Downloaded 89 times


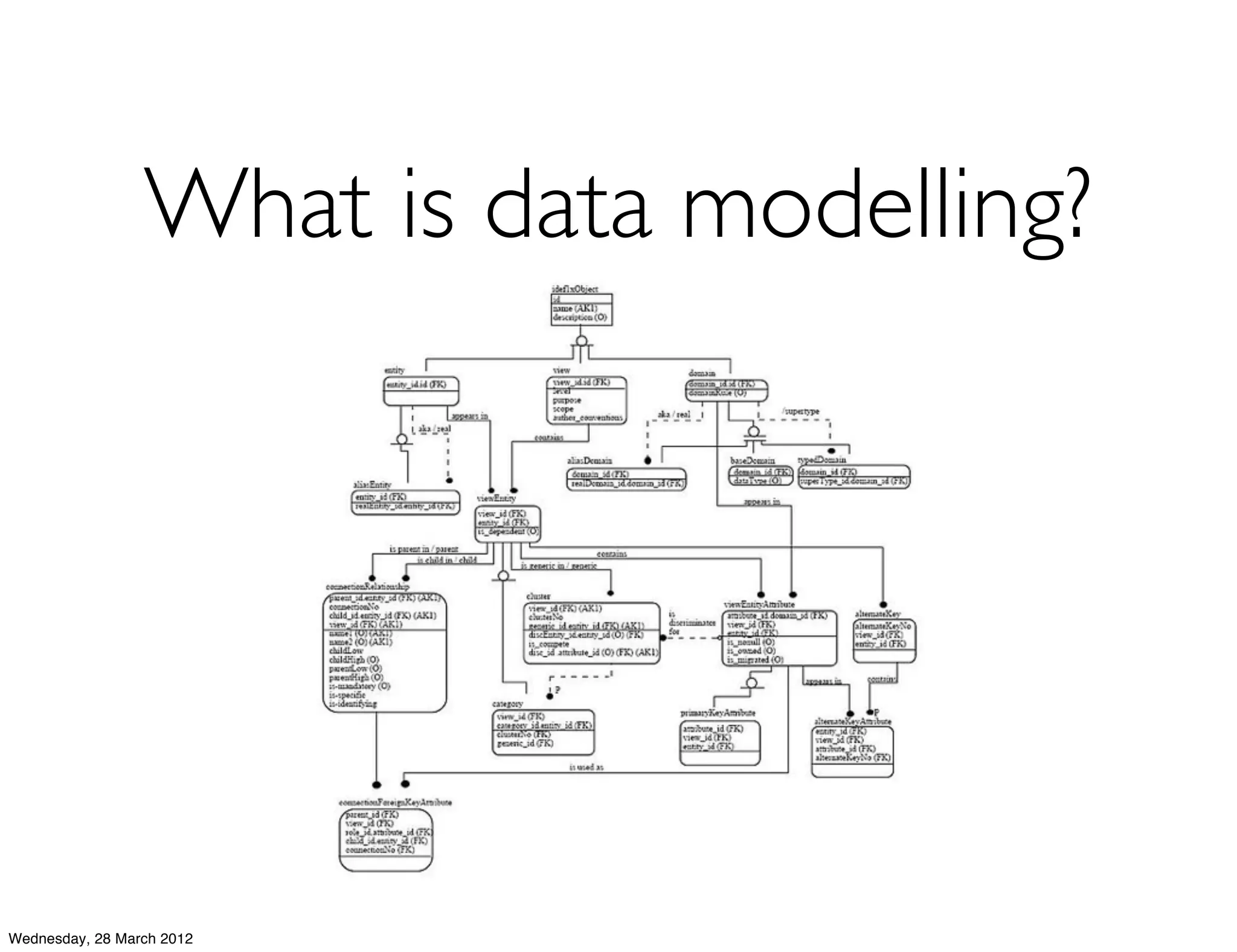







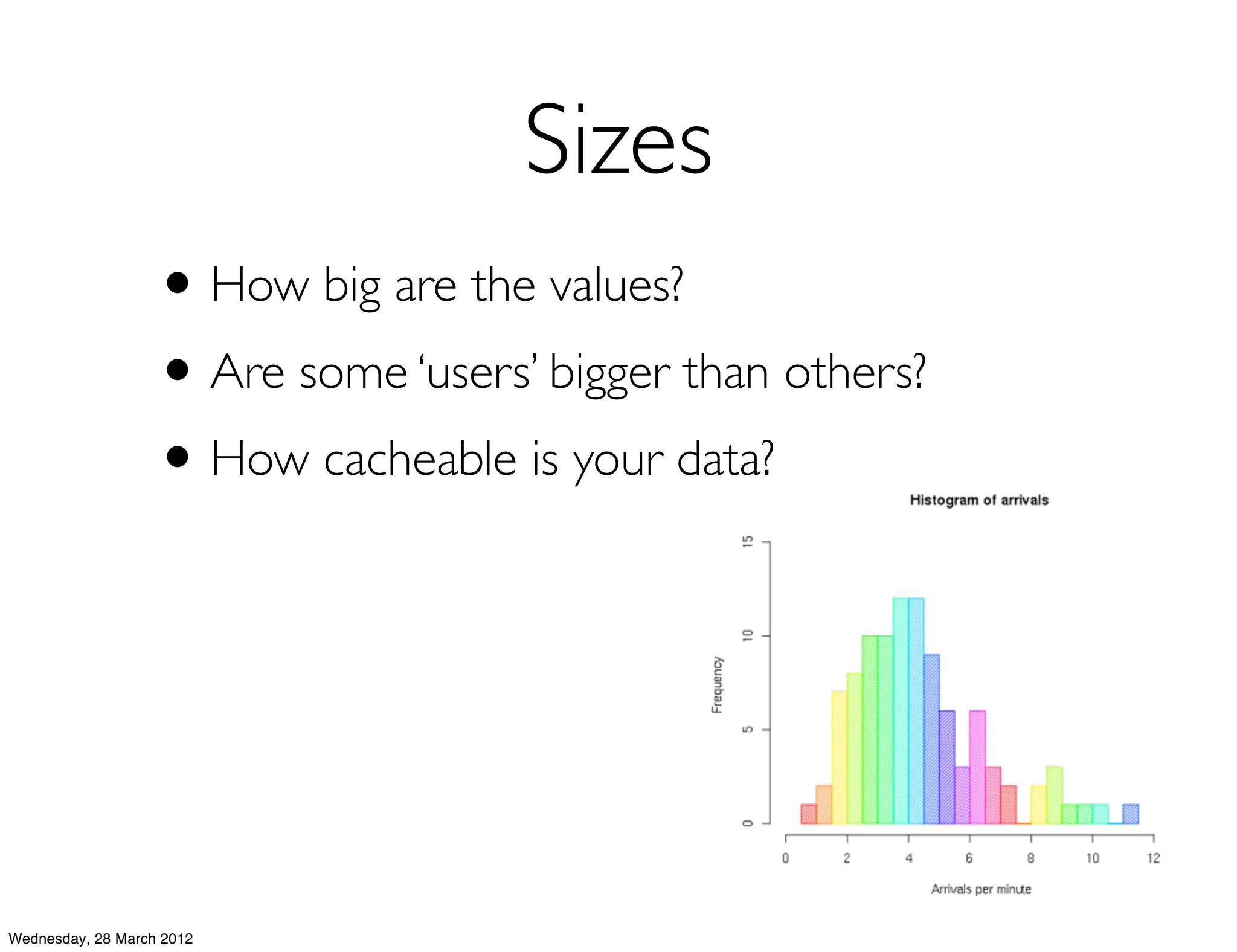


