Chapter 1: NumericalMethods, Number
Systems, and Error Analysis
Prepared by: Wendwsen B.
Dire Dawa University Institute of Technology
Collage of Electrical and Computer Engineering
ECEG3041 Computational Methods
2.
1.1 Introduction
Significant digits: Are important in showing the truth
one has in a reported number. Significant digits indicate
the accuracy and reliability of a reported number.
Precision and accuracy:
Accuracy: refers to how a closely computed value or
measured value agrees with the true value.
Precision: refers to how closely individual computed or
measured values agree with each other.
3.
Example 1:
•Statement: “Thepopulation is 1 million.”
•Only 1 significant digit (the "1").
•Accuracy is very rough.
Example 2:
•Actual count: 1,079,587
•7 significant digits → much higher accuracy.
4.
Numerical methods shouldbe sufficiently accurate to
meet the requirements of a particular engineering
problem. They also should be precise enough for
adequate engineering design. The collective term error
represents both the inaccuracy and imprecision of our
predictions in the following lessons.
5.
1.2 Sources ofError
Error in solving an engineering or science problem can arise due to several
factors. First, the error may be in the modeling technique. A mathematical model
may be based on using assumptions that are not acceptable. For example, one
may assume that the drag force on a car is proportional to the velocity of the car,
but actually it is proportional to the square of the velocity of the car. This itself
can create huge errors in determining the performance of the car, no matter how
accurate the numerical methods you may use.
6.
Second, errors mayarise from mistakes in programs themselves or in the
measurement of physical quantities. But, in application of numerical methods
itself, the two errors we need to focus on are:
Round off error and,
Truncation error
7.
A computer canonly represent a number approximately because there is no
mechanism to deal with infiniteness in computers. For example, a number like
1/3 may be represented as 0.333333 on a PC. Then, the round off error
generated in this case is
1/3-0.333333=0.00000033
There are other numbers that cannot be represented exactly. For example, π
and are numbers that need to be approximated in computer calculations.
1.2.1. Round of Error
8.
1.2.2. Truncation Error
Truncationerror is defined as the error caused by truncating a mathematical
procedure. For example, the Maclaurin series for is given as
This series has an infinite number of terms but when using this series to
calculate only a finite number of terms can be used on iteration. For example,
if one uses three terms in his calculation, then the resulting truncation error
becomes
2 3
x x x
e 1 x ...
2! 3!
3
2 4
x x x
x
Trunction Error=e -[1+x+ ]= + ...
2! 3! 4!
9.
Clearly, we cannotavoid truncation errors. The question should rather be how we can control
truncation errors. We can use the concept of relative approximation in order to control this. For
the time being let us assume that this could be achieved by setting a particular acceptable error
magnitude and decide for the minimum number of terms involved in our calculation. With this
assumption in mind one can finally conclude that increasing the number of terms would decrease
truncation error.
The total numerical error is the summation of truncation error and round off error. We can
minimize round off errors by increasing the number of significant digits. In contrast to this,
Subtractive cancellation 1 and increase in the number of computations (i.e number of terms
involved) will intensify round off errors.
10.
Truncation error onthe other hand could be reduced with decreasing the step
size which in turn could increase subtractive cancelation or increase in
computations.
All of the above statements are simply would mean that truncation error
increases as round off errors are increased which that means we are forced to
trade off between the two errors in finding the suitable step size for a particular
computation.
11.
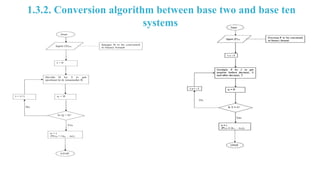
1.3 Number Representationand Conversion Algorithm
The basic unit of memory is the binary digit, called a bit. A bit may contain a 0 or a l. It is the
simplest possible unit.
People often say that computers use binary arithmetic because it is "efficient." What they mean
(although they rarely realize it) is that digital information can be stored by distinguishing
between different values of some continuous physical quantity, such as voltage or current. The
more values that must be distinguished, the lesser is the separation between adjacent values,
and the less reliable the memory we would have.
The binary number system requires only two values to be distinguished. Consequently, it is the
most reliable method for encoding digital information.
12.
In everyday life,we use a number system with a base of 10, simply because we have ten fingers!
For example, look at the number 257.56. Each digit in 257.56 has a value of 0 through 9 and has
a place value. It can be written as
257 . 65=2 ×102
+5 ×101
+7 × 100
+5 ×10−1
+6 × 10−2
In a binary system, we have a similar system where the base is made of only two digits 0 and 1.
So it is a base 2 system. A number like (1011.0011) in base-2 represents the decimal number as
In general, in both systems, we have an integer part to the left of the decimal point and we
have a fraction part to the right of the decimal point.
=11.1875
13.
