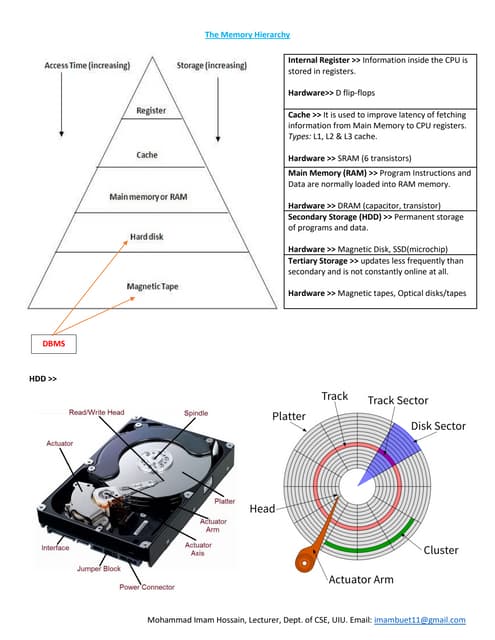
The document discusses indexing structures for files and physical database design, highlighting the importance of indexes for efficient record retrieval. It covers various types of indexes, including primary, clustering, and secondary indexes, as well as more complex structures like multilevel indexes based on b-trees and b+-trees. Additionally, it addresses considerations for physical database design, such as indexing strategies and the impact of update operations on index performance.