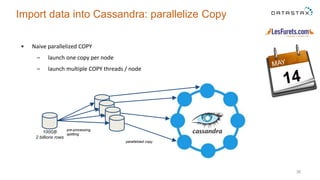
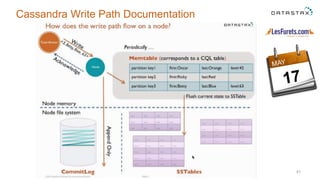
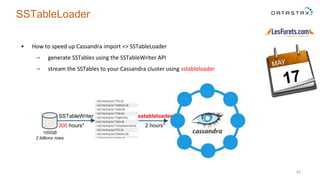
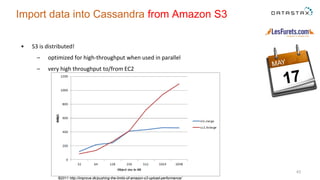
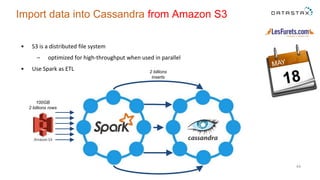
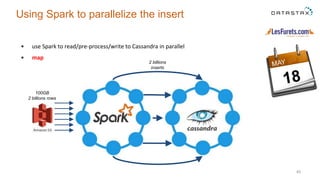
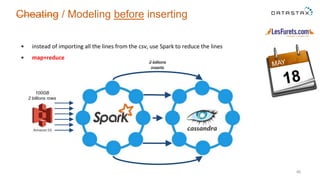
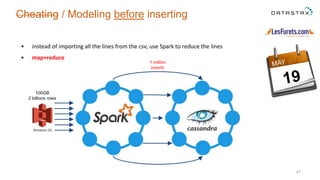
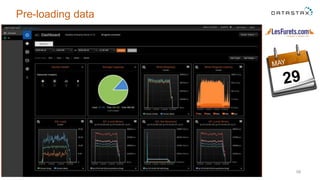
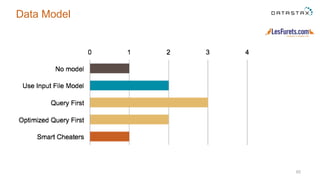
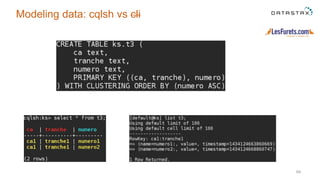
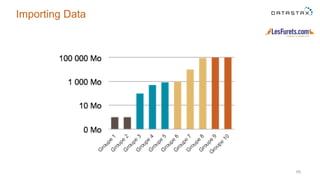
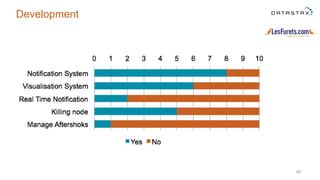
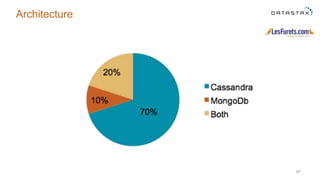
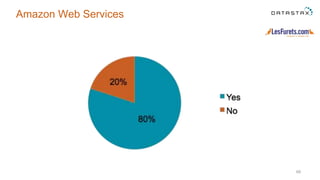
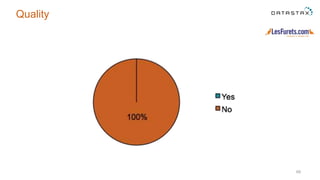
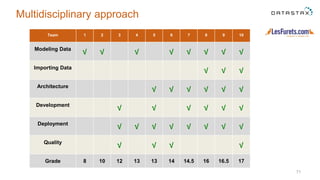
The document outlines a project focused on using Cassandra on AWS to develop a tsunami alerting system within 30 days as part of a master's level big data management course. It details the process of choosing technologies, modeling data, and importing large datasets from various sources while addressing challenges related to deployment and data processing. Overall, it emphasizes a multidisciplinary approach, team collaboration, and practical learning experiences in handling big data applications.