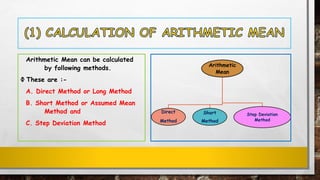
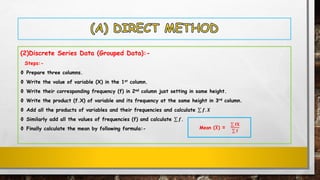
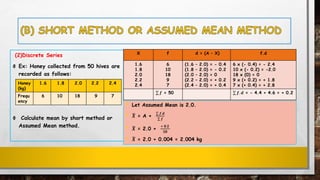
The document discusses various measures of central tendency and methods to calculate the arithmetic mean. It defines central tendency as a single value that describes a typical or average value in a data set. The three most common measures of central tendency are the mean, median, and mode. The document outlines different methods to calculate the arithmetic mean, including the direct method, short method, and step deviation method. It provides examples and step-by-step calculations for each method.

































![Measures of central_tendency._mean,median,mode[1]](https://cdn.slidesharecdn.com/ss_thumbnails/measuresofcentraltendency-200527065616-thumbnail.jpg?width=640&height=640&fit=bounds)





















