In digital computers,the smallest unit of meaningful information is called a word. A word is
made up of a sequence of binary digits (bits), each representing either 0 (OFF) or 1 (ON).
Depending on the architecture of the computer, words may be 8, 16, 32, or 64 bits long, and
numbers are typically stored within one or more words.
Since digital systems are built from components that operate in two states (ON/OFF), all
numbers and data must be expressed in the binary (base-2) system. While integers can be
represented in binary directly, real numbers (fractions, very large values, and very small
values) require a more sophisticated system of representation. This is where floating-point
representation is used.
1.3.1 Floating Point Representation
14.
What is Floating-PointRepresentation?
Floating-point representation is a method of expressing real numbers (numbers with
fractional parts) in computers. Instead of storing the number as a fixed sequence of digits, it is
represented in a form similar to scientific notation:
Sign bit (S): Determines whether the number is positive or negative.
Mantissa (or significand, M): Represents the significant digits of the number.
Exponent (E): Scales the mantissa by a power of two, allowing representation of very
large or very small values.
16.
For example, indecimal scientific notation,
In binary floating-point, a similar concept is applied, but the base is 2 instead of 10.
Why Use Floating-Point Representation?
1.Wide Range: It allows computers to represent extremely large numbers (like ) and
extremely small numbers (like ) in the same system.
2.Fractional Values: It enables representation of real numbers with fractional parts (e.g.,
3.14159).
3.Standardization: The IEEE 754 standard defines how floating-point numbers are stored
and computed, ensuring consistency across computing platforms.
17.
Example:
Let’s represent thedecimal number −5.75.
1.Convert to binary:
2.Normalize:
3.Encode in IEEE 754:
1. Sign = 1 (negative)
2. Exponent = → 10000001
3. Mantissa = 01110000000000000000000
So the final 32-bit word is:
1 | 10000001 | 01110000000000000000000
Example: Conversion of11.1875 to Binary
Step 1 – Integer Part (11)
•11 ÷ 2 = Quotient 5, Remainder 1 →
•5 ÷ 2 = Quotient 2, Remainder 1 →
•2 ÷ 2 = Quotient 1, Remainder 0 →
•1 ÷ 2 = Quotient 0, Remainder 1 →
✔ Read remainders from bottom to top:
Step 2 – Fractional Part (0.1875)
•0.1875 × 2 = 0.375 → Integer part = 0 →
•0.375 × 2 = 0.75 → Integer part = 0 →
•0.75 × 2 = 1.5 → Integer part = 1 →
•0.5 × 2 = 1.0 → Integer part = 1 →
✔ Read integer parts in order:
Final Result
20.
1.4 Error Estimation
Inany numerical analysis, errors will arise during the calculations. To be able to
deal with the issue of errors, we need to
A.Identify where the error is coming from (“is it round off or truncation?”),
followed by
B.Quantifying the error (“what is this?”), and lastly
C.Minimize the error as per our needs (“how about increasing the step
size?”).
This section is devoted to addressing what we have stated under (B).
1.4.1 True Error
True error, denoted by is the difference between the true value (also called the
exact value) and the approximate value.
21.
The magnitudeof true error does not show how bad the error is. That means it
actually depends on the mathematical equation that describes a given quantity.
Relative true error is defined as the ratio of the true error and the true value
This value could be expressed as percentage value as follows
Sometimes it would give more sense if we use the absolute relative true error
22.
1.4.2 Approximate Error
Sofar, we discussed how to calculate true errors. Such errors are calculated
only if true values are known. In most cases we will not have the luxury of
knowing true values. So, when we are solving a problem numerically, we will
only have access to approximate values. We need to know how to quantify error
for such cases.
Approximate error is denoted by and is defined as the difference between the
present approximation and previous approximation.
Here again the magnitude of approximate error does not show how bad the
error is
23.
Relative approximate erroris denoted by and is defined as the ratio between the
approximate error and the present approximation
Similar to relative true error we will have approximate error in percentage as well
as an absolute value of relative approximate error.
24.
Example: A studentconducts an experiment and estimates the resistance of a
thermistor to be 10 ohms, while the true value from the datasheet is 15 ohms.
Using the given information, compute: The True Error, The Relative True Error
in decimal and percentage form, The Absolute Relative True Error







![1.2.2. Truncation Error
Truncation error is defined as the error caused by truncating a mathematical
procedure. For example, the Maclaurin series for is given as
This series has an infinite number of terms but when using this series to
calculate only a finite number of terms can be used on iteration. For example,
if one uses three terms in his calculation, then the resulting truncation error
becomes
2 3
x x x
e 1 x ...
2! 3!
3
2 4
x x x
x
Trunction Error=e -[1+x+ ]= + ...
2! 3! 4!
](https://image.slidesharecdn.com/chapter1-260106123042-788d5184/85/Chapter-1-Computational-Method-Introduction-pptx-8-320.jpg)