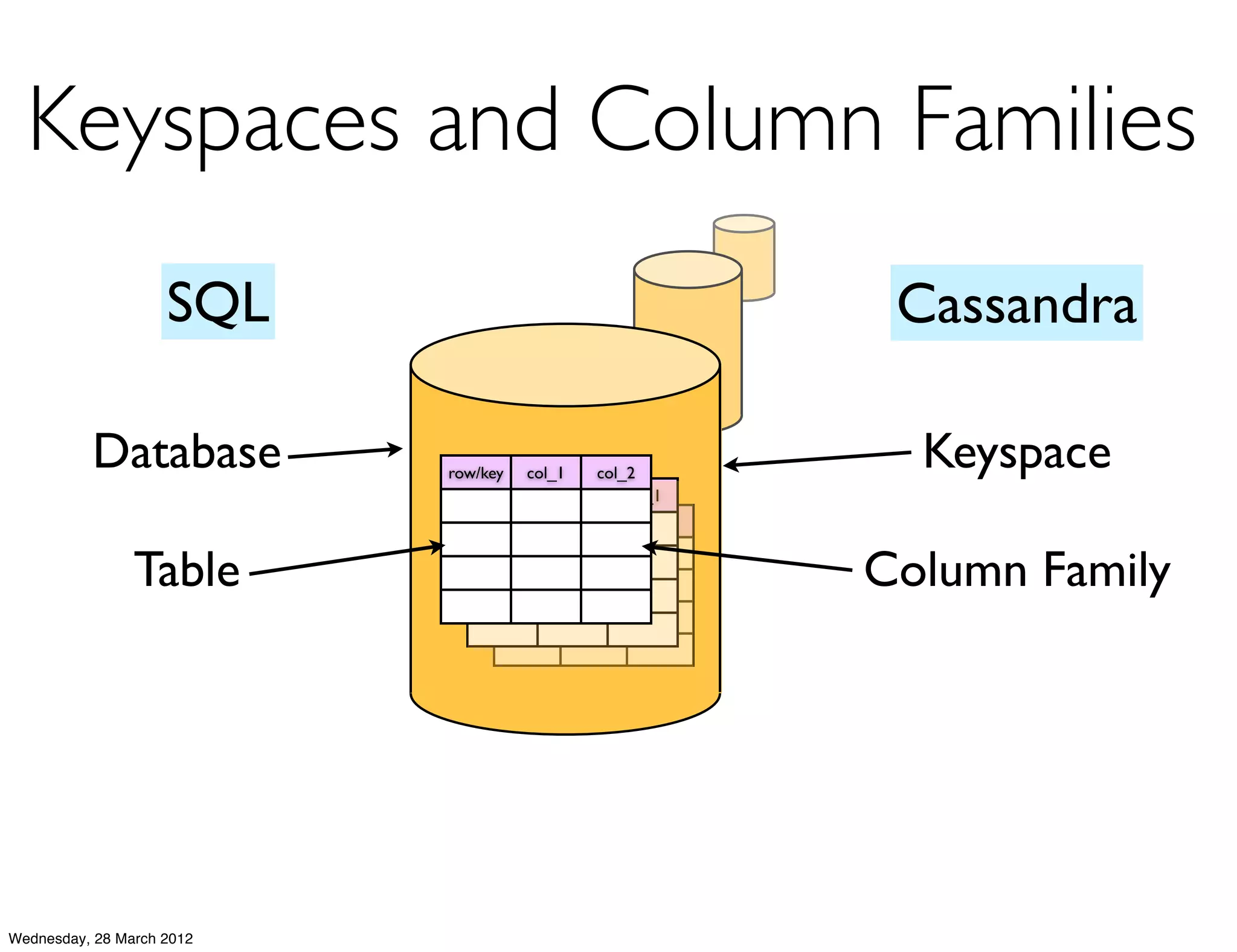








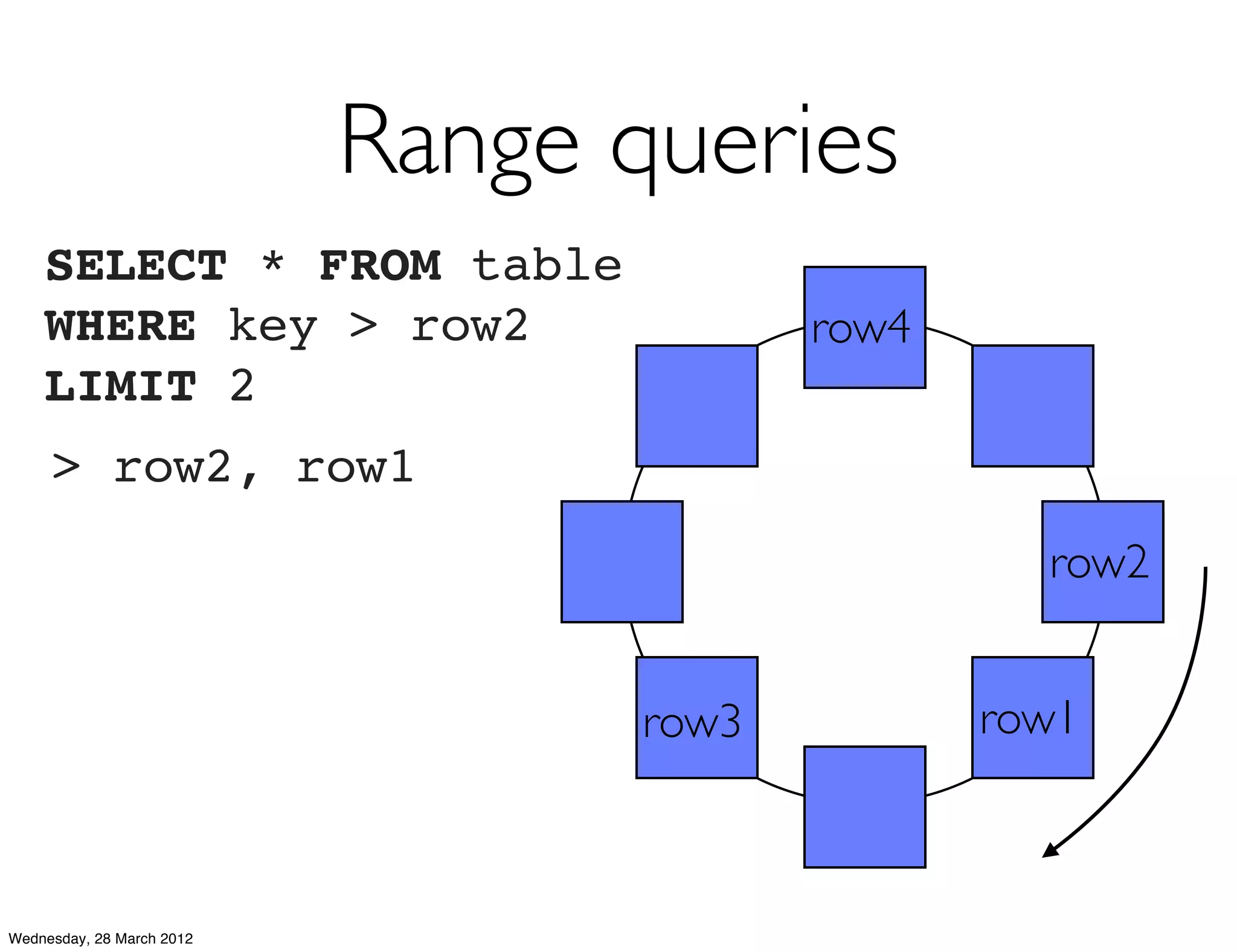








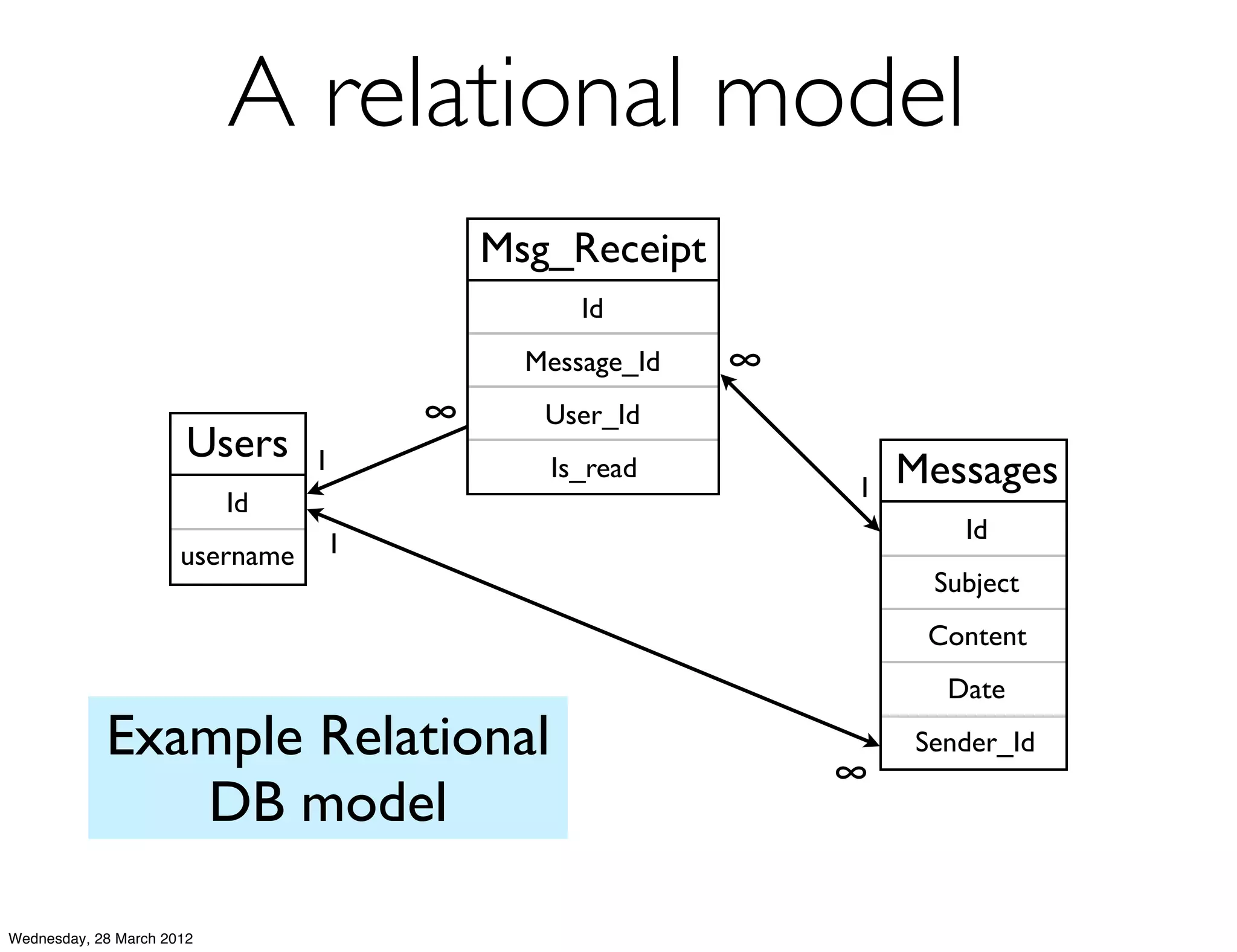

