This chapter discusses various data structures including elementary data structures like stacks, queues, linked lists, binary trees, and hash tables. It then describes more complex data structures like red-black trees that balance binary search trees to guarantee logarithmic time operations. It also discusses augmenting data structures by adding size fields to support dynamic order statistics queries in logarithmic time.





![Stacks
• INSERT operation on a stack PUSH
• DELETE operation POP.
• top[S] that indexes the most recently inserted
element.
• The stack consists of elements S[1..top[S]], where
S[1] is the element at the bottom of the stack and
S[top[S]] is the element at the top.
• When top [S] = 0, the stack contains no elements
and is empty
• If an empty stack is popped, stack underflows,
which is normally an error.
• If top[S] exceeds n, the stack overflows.](https://image.slidesharecdn.com/chapter4-230317140923-9a6cea92/85/Chapter-4-pptx-5-320.jpg)





![What is a Hash Table ?
Each record has a special
field, called its key.
In this example, the key is a
long integer field called
Number.
[ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ]
. . .
[ 700]
[ 4 ]
Number 506643548
Each record has a special
field, called its key.
In this example, the key is a
long integer field called
Number.
Each record has a special
field, called its key.
In this example, the key is a
long integer field called
Number.](https://image.slidesharecdn.com/chapter4-230317140923-9a6cea92/85/Chapter-4-pptx-13-320.jpg)
![Collisions
This is called a collision,
because there is already
another valid record at [2].
[ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Number 506643548
Number 233667136
Number 281942902
Number 155778322
. . .
Number 580625685
Number 701466868
When a collision
occurs,
move forward until you
find an empty spot.](https://image.slidesharecdn.com/chapter4-230317140923-9a6cea92/85/Chapter-4-pptx-14-320.jpg)








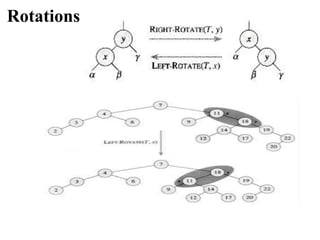
![AUGMENTING DATA STRUCTURES
It introduced the notion of Dynamic order
statistics
size[x] = size[left[x]] + size[right[x]] + 1 .](https://image.slidesharecdn.com/chapter4-230317140923-9a6cea92/85/Chapter-4-pptx-26-320.jpg)



































