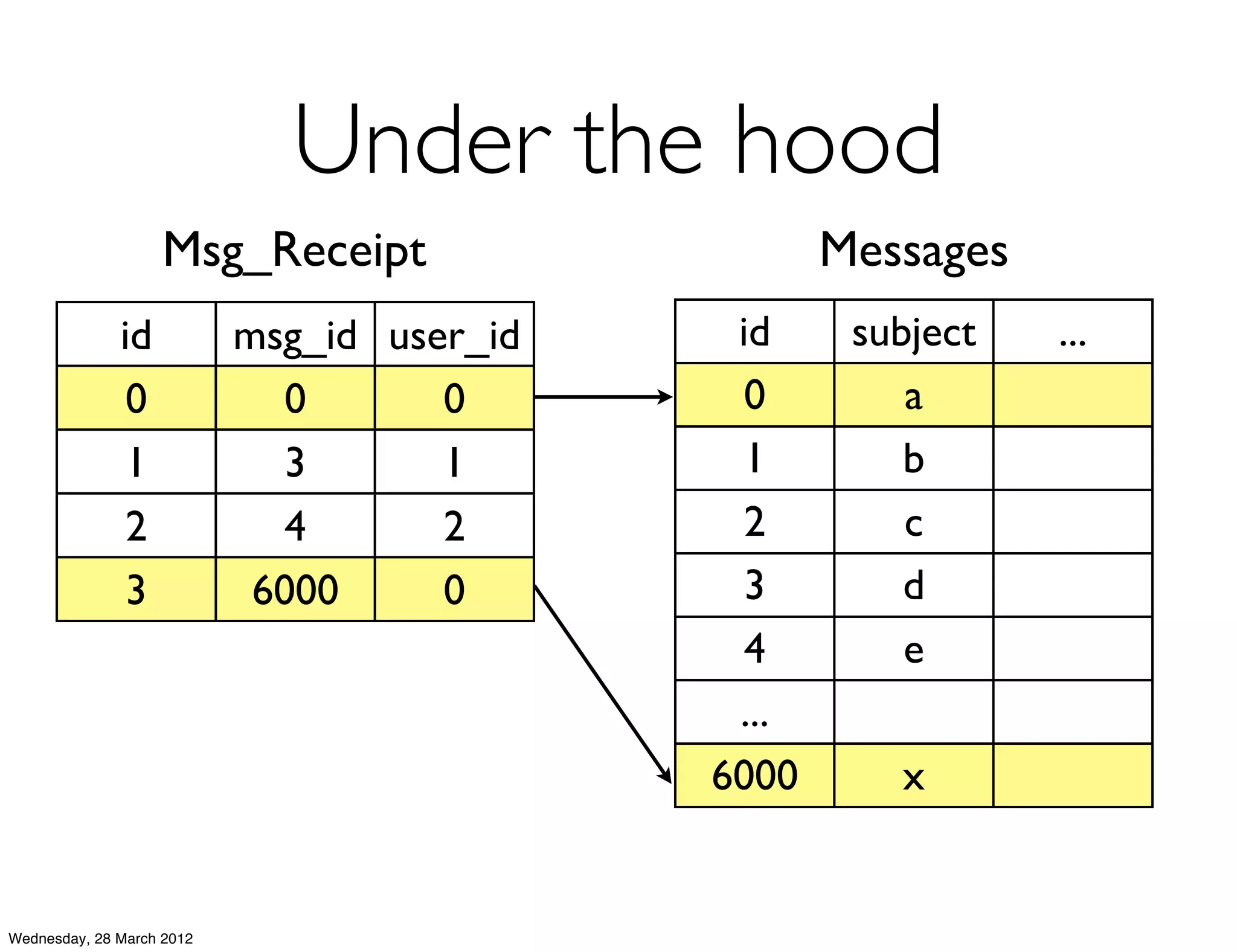





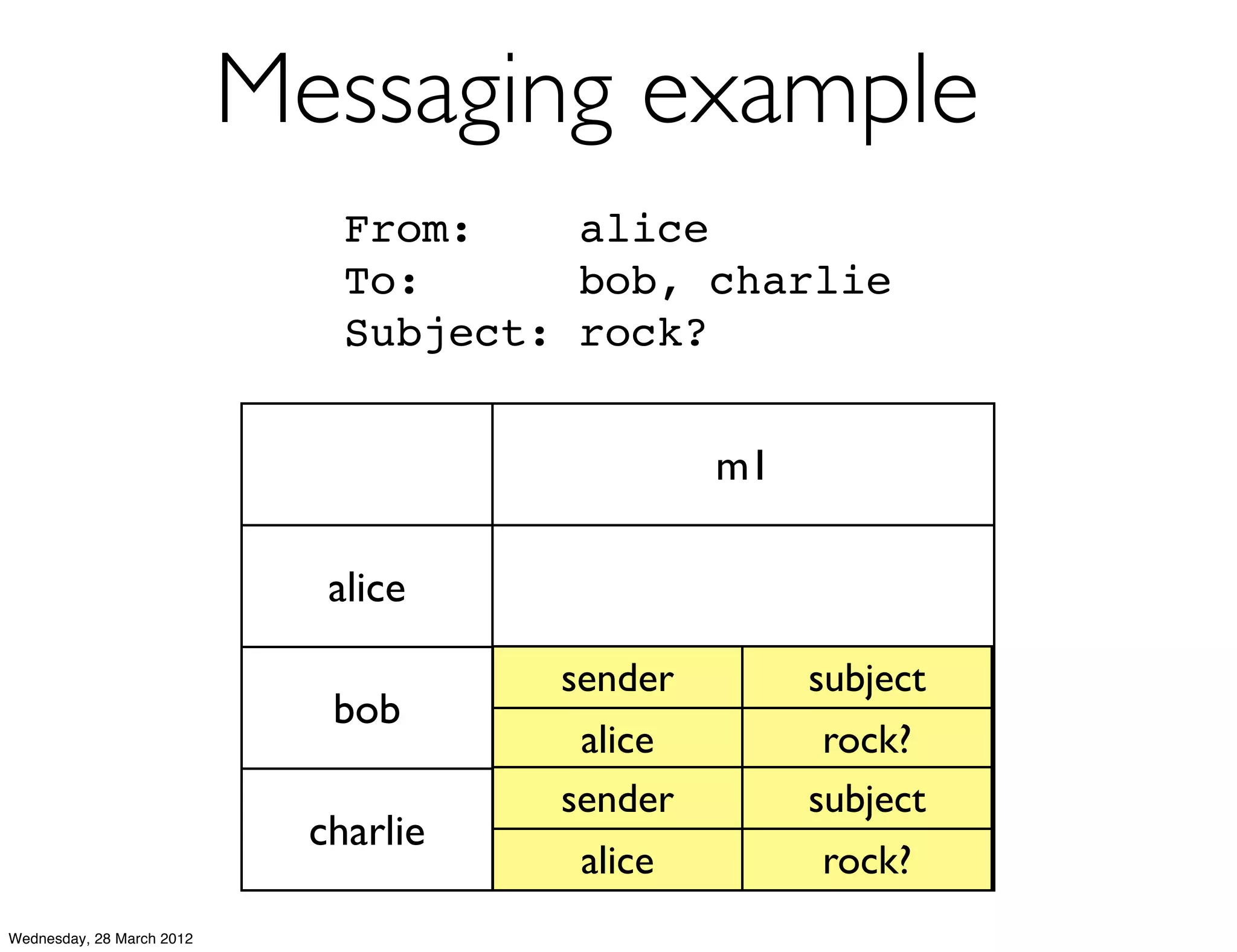
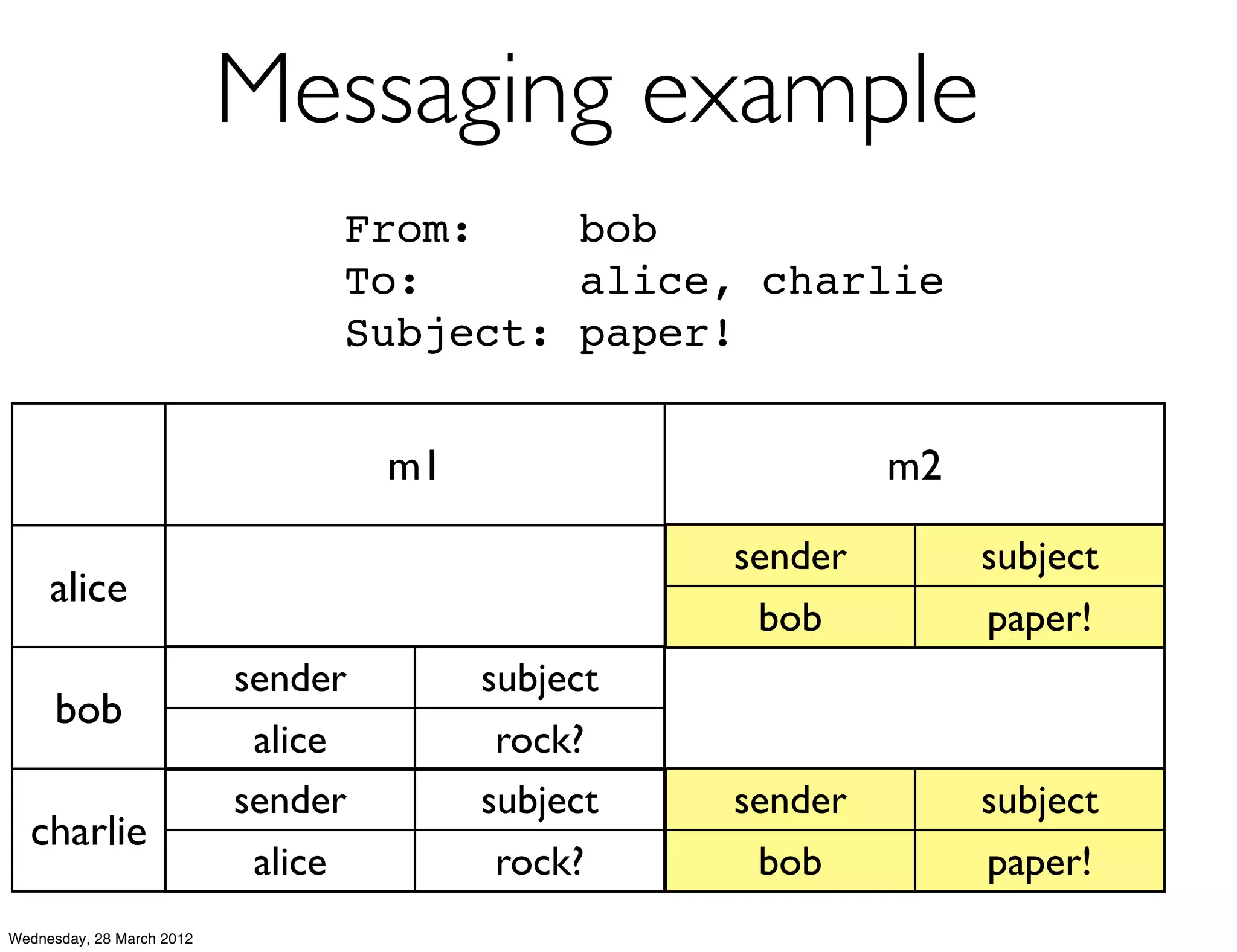



This document summarizes Richard Low's upcoming data modeling workshop. The workshop will cover what data modeling is, factors to consider when designing a data model like workload and queries, modeling options in Cassandra like rows and columns, and tools like counters and secondary indexes. It provides an example of modeling a scalable messaging application and compares it to a relational database model. The workshop aims to help attendees optimize their data for common queries and operations.



































































